







本篇博客主要介绍了,使用LFW数据集测是dlib模型准确率的过程。是一个小白入门的介绍,大神可自行绕过。
LFW概述
1. 人脸检测测试数据库:
fddb:http://vis-www.cs.umass.edu/fddb/
2. 人脸识别测试数据库:
lfw:http://vis-www.cs.umass.edu/lfw/#views
3. LFW(人脸比对数据集)
无约束自然场景人脸识别数据集,该数据集由13000多张全世界知名人士互联网自然场景不同朝向、表情和光照环境人脸图片组成,共有5000多人,其中有1680人有2张或2张以上人脸图片。每张人脸图片都有其唯一的姓名ID和序号加以区分。
LFW数据集主要测试人脸识别的准确率,该数据库从中随机选择了6000对人脸组成了人脸辨识图片对,其中3000对属于同一个人2张人脸照片,3000对属于不同的人每人1张人脸照片。测试过程LFW给出一对照片,询问测试中的系统两张照片是不是同一个人,系统给出“是”或“否”的答案。通过6000对人脸测试结果的系统答案与真实答案的比值可以得到人脸识别准确率。
这个集合被广泛应用于评价 face verification算法的性能。
13233 images
5749 people
1680 people with two or more images
4. 技术报告(lfw technical report):
http://vis-www.cs.umass.edu/lfw/lfw_update.pdf
5. 测试过程概述
通过dlib进行人脸识别网络训练后,得到dlib_face_recognition_resnet_model_v1.dat。通常大家在LFW人脸数据集上对该模型进行精度验证。以下梳理验证过程:
(1) 在原始LFW数据集中,截取人脸图像并保存。(例如:可以使用开源人脸检测对齐seetaface将人脸crop出来,并 保存,建议以原图像名称加一个后缀命名人脸图像)
(2) 通过python,matlab,或者C++,构建训练时的网络结构并加载dlib_face_recognition_resnet_model_v1.dat。
(3) 将截取的人脸送入网络,每个人脸都可以得到网络前向运算的最终结果,一般为一个N维向量,并保存,建议以原图像名称加一个后缀命名。
(4) LFW提供了6000对人脸验证txt文件,lfw_pairs.txt,其中第1个300人是同一个人的两幅人脸图像;第2个300人是两个不同人的人脸图像。按照该list,在(3)保存的数据中,找到对比人脸对应的N维特征向量。
(5) 通过cosine距离/欧式距离计算两张人脸的相似度。同脸和异脸分别保存到各自对应的得分向量中。
(6) 同脸得分向量按照从小到大排序,异脸向量按照从大到小排序。
(7) FAR(错误接受率)从0~1,按照万分之一的单位,利用排序后的向量,求FRR(错误拒绝率)或者TPR(ture positive ratio)。
(8) 根据7可绘制ROC曲线。
6. 阈值确定
(1) 将测试人脸对分为10组,用来确定阈值并验证精读。
(2) 自己拟定一个人脸识别相似度阈值范围,在这个范围内逐个确认在某一阈值下,选取其中1组数据统计同脸判断错误和异脸判定错误的个数。
(3) 选择错误个数最少的那个阈值,用剩余9组,判断识别精度。
(4) 步骤(2)和(3)执行10次,将每次(3)获取的精度进行累加并求平均,得到最终判定精度。
其中也可以用下述方式替换
自己拟定一个人脸识别相似度阈值范围,在这个范围内逐个确认在某一阈值下,针对所有人脸对统计同脸判断错误和异脸判定错误的个数,从而计算得出判定精度。
LFW中的 pairs.txt
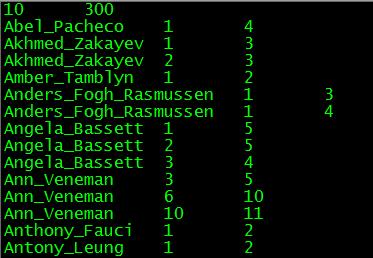
第一行:300表示的是300个匹配图片(相同的人),10表示的是重复十次
Abel_Pacheco 1 4 表示这个文件夹的Abel_Pacheco_0001.jpg 和Abel_Pacheco_0004.jpg
300行以后 开始不匹配图片
一共重复10次构成完整的pairs.txt,因此一共3000 mached, 3000个no_mached
得出准确率的思路就是:(正确判断出 matche的次数+正确判断 no_mached的次数) / 6000
代码
鉴于有很多网友私信问我,pairs.txt 怎么生成,我将最初自己的代码,上传到了 github,希望能给初学者以参考和帮助。因为也过去几年了,已经从上家公司离职,完整的代码是没有的,存在只是自己原来的一点思路和草稿,经过今天的一番整理,还能用,就先传上去了。需要改进的小伙伴,自行优化吧。哈哈。
项目地址: https://github.com/jobbofhe/lfw_generate_pairs.git

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









