






前言
每个高并发服务器往往面临与海量客户端创建并维护连接的场景。多进/线程模型会为每个连接创建一个进/线程,断开连接后销毁该进/线程。
然而,一个服务器能同时维护的进/线程受到文件描述符数量的限制。同时,过多的进/线程会导致占用大量系统内存资源,且创建并销毁进程或线程,以及在各进/线程之间切换,均会导致CPU计算以及上下文切换等性能开销。因此,需要一种资源复用模式,用一定数量的进/线程来处理海量的连接。
现有技术往往使用线程池的方式实现连接资源的复用。线程池是一组线程的集合,其中的线程在服务器启动之初(编译阶段)就被完全创建好并初始化,为静态资源。当服务器正式运行,开始处理来自客户端的连接时,可以直接从线程池中获取线程用于连接,无需动态分配。当处理完一个客户连接后,可以把线程放回池中,无需销毁线程,可供以后的连接再次使用。借此,线程池实现了线程复用,同一个线程可以处理多个连接的业务。
为了提高线程的使用效率,使一个线程可以并发服务多个连接,需要将其从阻塞I/O模式改为非阻塞I/O模式,或更先进的I/O多路复用模式,或异步I/O模式(对这些I/O模型的介绍请见我的上一篇文章:I/O模型及在WebServer中的应用)。对采用不同I/O模型的线程池进行封装,就得到了Reactor(同步非阻塞I/O网络模式)和Proactor(异步I/O网络模式),以及用同步I/O实现的Proactor。
一、Reactor模式
1. 定义
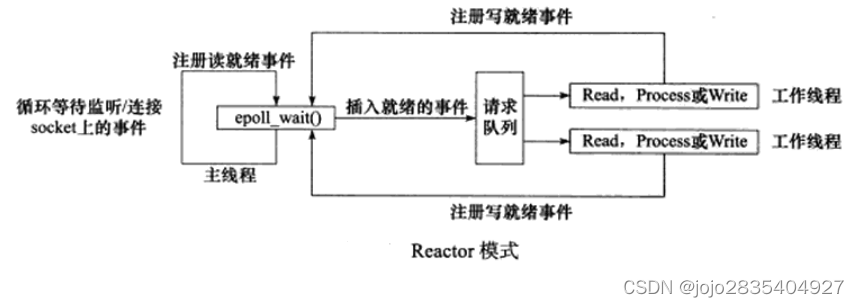
Reactor模式基于同步I/O中的I/O多路复用,包括SELECT、POLL和EPOLL模式。由主线程(Reactor)和工作线程池(Acceptor、Handler、Processor)组成。以下以EPOLL为例介绍主线程和工作线程池的职责。
主线程职责:
1. epoll_create()创建一个epfd,内部维护一棵红黑树和一个就绪事件链表;
2. 通过epoll_ctl()向epfd注册需要监听的socket,由操作系统内核监听树上每个socket是否有事件(读就绪或连接事件)产生,若有,则通过回调函数将该事件加入就绪链表。
3. 通过循环调用epoll_wait(),不断返回就绪链表中的socket数量,主线程将socket及其事件放入请求队列,并立即通知阻塞在请求队列上的工作线程处理事件。
4. 主线程在循环调用epoll_wait()的同时也接收工作线程返回的处理结果写就绪事件,并将该写就绪事件和对应的socket放入请求队列,立即通知工作线程处理事件。
总而言之,主线程负责监听事件产生,并向工作线程分发事件。
工作线程池职责:
1. 工作线程池阻塞在请求队列,当请求队列有任务时,根据事件类型分配对应的线程进行处理。
对于连接事件,分发给Acceptor,调用accept()获取连接,并创建一个Handler对象来处理后续的响应事件。
对于读就绪事件,分发给Handler,调用read()读取数据,调用业务处理函数处理读到的数据。
对于写就绪事件,分发给Handler,调用write()向socket上写入数据。
2.若处理事件结果包括向客户端写数据,则工作线程调用epoll_ctl(),向epfd注册该写就绪事件。
总而言之,接受新连接、读客户端请求数据、处理客户端请求数据、向客户端写响应数据,均在工作线程中完成。
2. Reactor模式的几个分支
1)单Reactor单线程
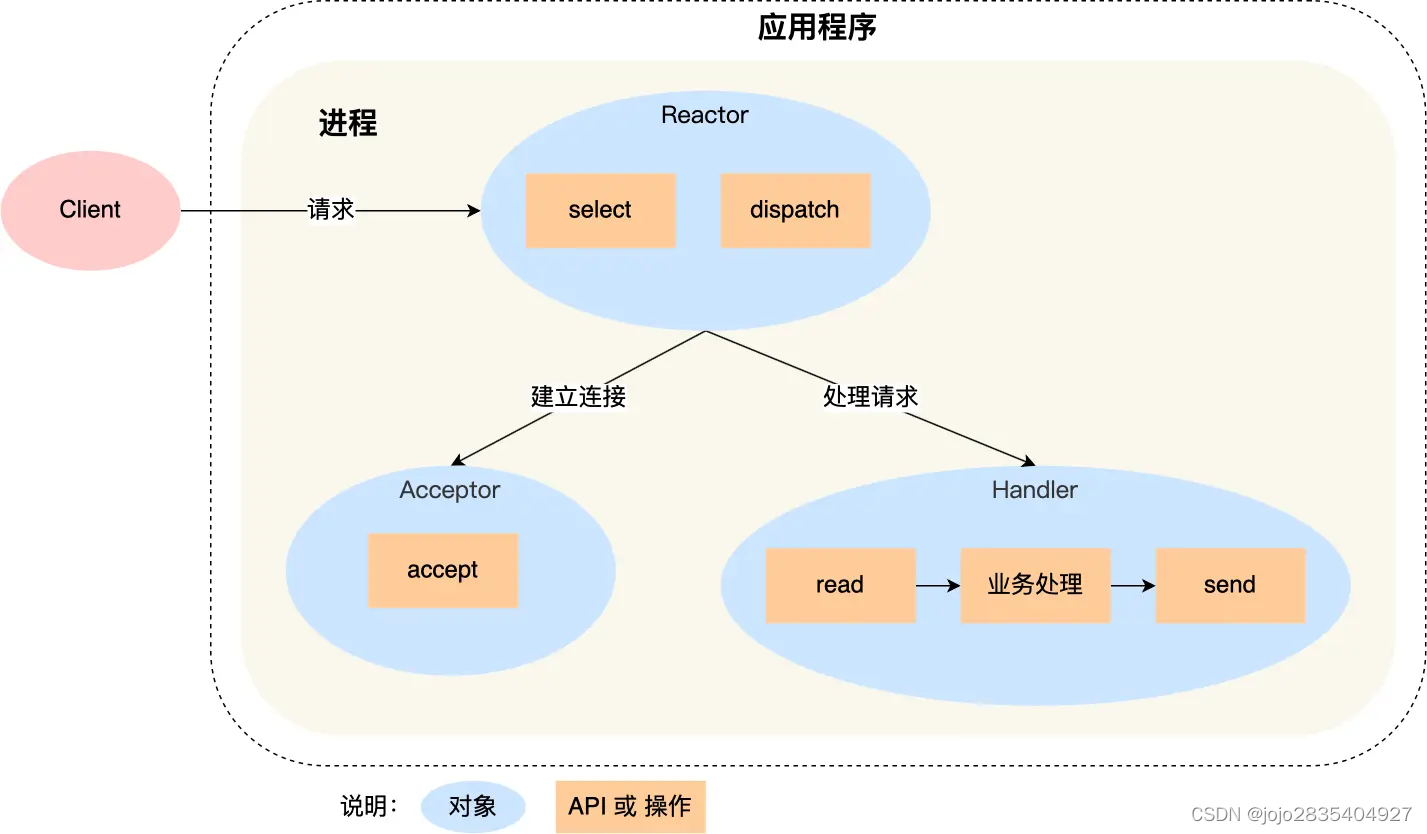
用户进程仅包含一个线程,同时扮演主线程和工作线程,同时有Reactor、Acceptor、Handler,Handler负责read()、process()和write(),对不同业务的处理都在同一个Handler中。
优点:
全部工作都在同一个进程内完成,实现简单,不需要考虑进程间通信或多进程竞争。
缺点:
1. 只有一个进程,无法充分利用多核CPU的性能;
2. 同时只能处理一个连接的业务,若业务处理耗时,则造成响应延迟。
适用场景:
不适用于计算密集型的场景,只适用于业务处理非常快速的场景;同时只能处理一个连接的I/O,不适用于高并发场景。
适用于客户端数量有限、业务处理非常快速的情况,例如Redis在业务处理时间复杂度为O(1)的场景。
代码实现:
#include <iostream>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
int main() {
// Reactor创建监听 socket
int listenSocket = socket(AF_INET, SOCK_STREAM, 0);
// 绑定地址和端口
sockaddr_in serverAddress{};
serverAddress.sin_family = AF_INET;
serverAddress.sin_addr.s_addr = INADDR_ANY;
serverAddress.sin_port = htons(8080); // 使用端口 8080
bind(listenSocket, (struct sockaddr*)&serverAddress, sizeof(serverAddress));
// Reactor监听连接
listen(listenSocket, 10);
while (true) {
// Reactor接受连接
sockaddr_in clientAddress{};
socklen_t clientAddressLength = sizeof(clientAddress);
int clientSocket = accept(listenSocket, (struct sockaddr*)&clientAddress, &clientAddressLength);
// Handler处理连接(这里可以添加业务逻辑,包括read()、process()和write())
std::cout << "Accepted connection from " << inet_ntoa(clientAddress.sin_addr) << std::endl;
// ...
// 关闭客户端 socket
close(clientSocket);
}
// 关闭监听 socket
close(listenSocket);
return 0;
}
2)单Reactor多线程
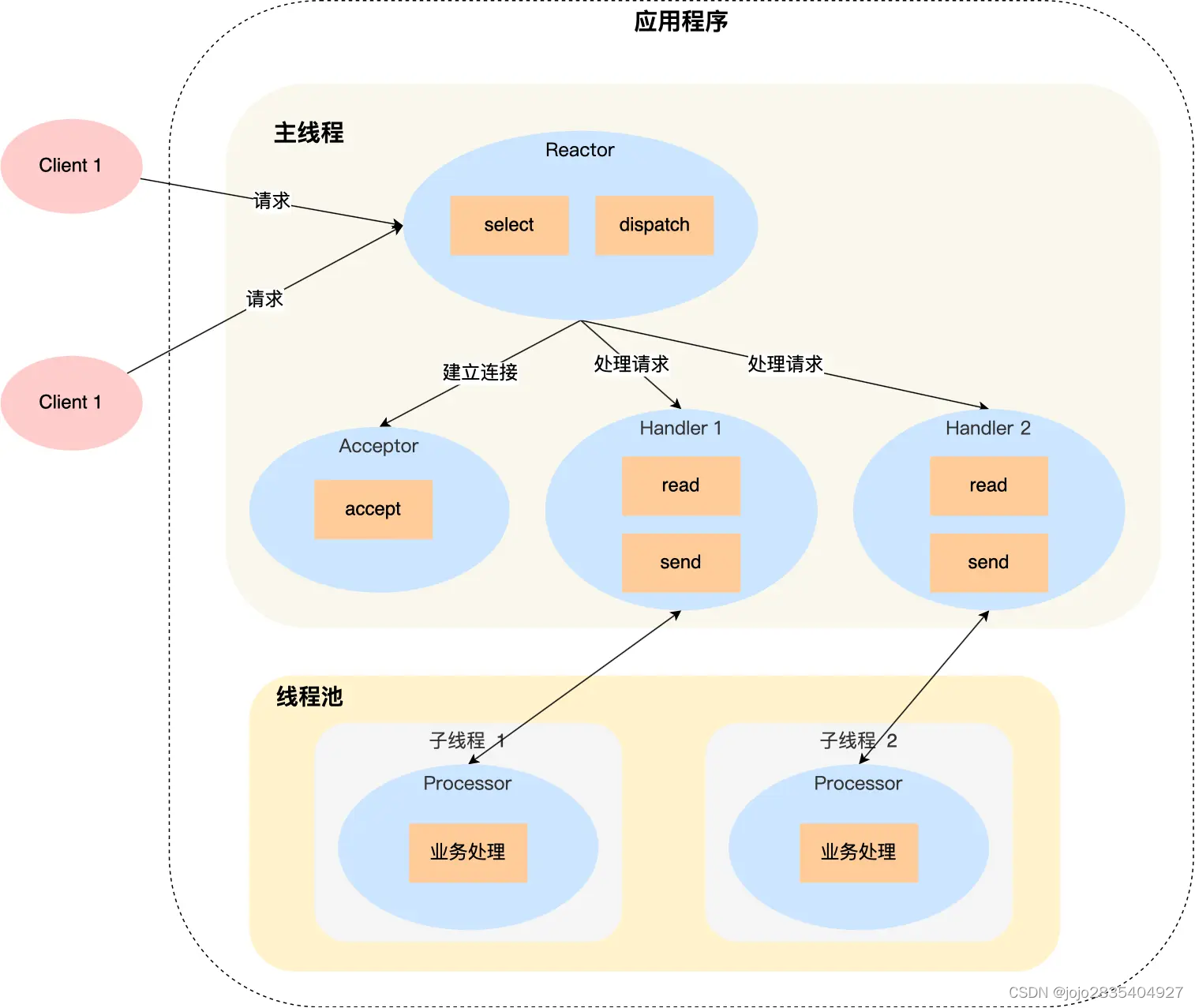
用户进程由主线程和线程池组成。主线程包含了Reactor和工作线程除业务处理外的其他模块对象,即Reactor、Acceptor、Handler。
与单Reactor单线程不同的是,Handler对象不再负责业务处理(process()),而是只负责数据的read()和write()。通过read()读取到数据后,会将数据发给线程池,由线程池分配子线程,进行process()业务处理。处理完后,子线程将结果发给主线程中的Handler,由Handler调用write()将响应结果发送给客户端。
优点:
1. 工作线程池采用多线程,能够充分利用多核CPU的计算能力;
2. 相对于单Reactor单线程模型,在处理连接时不会阻塞整个工作线程,提高并发性;
3.只有一个Reactor线程,避免Reactor线程切换带来的开销。
缺点:
1. 引入多线程,带来了多线程竞争资源的问题;
2. 单个Reactor承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景(如秒杀)时,容易成为性能瓶颈;
3. 如果Reactor线程出现故障,整个系统将无法正常工作。
适用场景:
单Reactor多线程模型适用于事件量较小、对性能要求不高的场景,如简单的Web服务器。
代码实现:
#include <iostream>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#include <thread>
#include <vector>
// 处理连接的线程函数
void handleConnection(int clientSocket) {
// 处理连接(这里可以添加业务逻辑,包括read()、write()和process())
// ...
// 关闭客户端 socket
close(clientSocket);
}
int main() {
// 主线程,创建监听socket
int listenSocket = socket(AF_INET, SOCK_STREAM, 0);
// 绑定地址和端口
sockaddr_in serverAddress{};
serverAddress.sin_family = AF_INET;
serverAddress.sin_addr.s_addr = INADDR_ANY;
serverAddress.sin_port = htons(8080); // 使用端口 8080
bind(listenSocket, (struct sockaddr*)&serverAddress, sizeof(serverAddress));
// 主线程Reactor监听连接
listen(listenSocket, 10);
std::cout << "Listening on port 8080..." << std::endl;
// 创建多个工作线程
const int numThreads = 4; // 假设使用 4 个线程
std::vector<std::thread> threads;
for (int i = 0; i < numThreads; ++i) {
threads.emplace_back(& {
while (true) {
// 主线程Acceptor接受客户端连接
sockaddr_in clientAddress{};
socklen_t clientAddressLength = sizeof(clientAddress);
int clientSocket = accept(listenSocket, (struct sockaddr*)&clientAddress, &clientAddressLength);
// 工作线程Handler处理连接
handleConnection(clientSocket);
}
});
}
// 等待线程结束
for (auto& thread : threads) {
thread.join();
}
// 关闭监听socket
close(listenSocket);
return 0;
}
3)多Reactor多线程(主从Reactor)
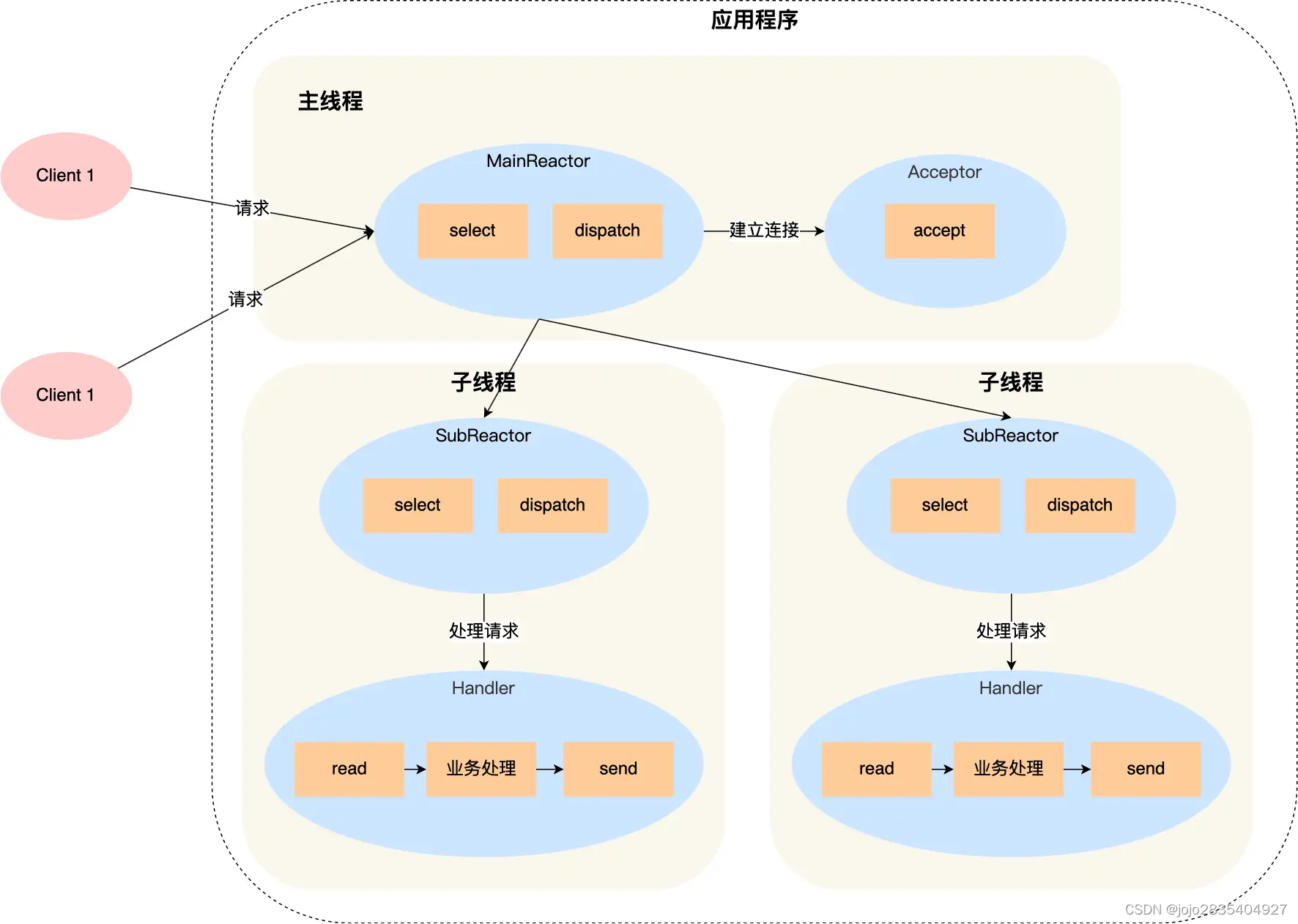
主线程中的MainReactor监听连接事件,主线程中唯一的工作线程,Acceptor建立连接,并将连接传递给线程池,线程池分配子线程接收连接。每个子线程都有自己的SubReactor和Handler,SubReactoe独立监听一个连接上的读就绪事件和写就绪事件,并由各自的Handler处理这些事件。
优点:
1. 高并发处理能力:多个Reactor线程可以并行处理事件,提高了系统的并发处理能力;
2. 实现逻辑简单:主线程只负责接收新连接,子线程负责完成后续的业务处理,无需交互。
缺点:
多个Reactor线程会消耗更多的系统资源,可能会导致资源利用率下降。
适用场景:
主从Reactor多线程模型适用于事件量较大、对性能要求较高的场景,如高性能的Web服务器、数据库等。
代码实现:
#include <iostream>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <fcntl.h>
#include <cstring>
#include <cassert>
#include <cstdlib>
#include <cstdio>
#include <cerrno>
#include <vector>
const int MAX_EVENT_NUMBER = 1024;
const int TCP_BUFFER_SIZE = 512;
// 封装一个事件结构体,包含文件描述符和事件类型
struct ReactorEvent {
int fd;
uint32_t events;
};
//Reactor类,包括MainReactor和SubReactor
class Reactor {
public:
Reactor() : epollfd_(epoll_create(5)) {
assert(epollfd_ >= 0);
}
~Reactor() {
close(epollfd_);
}
void AddEvent(int fd, uint32_t events) {
ReactorEvent event {fd, events};
struct epoll_event epollEvent;
memset(&epollEvent, 0, sizeof(epollEvent));
epollEvent.data.ptr = &event;
epollEvent.events = events;
epoll_ctl(epollfd_, EPOLL_CTL_ADD, fd, &epollEvent);
}
void RemoveEvent(int fd) {
epoll_ctl(epollfd_, EPOLL_CTL_DEL, fd, nullptr);
}
void ModifyEvent(int fd, uint32_t events) {
ReactorEvent event {fd, events};
struct epoll_event epollEvent;
memset(&epollEvent, 0, sizeof(epollEvent));
epollEvent.data.ptr = &event;
epollEvent.events = events;
epoll_ctl(epollfd_, EPOLL_CTL_MOD, fd, &epollEvent);
}
void Dispatch() {
std::vector<ReactorEvent> events(MAX_EVENT_NUMBER);
while (true) {
int count = epoll_wait(epollfd_, &events[0], MAX_EVENT_NUMBER, -1);
if (count < 0) {
std::cerr << "epoll_wait() error" << std::endl;
break;
}
for (int i = 0; i < count; ++i) {
auto& event = events[i];
if (event.events & EPOLLIN) {
// 处理读事件
char buffer[TCP_BUFFER_SIZE];
memset(buffer, '\0', TCP_BUFFER_SIZE);
int ret = recv(event.fd, buffer, TCP_BUFFER_SIZE - 1, 0);
std::cout << "Received data: " << buffer << std::endl;
}
else if (event.events & EPOLLOUT) {
// 处理写事件
const char* message = "Hello, client!";
send(event.fd, message, strlen(message), 0);
}
}
}
}
private:
int epollfd_;
};
int main() {
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_addr.s_addr = htonl(INADDR_ANY);
address.sin_port = htons(12345);
int ret = bind(listenfd, reinterpret_cast<struct sockaddr*>(&address), sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
Reactor reactor;
reactor.AddEvent(listenfd, EPOLLIN);
std::cout << "Server is running..." << std::endl;
reactor.Dispatch();
close(listenfd);
return 0;
}
二、Proactor模式
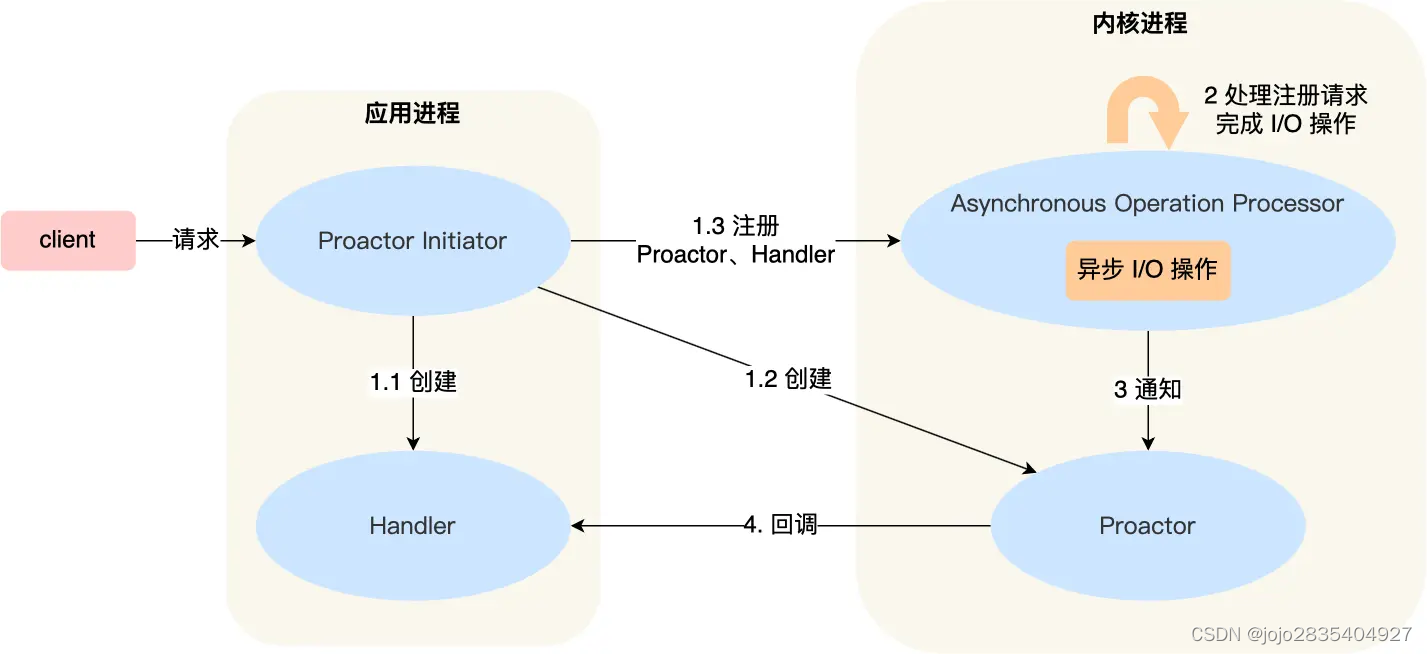
1. 定义
与 Reactor 模式不同,Proactor 模式包括应用进程(包括初始化线程Proactor Initiator、业务处理线程Handler)和内核进程(包括通知线程Proactor、注册及I/O线程Asynchronous Operator Processor),其中:
应用进程的Procator Initiator负责创建Procator和Handler,并将Procator和Handler都通过Asynchronous Operation Processor注册到内核。
Asynchronous Operation Processor负责处理注册请求,并完成read()或write()操作。完成I/O操作后会通知Procator。
Procator根据不同的事件类型回调不同的Handler进行业务处理。Handler也可以注册新的Handler到内核进程。
1. 首先,Proactor Initiator创建并初始化异步操作对象,并将其提交给Asynchronous Operation Processor;
2. Asynchronous Operation Processor将异步操作注册到操作系统的I/O完成端口,并开始异步地执行I/O操作;
3. 同时,Proactor不断地监视I/O完成端口,一旦有I/O操作完成事件发生,Proactor将相应的完成事件通知给对应的Handler;
4. 在Handler中,应用程序可以处理所读取或写入的数据,或者进行一些后续操作,比如释放资源或启动下一轮异步I/O操作。
2. 优缺点
优点:
1. 高并发性能:将I/O操作的管理和处理分离,提高系统的并发性能和可扩展性;
2. 非阻塞:基于完成事件驱动,避免了某个连接阻塞而导致整个系统受到影响。
缺点:
1. 实现复杂;
2. 由于涉及异步I/O机制,可能会增加系统资源的消耗和调试难度。
3. 适用场景
适用于需要处理大量并发连接、并且对系统并发性能有较高要求的大规模服务器或系统,因为Proactor能够更好地利用多核处理器,提高系统的并发处理能力。
4. 代码实现
在 Linux 下的异步 I/O 是不完善的,aio系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的aio异步操作,不支持网络编程。因此,大多基于 Linux 的高性能网络程序都是使用 Reactor 方案。
三、同步I/O模拟Proactor模式(WebServer采用)

1. 定义
主线程调用read()、write(),执行数据读写I/O操作。读写完成之后,主线程向工作线程通知这一“完成事件”。工作线程直接获得了数据读写的结果,只负责对传递给它的读写得到的数据进行业务逻辑处理。
1. 主线程调用epoll_create()构建红黑树和就绪链表;
2. 主线程调用epoll_ctl()往epoll内核事件表中注册socket上的读就绪事件;
3. 主线程调用 epoll_wait()等待socket上有数据可读;
4. 当socket上有数据可读时,epoll_wait()通知主线程;
5. 主线程调用read(),非阻塞I/O从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列;
6. 睡眠在请求队列上的某个工作线程被唤醒,获得请求对象并处理客户请求,然后调用epoll_ctl(),往epoll内核事件表中注册 socket 上的写就绪事件;
7. 主线程调用epoll_wait()等待socket可写;
8. 当socket上有数据可写时,epoll_wait()通知主线程;
9. 主线程调用write()往socket上写入服务器处理客户请求的结果。
2. 优缺点
优点:
1. 相对于直接使用底层异步I/O机制,通过利用多线程模拟异步I/O,更易于理解和实现;
2. 可以在Linux上实现Proactor模式。
缺点:
1. 线程间同步与通信增加了系统的复杂性,并引入了潜在的死锁和竞态条件问题;
2. 创建和管理大量的工作线程可能会导致较大的资源消耗,包括内存、CPU时间片等;
3. 频繁的线程上下文切换可能会引起性能下降。
3. 适用场景
在需要用到Proactor的高并发能力,同时需要保持跨平台兼容性的情况下,同步I/O模拟Proactor能够较好地满足需求。
4. 代码实现
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
#include <condition_variable>
// 模拟异步I/O操作的处理器
class AsyncProcessor {
public:
// 异步读取数据的方法
void asyncRead(std::function<void(std::string)> callback) {
// 模拟异步读取数据的过程
std::this_thread::sleep_for(std::chrono::seconds(1));
// 假设读取到了数据
std::string data = "Hello, async I/O!";
// 调用回调函数处理读取到的数据
callback(data);
}
};
int main() {
// 创建多个AsyncProcessor实例,并模拟多个异步I/O请求
std::vector<AsyncProcessor> processors(5);
// 创建多个线程来处理异步I/O请求
std::vector<std::thread> threads;
for (int i = 0; i < processors.size(); ++i) {
threads.emplace_back([i, &processors]() {
std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx);
std::condition_variable cv;
// 异步读取数据,并指定回调函数处理结果
processors[i].asyncRead([&cv](std::string data) {
std::cout << "Thread " << std::this_thread::get_id() << " received data: " << data << std::endl;
cv.notify_one(); // 通知主线程数据已处理完毧
});
// 等待当前异步操作完成
cv.wait(lock);
});
}
// 等待所有线程执行完成
for (auto& thread : threads) {
thread.join();
}
return 0;
}















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









