







前言
啊,之前看锅tensorflow的原码,也记了点Graph Convolutional Networks for Text Classification原码解读[tensorflow]
项目地址
https://github.com/iworldtong/text_gcn.pytorch
环境配置
就在tensorflow那个版本的环境下,补装了1.7.1+cu101的pytorch
代码解析
remove_words.py
就是原版的代码
build_graph.py
也是原版的代码
好奇:看到也用了scipy的csr_matrix函数,难道pytorch也有类似的矩阵运算?
train.py
一些维度&一些输出
adj (61603, 61603)
features (61603, 300)
y_train (61603, 20)
y_val (61603, 20)
y_test (61603, 20)
train_mask (61603,)
val_mask (61603,)
test_mask (61603,)
train_size 11314
test_size 7532
tm_train_mask torch.Size([61603, 20])
t_support[0] torch.Size([61603, 61603])
pre_sup torch.Size([61603, 200])
support0 torch.Size([61603, 61603])
out torch.Size([61603, 200])
logits * tm_train_mask[0] : tensor([ 0.0521, -0.0080, 0.2177, -0.1337, 0.1672, -0.0428, 0.0664, -0.1221,
0.0376, 0.0709, -0.3589, 0.2038, 0.0118, -0.1365, -0.2384, -0.1432,
0.0838, 0.1781, 0.2771, 0.1930], grad_fn=<SelectBackward>)
t_y_train[0]:tensor([0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.], dtype=torch.float64)
torch.max(t_y_train, 1)[0]:tensor(8)
features = preprocess_features(features)
# return sparse_to_tuple(features)
return features.A
删除了sparse_to_tuple函数
def sparse_to_tuple(sparse_mx):
"""Convert sparse matrix to tuple representation."""
def to_tuple(mx):
if not sp.isspmatrix_coo(mx):
mx = mx.tocoo()
coords = np.vstack((mx.row, mx.col)).transpose()
values = mx.data
shape = mx.shape
return coords, values, shape
if isinstance(sparse_mx, list):
for i in range(len(sparse_mx)):
sparse_mx[i] = to_tuple(sparse_mx[i])
else:
sparse_mx = to_tuple(sparse_mx)
return sparse_mx
preprocess_adj(adj)
同样是这样
# return sparse_to_tuple(adj_normalized)
return adj_normalized.A
tm_train_mask = torch.transpose(torch.unsqueeze(t_train_mask, 0), 1, 0).repeat(1, y_train.shape[1])
把原来是(real_train_size+valid_size+vocab_size+test_size,)的向量转成了一个(real_train_size+valid_size+vocab_size+test_size, 标签个数)的tensor
训练
啊,略了。
评估
from sklearn import metrics
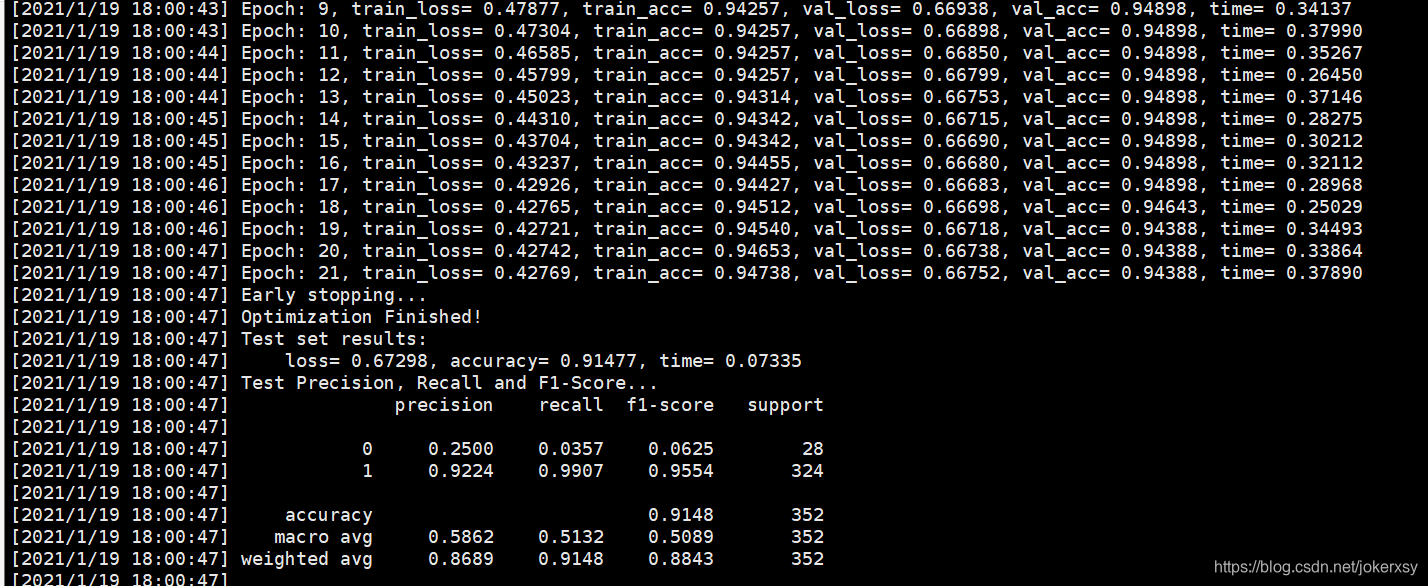
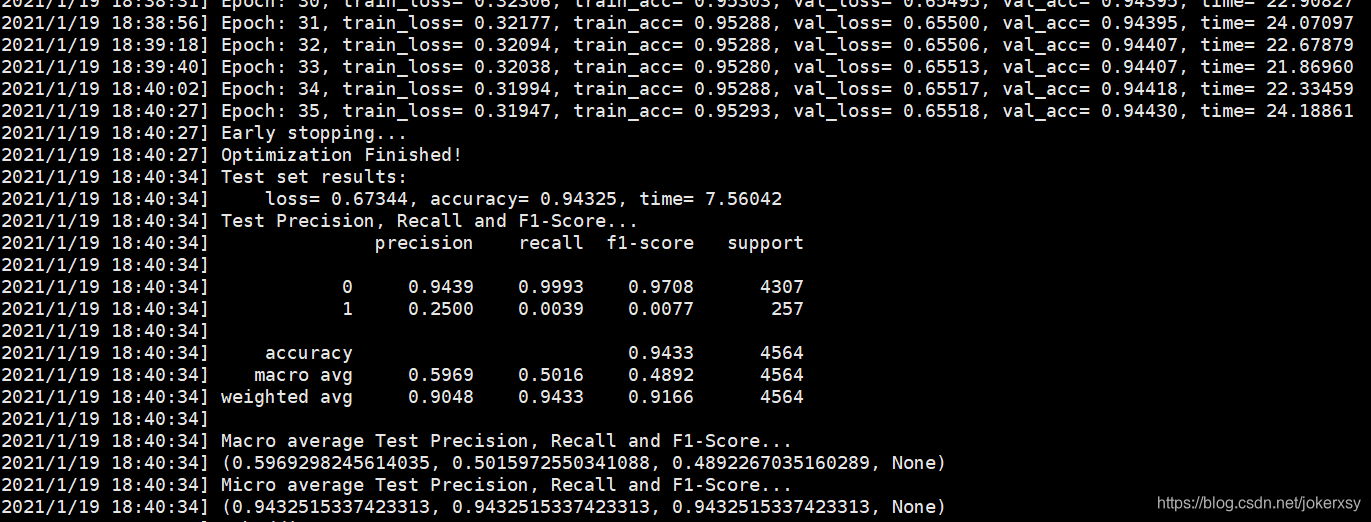
print_log("Test Precision, Recall and F1-Score...")
print_log(metrics.classification_report(test_labels, test_pred, digits=4))
print_log("Macro average Test Precision, Recall and F1-Score...")
print_log(metrics.precision_recall_fscore_support(test_labels, test_pred, average='macro'))
print_log("Micro average Test Precision, Recall and F1-Score...")
print_log(metrics.precision_recall_fscore_support(test_labels, test_pred, average='micro'))
构建自己的数据集-wiki80
选择了80/10/10的wiki_727K玩玩:
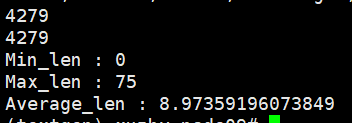
adj (7002, 7002)
features (7002, 300)
y_train (7002, 2)
y_val (7002, 2)
y_test (7002, 2)
train_mask (7002,)
val_mask (7002,)
test_mask (7002,)
train_size 3927
test_size 352
构建自己的数据集-wiki800
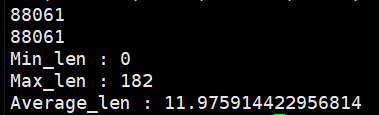
adj (109772, 109772)
features (109772, 300)
y_train (109772, 2)
y_val (109772, 2)
y_test (109772, 2)
train_mask (109772,)
val_mask (109772,)
test_mask (109772,)
train_size 83497
test_size 4564
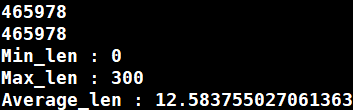
构建自己的数据集-wiki8000














 1479
1479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









