







原文链接:https://aclanthology.org/P19-1465.pdf
2019 ACL
介绍
问题
作者认为之前文本匹配模型中序列对齐部分,过于复杂。只有单个inter-sequence alignment层的模型,常会引入外部信息(例如语法特征)作为额外输入,或是使用复杂的对齐机制,或是对对齐后的结果建立大量的后处理层。包含多个inter-sequence alignment层的模型,使用dense net或递归网络进行连接,导致低层的特征可能无法进行充分的传播以及梯度消失的问题。最近的一些工作提出将这些堆叠blocks进行connect 来增强低层特征,并生成比单一对齐模型更好的结果。
IDEA
因此作者对文本匹配方法中速度非常慢的部分(比如复杂的多方式对齐机制、外部语义特征等)存在的必要性进行思考,这些设计大大降低了模型的速度,考虑使用更轻巧并同样有效的设计来进行替代。作者认为文本匹配模型中RE2(残差向量、embedding向量以及encoded向量)是关键部分不进行化简,其余部分都应该尽可能的简单以保持模型具有较快的速度以及更好的表现。
方法
作者提出的RE2模型大致结构如下图所示(右边部分与左边一致,分别输入两个序列):首先每个序列中的token首先在embedding层中进行编码,然后传入到连续的N个同结构的blocks中(也就是图中虚线框部分)。在每一个block内,先使用一个序列编码器来获得上下文信息(图中实心长方形),将encoder的输入以及得到的输出进行concatenate后传入到alignment layer,来对两个序列的交互和alignment进行建模,然后将alignment层的输入和输出使用fusion层进行融合。第N个模块中fusion的输出经过pooling层得到长度合适的向量,最后使用这两个序列的向量对它们之间的关系进行预测。
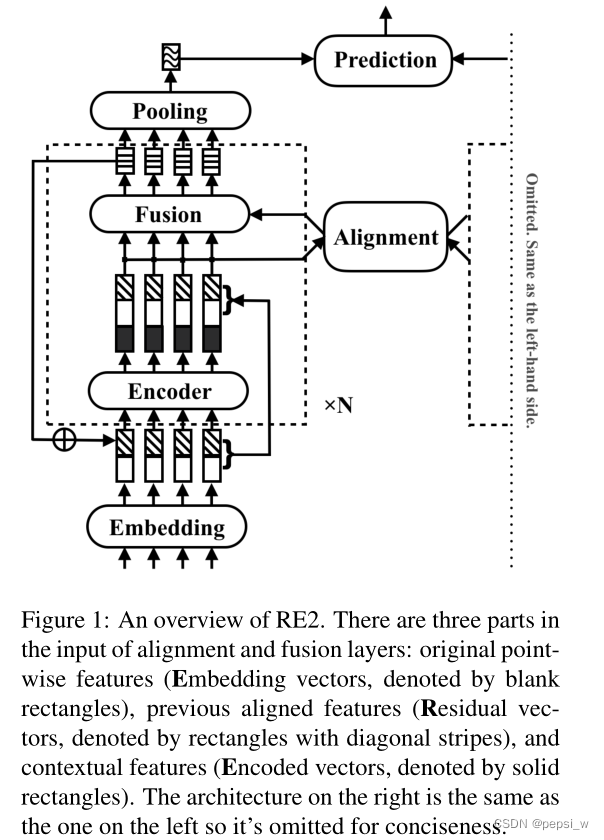
Augmented Residual Connections
作者这里采取的是一个增强的残差连接(其实就是把序列经过embedding层得到的向量,传入每个block块中)。
。具体的,第n个block的输入输出分别表示为:![]()
![]() ,
,定义为0向量。 在第一个块中,直接将序列经过embedding后的向量(也就是
)作为encoder的输入,第i(i>1)块中,都是将序列经过embedding后的向量与前两块的输出进行concat。
![]()
这样输入alignment层和fusion层的就有三部分,一个是一直不变的原始点状特征(embedding vector),一个是之前块处理后的aligned特征(residual vectors),以及encoder层得到的上下文特征(encoded vector)
Alignment Layer
alignment layer将两个序列的特征(表示为a,b)作为输入,然后计算aligned表征作为输出。ai和bi之间的相似度由投影后向量的点积表示:
![]()
F是一个实体函数或者一层前馈神经网络,该选择作为模型的超参数。
输出a和b由当前位置与另一序列相应位置之间的相似分数进行加权求和得到。
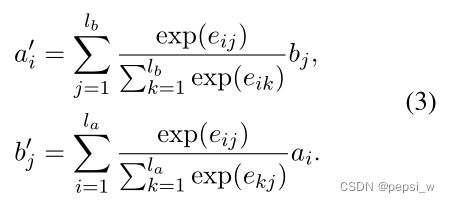
ps:这里跟ESIM的Local Inference模块几乎一模一样,就是对ai增加了一个函数而已。
Fusion Layer
fusion层从三个角度对本地和对齐的表征进行比较,然后将它们融合在一起。该层输出公式为:
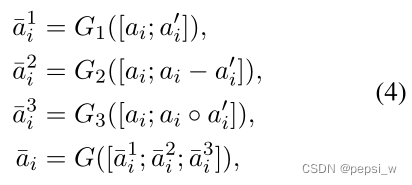
G表示单层的前馈神经网络,向量之间相减突出它们之间的差异,相乘突出其相似性。
Prediction Layer
该层将两个序列的向量表征v1、v2作为输入,对使用以下函数进行预测:
![]()
H是一个多层的前馈神经网络。y^表示所有类别的预测分数(没有进行标准化),在分类任务中选择分数最大的类别进行输出,回归任务中y^是一个区间值。
另外在语义识别类的语义任务中,使用以下公式:
![]()
作者还提供了一个简化版:
![]()
这里预测函数公式的选择也作为超参数。
实验
各个数据集上的表现
在SNLI数据集上与其他模型进行对比实验,结果如下:
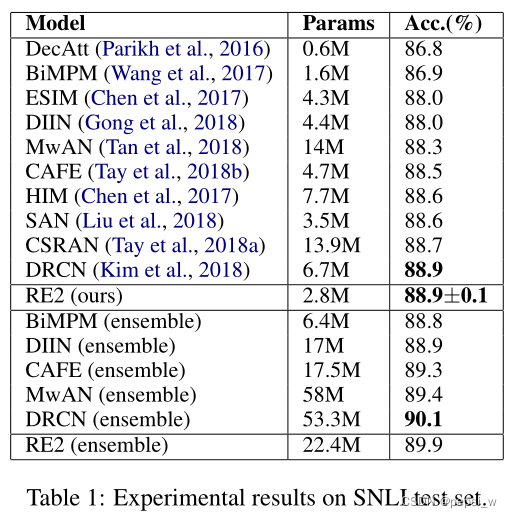
ensemble版本是使用8个不同随机种子的训练模型,通过投票来得到最后的结果。作者提出的模型在单一模型中达到了最好的效果,在ensemble模型中在更少参数量的情况下表现出比较好的精度。
在Scitail数据集上进行实验,结果如下:
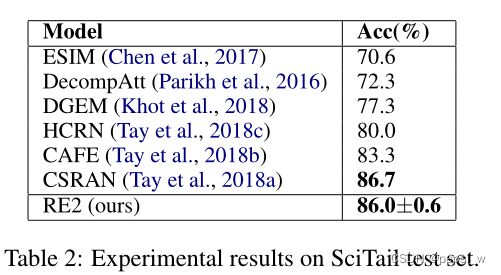
可以看到作者提出的模型与最好的结果非常接近。作者认为该数据集由于训练数据比较少(仅为SNLI的4%),所以导致整体的精度比起二分类问题都要低一些。
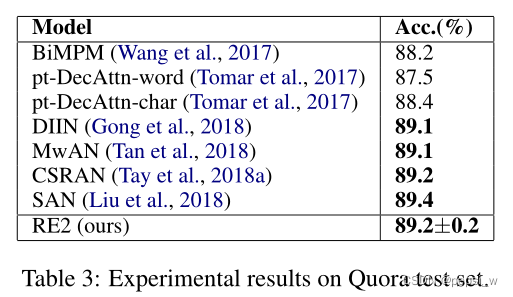
在Quora数据集上的实验结果如下图所示,可以看出作者提出的模型达到了最好效果。
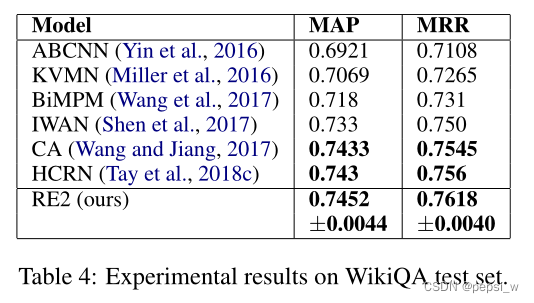
在答案选择任务的数据集WikiQA上的实验结果如下图所示(在超参数调整中,作者根据WikiQA开发集的MRR选择最佳的超参数 ):
时间性能
作者将模型的预测时间进行了对比,结果如下:

作者只对3个block块以内的RE2模型进行了实验,可以看出即使作者提出的模型使用了多个stacked blocks,但在CPU上的推理速度非常快,至少比DIIN快了17倍,从前面的实验可知与速度相当的BiMPM和CAFE相比,我们的模型具有更高预测分数。
消融实验
enc-in表示之间将encoder的输出作为alignment和fusion的输入,即只有黑色矩形那部分。residual conn即不再对残差连接进行增强。simple fusion表示使用和
concate作为输入,即
.
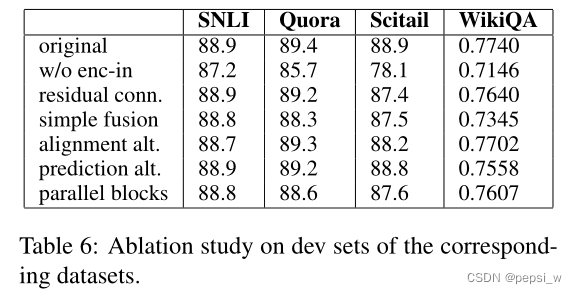
可以看出不将encoder的输入进行concat往后传递(作者说的是,输入alignment的特征不够丰富),对整个模型的影响都挺大的。
作者还对block以及encoder的数量进行了实验,对block数量进行改变时,encoder层为2,对encoder layers改变时,保持block2为2。
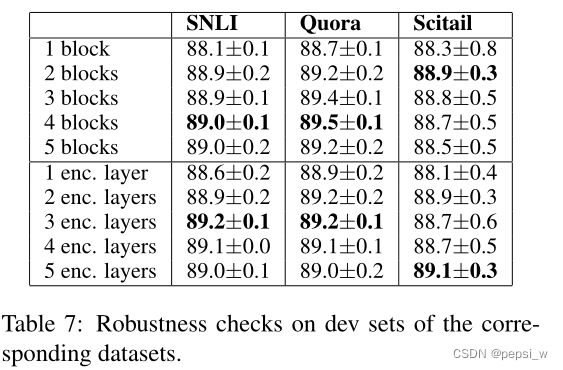
我们可以从表中看到,较少的块或层可能是不够的,但增加超过必要的块或层对性能影响也不大。
作者对该模型中三个关键向量进行了occlusion sensitivity分析(类似于计算机视觉中的闭塞敏感性分析)。在某一个block中将其中一个特征进行mask为0,然后得到以下三个任务上的精确度。实验结构如下:

第一个区块中没有以前的对齐特征,因此留有空白。编码器的输出所代表的上下文特征,在预测entailment关系时是不可或缺的,因此在mask enc-out后,精确度会下降;在2b和2c中,可以看出缺少之前的align特征和残差向量,会导致模型在预测中性、矛盾关系时表现出明显的下降。
可视化
为了了解SNIL数据集中的序列对(premis为“A green bike is parked next to a door”,hypothesis为“The bike is chained to the door”)在每个block的对齐结果在作者提出的堆叠结构中是如何演变,对第个block和最后一个block的alignment layer中注意力分布(公式3中的归一化eij)的进行可视化。结果如下:
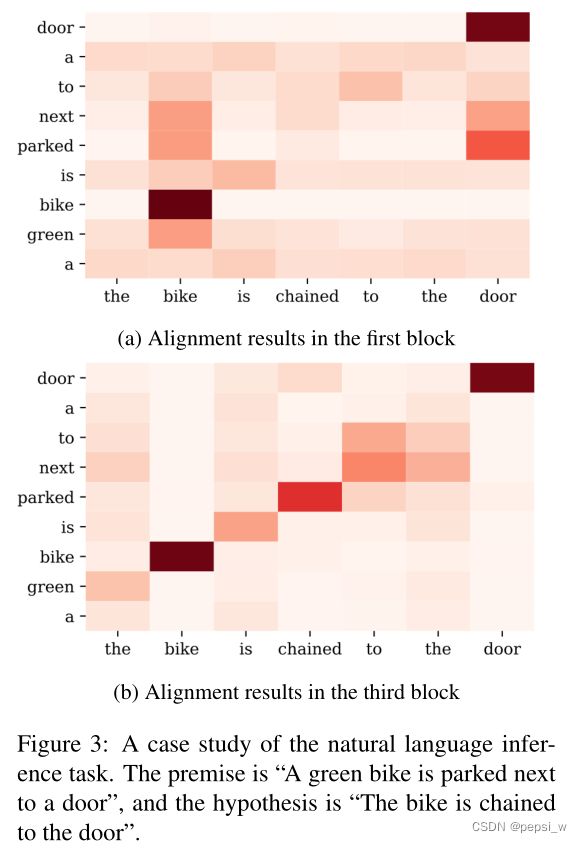
在第一个块中,对其结果几乎是单词或者短语级别的,parked、next与bike、door最相关,parked和chained之间的联系比较弱。在最后一个block中,对齐结果就会整个句子的语义以及结构,所以parked和chained的联系就很强烈,有了正确的对齐方式,该模型就能知道,尽管premise中的大多数部分都包含hypothesis中的对齐部分,但 "parked "并不包含 "chained",所以它正确地预测了两个句子之间的关系是中立的。我们的模型将低级别的对齐结果作为中间状态,并逐渐将其细化为高级别的对齐结果。
总结
本文对于普通的文本匹配任务提出了一个高效的模型RE2,在具有较快速度的同时也拥有较高的准确率。该模型主要强调了三个关键特征(Residual vectors、Embedding vectors、Encoded vectors),并简化了其他部分。
整个模型较为简单,作者尽可能的减少参数与计算,embedding直接对word进行编码而不是对字符进行编码,也没有引入外部信息,encoder也是使用一个简单的CNN结构来获取上下文信息。
该论文与ESIM比较相似,不过这里通过残差连接了堆叠块的信息,而且使用CNN而不是BiLSTM来提取上下文信息。















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









