







摘要
用于通用目的文本匹配的神经网络方法,一个用于用于序列间对齐方法的文本匹配模型,只需要保持三个关键特征:原始点乘特征、先前的对齐特征和上下文特征,同时简化所有剩余的组件。我模型在参数较少的所有数据集上的性能与最新水平不相上下,推理速度比同类模型快至少6倍。
介绍
两个文序列的语义对齐和比较是神经文本匹配的关键。更加有效地模型可以通过多个序列间对齐层来建立,而不仅仅只是通过单一的对齐过程中的比较结果来做出预测,具有多个排列层的叠层模型保持其中间状态,并逐渐细化其预测结果。
本匹配方法中存在的许多慢成分的必要性提出了质疑,包括复杂的多向对齐机制、对齐结果的大量提取、外部句法特征或在模型深入时连接堆叠块的密集连接。这些设计选择大大降低了模型的速度,并且可以用更轻、更有效的设计来代替。同时,我们强调了一个有效的文本匹配模型的三个关键组成部分。这些成分,名称RE2代表,是先前的对齐特征(残差向量)、原始点方向特征(嵌入向量)和上下文特征(编码向量)。
RE2的总体架构如图1所示。嵌入层首先嵌入散列标记。由编码层、对齐层和融合层组成的多个相同结构的块依次处理序列。这些块通过剩余连接的增强版本进行连接。池化层将序列表示聚合为向量,这些向量最终由预测层处理以给出最终预测。每个层的实现都尽可能简单,整个模型作为一个组织良好的组合,同时也是非常强大和轻量级的。

模型方法
1) 通过增加的剩余连接连接。在每个块中,序列编码器首先计算序列的上下文特征(图中的实心矩形)。编码器的输入和输出被连接起来,然后输入到一个对齐层中,以模拟两个序列之间的对齐和交互作用。融合层融合对准层的输入和输出。融合层的输出被视为该块的输出。最后一个块的输出被发送到池层,并转换为固定长度的向量。预测层以这两个向量作为输入,预测最终的tar值。通过优化交叉熵损失来训练分类任务中的模型。
每一层的实现都尽可能简单,模型在嵌入层只用了单词嵌入,没有字符嵌入或者句法特征,编码器采用具有相同填充的通用多层卷积网络,循环神经网络速度较慢,不会导致进一步的改进,因此这里不采用它们。池化层使用最大超时池化操作。
2.1
为了为对齐过程提供更丰富的特性,RE2采用了残差连接的增强版本来连接连续的块。在增强剩余连接的情况下,对齐融合层的输入包括三个部分,即原始点特征(嵌入向量)、先前块处理和细化的先前对齐特征(残差向量)和来自编码器层的上下文特征(编码向量)。这三个部分在文本匹配过程中都起着补充作用。
2.2对齐层
对齐层采用两个序列作为输入并计算对齐表示作为输出。第一个序列输入为a集合,第二个序列输入作为b,相似性分数用点击方式求得。
eij = F (ai)T F (bj ).
F是一个恒等函数或者一个单层前馈神经网络,该选项被视为超参数。
输出向量a和b是通过另一个序列的表示的加权和来计算的。求和通过当前位置与另一序列中相应位置的相似度得分加权:
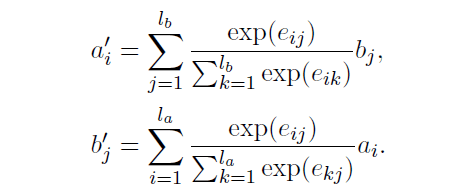
2.3 ‘预测层
’预测层是把池化层输出的两个序列向量v1和v2作为输入去预测最后的目标值。















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









