









 本文介绍了一种并行处理场景中的任务分发与执行机制,包括任务的拆解、分配、执行及结果收集过程。通过C语言实现了一个简单的任务分发者、执行者和收集者模型,详细解释了各个组件的功能与交互流程,以及如何通过ZMQ库进行通信。实验结果显示,随着执行者数量的增加,系统响应时间显著减少。
本文介绍了一种并行处理场景中的任务分发与执行机制,包括任务的拆解、分配、执行及结果收集过程。通过C语言实现了一个简单的任务分发者、执行者和收集者模型,详细解释了各个组件的功能与交互流程,以及如何通过ZMQ库进行通信。实验结果显示,随着执行者数量的增加,系统响应时间显著减少。
举一个例子,在并行处理中的一个经典情形。一个任务分发者拆解任务并进行分配,很多执行者领取任务然后执行,最后执行者将结果发送给一个收集者。见下图:
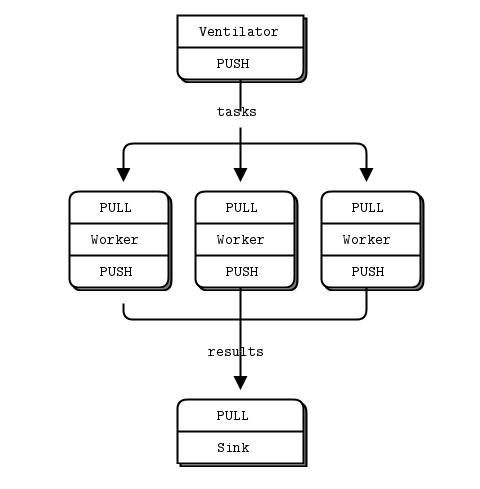
- 最上面是产生任务的 分发者 ventilator
- 中间是执行者 worker
- 下面是收集结果的接收者 sink
任务分发者首先给接受者sink发送“0”表示开始处理,然后给执行者发送一个休眠时间代表它的工作负载。
// Task ventilator
// Binds PUSH socket to tcp://localhost:5557
// Sends batch of tasks to workers via that socket
#include "zhelpers.h"
int main (void)
{
void *context = zmq_ctx_new ();
// Socket to send messages on
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_bind (sender, "tcp://*:5557");
// Socket to send start of batch message on
void *sink = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sink, "tcp://localhost:5558");
printf ("Press Enter when the workers are ready: ");
getchar ();
printf ("Sending tasks to workers…\n");
// The first message is "0" and signals start of batch
s_send (sink, "0");
// Initialize random number generator
srandom ((unsigned) time (NULL));
// Send 100 tasks
int task_nbr;
int total_msec = 0; // Total expected cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// Random workload from 1 to 100msecs
workload = randof (100) + 1;
total_msec += workload;
char string [10];
sprintf (string, "%d", workload);
s_send (sender, string);
}
printf ("Total expected cost: %d msec\n", total_msec);
zmq_close (sink);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}执行者简单的从分配者哪里拉取任务,根据任务休眠时间休眠。然后它简单的向收集信息的sink发送结果,周而复始。
// Task worker
// Connects PULL socket to tcp://localhost:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://localhost:5558
// Sends results to sink via that socket
#include "zhelpers.h"
int main (void)
{
// Socket to receive messages on
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://localhost:5557");
// Socket to send messages to
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sender, "tcp://localhost:5558");
// Process tasks forever
while (1) {
char *string = s_recv (receiver);
printf ("%s.", string); // Show progress
fflush (stdout);
s_sleep (atoi (string)); // Do the work
free (string);
s_send (sender, ""); // Send results to sink
}
zmq_close (receiver);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}收集者sink接收到开始信号开始计时,在接收到100个任务结果后结束,并打印用时。
// Task sink
// Binds PULL socket to tcp://localhost:5558
// Collects results from workers via that socket
#include "zhelpers.h"
int main (void)
{
// Prepare our context and socket
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_bind (receiver, "tcp://*:5558");
// Wait for start of batch
char *string = s_recv (receiver);
free (string);
// Start our clock now
int64_t start_time = s_clock ();
// Process 100 confirmations
int task_nbr;
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
char *string = s_recv (receiver);
free (string);
if ((task_nbr / 10) * 10 == task_nbr)
printf (":");
else
printf (".");
fflush (stdout);
}
// Calculate and report duration of batch
printf ("Total elapsed time: %d msec\n",
(int) (s_clock () - start_time));
zmq_close (receiver);
zmq_ctx_destroy (context);
return 0;
}当我们开始1,2,或者4个执行者是,我们的到的结果是这样的。
1个执行者:total elapsed time :5034ms
2个执行者:total elapsed time :2421ms
4个执行者:total elapsed time :1018ms
然我们跟深入的谈下这些代码的细节:
- 该模型中执行者worker可以自由的进行扩容,分发者和收集者是一个固定的结果,而worker可以自由的调整。
- 我们必须同步执行者的批次起点。这在zeromq中是一个相当普遍的难题,没有简单的解决方案。zmq_connect方法执行需要时间,因此当一批执行者链接到分发者,第一个成功进行链接并且成功取得负载消息,在此期间其他的执行者也在链接。如果我们不同步批次同步会如何,这个系统将不能并行。试试去掉延时看看会发生什么。
- 假设分发者的PUSH socket分发任务给执行者均匀的(假设它们全部在开始前链接好)。这就是”load balancing”(负载均衡)。
- 收集者的PULL socket收集结果均匀,这就叫做”fair-queuing”(公平排队)
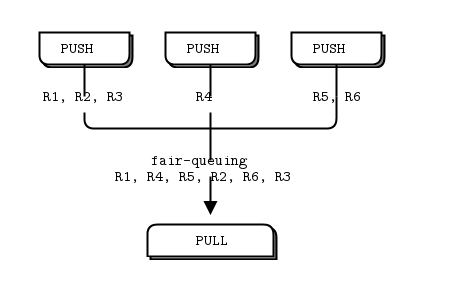
pipeline模式也展现出”slow joiner”特征,导致指责PUSH socket不具有负载均衡特性。如果你使用push pull模式,你的其中一个执行者比其他得到跟多的消息,那是因为该执行者的push socket有更快的接速度比其他的,如果你想适当的负载均匀,你可能要使用request-reply模式。
原文
这里写链接内容

















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









