







文章目录
- 前言
- 《Text Segmentation as a Supervised Learning Task》——NAACL2018
- 《A Joint Model for Document Segmentation and Segment Labeling》——ACL2020
- 《Attention-based Neural Text Segmentation》——ECIR2018
- 《Two-Level Transformer and Auxiliary Coherence Modeling for Improved Text Segmentation》——AAAI2020
- 《Topic Segmentation of Web Documents with AutomaticCue Phrase Identification and BLSTM-CNN》
- 《Learning to Rank Semantic Coherence for Topic Segmentation》——EMNLP2017
- 《SEGBOT: A Generic Neural Text Segmentation Model with Pointer Network》——IJCAI2018
- 《Toward Fast and Accurate Neural Discourse Segmentation》——EMNLP2018
- 《Improving Context Modeling in Neural Topic Segmentation》——AACL2020
- 《Text Segmentation by Cross Segment Attention》——EMNLP2020
- 《SECTOR: A Neural Model for Coherent TopicSegmentation and Classification》——TACL2019
- 数据集汇总
- 趋势
前言
本文总结了10篇话题分割领域的论文的主要方法,并最后总结归纳了所有出现过的数据集、模型性能。
《Text Segmentation as a Supervised Learning Task》——NAACL2018

原码解读:https://blog.csdn.net/jokerxsy/article/details/109237492
github链接:
https://github.com/koomri/text-segmentation
数据集链接:
https://www.dropbox.com/sh/k3jh0fjbyr0gw0a/AADzAd9SDTrBnvs1qLCJY5cza?dl=0
experiments:
pk值
- 训练集:wiki727K
- 测试集:wiki727K, wiki-50, choi, cities, elements
- 比较的模型:graphseg, random baseline, chen(word级别)

平均每篇文章的运行时间
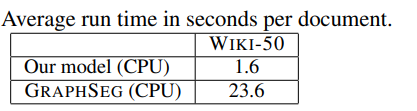
结论:以wiki727K为训练集,在wiki727K, wiki-50, choi, cities, elements数据集上,与textseg和graphseg进行比较。
《A Joint Model for Document Segmentation and Segment Labeling》——ACL2020

模型分为
1)Encoding Sentences :lstm+pooling(max+mean+last)得到句子向量表示
2)Predicting Segment Bounds:bilstm+classifier分类是否是分割点
3)Segment Pooling:lstm+pooling(max+mean+last)得到segment的向量表示 + classifier
4)Segment Alignment and Exploration:teacherforcing+aligning。其中,teacherforcing阶段只把ground truth作为segment pooling的输入,ground truth的标签作为正确的标签;exploration阶段则把pred作为segment pooling的输入,然后和groud truth作对齐,把对齐过后的ground truth的标签作为正确的标签。就比如下图中,原来的ground truth标签为[h,p,g,e],对齐过后为[h,p,p,g,e]。

性能如下:
segment classfication

topic classification

transfer result

《Attention-based Neural Text Segmentation》——ECIR2018
我觉得这篇写的跟屎一样,我愣是没能理解它的模型在干什么。
github链接:https://github.com/pinkeshbadjatiya/neuralTextSegmentation

不过它提出了很有意思的一点:在考虑第i个句子是否是分割点的时候,模型的输入实际上是 K + 1 + K = 2K+1个句子。模型步骤可能如下:
1)每个句子经过padding\truncate之后长度固定为L,进一步embedding就变成了Lxd.
2)对于这个Lxd的矩阵,使用z个hxd大小的filters,每一个filter都是从第一行到第L行向下滑动来得到 ?维向量( ? 或许 = L - h + 2xpadding),z个filter,就得到了 ? x z大小的矩阵。然后用maxpooling得到 z 维的向量.
3)有2K+1个句子,就有 2K + 1个z维的向量.
4)接着又分别考虑K个上文句子、1个当前句子、K个下文句子。对于两个长度为K的上下文段落,分别用2layers的bilstm+attnpooling来得到一个z为的向量。对于一个长度为1的当前句子向量,应该保持不变,但图中醒目地标识着"Attention-2"。。莫名其妙。。。attnpooling的过程也理解不能:

5)有了三个z维的向量,再经过拼接?还是相加?得到一个向量,然后线性层分类.
性能如下:

《Two-Level Transformer and Auxiliary Coherence Modeling for Improved Text Segmentation》——AAAI2020
分成三段:
1)Sentence Encoding

输入k个长T的句子,加入[ss]这个开始符,经过NTT层的transformer,得到句子向量表示。
2)Sentence Contextualization

同样的操作,得到加入上下文信息的句子向量表示,并取出[sss]作为输入段落的向量表示。其中,句子向量表示用于分类是否是分割点,输入段落的向量表示用于计算连续性分数(👇)。
3)Auxiliary Coherence Modeling

给当前输入段落的向量表示通过线性层得到连续性分数1;另外给一个随机(随机打乱顺序、随机替换)的段落也通过上述模型、上述线性层,得到一个连续性分数2,希望分数1更大。

experiments:
pk值
- 训练集:wiki727K
- 测试集:wiki727K, wiki-50, choi, cities, elements
- 比较的模型:graphseg, random baseline, textseg
性能如下:
transfer能力,略。
《Topic Segmentation of Web Documents with AutomaticCue Phrase Identification and BLSTM-CNN》

模型如上,用于句子编码和分类,不是关键。
主要有七个细节:
1)Cue Phrase
2)Lexical feature
3)Part-of-Speech(POS) feature
4)Length feature
5)Position feature
6)Hyperlink feature
7)Text font feature
性能如下(在某个某度提供的数据集上):

《Learning to Rank Semantic Coherence for Topic Segmentation》——EMNLP2017
不是文本对分类。

模型输入的是两个"segments",输出是两个的匹配分数。希望:
1)来自相同文章的文本对匹配分数要高于来自不同文章的
2)来自相同段落的文本对匹配分数要高于来自不同段落的
采用两种评测方式来计算loss:1.Pointwise Ranking 2.Pairwise Ranking with Sampling
性能如下:

《SEGBOT: A Generic Neural Text Segmentation Model with Pointer Network》——IJCAI2018

1)Encoding Phase:双向GRU
2)Decoding Phase:由于是teacherforcing的,知道有M个boundaries,所以看作有M个时间部。每一个时间部产出的decoder hidden state
d
m
d_m
dm会与包括m及其以后的所有unit的encoder hidden state计算概率分布。
只是知道有point network的做法,细节理解不了(特别是m和M,for j ∈(m,…,M)?? M不是boundaries个个数吗…看样子这里的M应该换成N(序列长度)啊)👇:
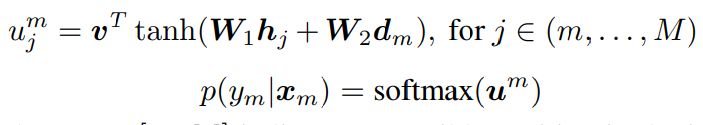

性能如下:

《Toward Fast and Accurate Neural Discourse Segmentation》——EMNLP2018
并不是话题分割,而是把篇章(句子)分割成多个EDU(Elementary Discouse Units)(—>可以理解成span?)

1)Transfered Representation:ELMO词向量表示,与下面的word embedding(指的是glove)拼接起来。
2)Restricted Self-Attention:定义一个大小为5的窗口[h1,h2,h3,h4,h5],利用下面公式计算h3与其它h的相似性分数
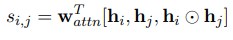
做归一化之后再加权求和

最后把
a
i
a_i
ai和
h
i
h_i
hi做拼接,得到了attention之后的单词向量表示
3)最后送入BILSTM+CRF进行序列标注
由于是EDU segmentation task,就不放性能了。
哦对,顺便把self-attention的代码贴在👇:
def mask_logits(inputs, mask, mask_value=-1e30):
mask = tf.cast(mask, tf.float32)
return inputs + mask_value * (1 - mask)
def trilinear_similarity(x1, x2, scope='trilinear', reuse=None):
with tf.variable_scope(scope, reuse=reuse):
x1_shape = x1.shape.as_list()
x2_shape = x2.shape.as_list()
if len(x1_shape) != 3 or len(x2_shape) != 3:
raise ValueError('`args` must be 3 dims (batch_size, len, dimension)')
if x1_shape[2] != x2_shape[2]:
raise ValueError('the last dimension of `args` must equal')
weights_x1 = tf.get_variable('kernel_x1', [x1_shape[2], 1], dtype=x1.dtype)
weights_x2 = tf.get_variable('kernel_x2', [x2_shape[2], 1], dtype=x2.dtype)
weights_mul = tf.get_variable('kernel_mul', [1, 1, x1_shape[2]], dtype=x2.dtype)
bias = tf.get_variable('bias', [1], dtype=x1.dtype, initializer=tf.zeros_initializer)
subres0 = tf.tile(tf.keras.backend.dot(x1, weights_x1), [1, 1, tf.shape(x2)[1]])
subres1 = tf.tile(tf.transpose(tf.keras.backend.dot(x2, weights_x2), (0, 2, 1)), [1, tf.shape(x1)[1], 1])
subres2 = tf.keras.backend.batch_dot(x1 * weights_mul, tf.transpose(x2, perm=(0, 2, 1)))
return subres0 + subres1 + subres2 + tf.tile(bias, [tf.shape(x2)[1]])
def self_attention(inputs, lengths, window_size=-1, scope='bilinear_attention', reuse=None):
with tf.variable_scope(scope, reuse=reuse):
# logits = tf.matmul(inputs, inputs, transpose_b=True) # Q * K
logits = trilinear_similarity(inputs, inputs) # bs x l x l
mask = tf.sequence_mask(lengths, tf.shape(inputs)[1], tf.float32) # bs x maxlength(l)
mask = tf.expand_dims(mask, 1) # bs x 1 x l
if window_size > 0:
restricted_mask = tf.matrix_band_part(tf.ones_like(logits, dtype=tf.float32), window_size, window_size) # bs x l x l
mask = mask * restricted_mask # bs x l x l
logits = mask_logits(logits, mask) # bs x l x l
weights = tf.nn.softmax(logits, name='attn_weights') # bs x l x l
return tf.matmul(weights, inputs), weights # bs x l x dim
《Improving Context Modeling in Neural Topic Segmentation》——AACL2020
究极缝合怪。

- 主框架是textseg,也沿用了里面的阈值
- 词向量部分把word2vec(300)和bert做了拼接(768)
- 使用bilstm+attention来得到句子向量表示
- 得到了句子向量表示之后,设置窗口(3),进行restricted attention
- training object利用coherence进行辅助训练
主要看看它怎么做实验的:
- Intra Domain:
1.1 CHOI 8/1/1
1.2 RULES 8/1/1
1.3 WIKI-SECTION(English) 7/1/2
性能如下:

结论:以wiki727K,choi,wikisections三个数据集为训练集和测试集,与random\BayesSeg\GraphSeg\TextSeg\Sector\Transformer\AUX+RSA 作比较。
- Domain Transfer:
2.1 训练集:WIKI-SECTION
2.2 测试集:WIKI-50\Cities\Elements\Clinical Books
性能如下:

结论:关于transfer的性能,还是基于wiki727K吧~
3) Multilingual:
3.1 WIKISECTION(English)
3.2 WIKISECTION(German)
3.3 SECTION-ZH
性能如下:

(AUX:auxiliary)
(RSA:restricted attention)
《Text Segmentation by Cross Segment Attention》——EMNLP2020
提出了三种模型,暂时不太懂bert。

性能如下:

《SECTOR: A Neural Model for Coherent TopicSegmentation and Classification》——TACL2019
数据集汇总
| WIKI-727K | CHOI | MANIFESTO | CITES | ELEMENTS | RST-DT(EDU) | wikisection | Clinical | Fiction | Wikipedia | Jeong | RULES | SECTION-EN | SECTION-DE | SECTION-ZH | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 链接 | HERE | HERE | HERE | HERE | HERE | 略 | HERE | HERE/HERE | HERE | HERE | HERE | 失踪 | wikisection | wikisection | HERE |
| 文章数 | 727,746 | 920 | 5 | 100 | 118 | 385 | 227 | 85 | 300 | 864 | 4,461 | 21,376 | 12,993 | 10,000 | |
| 分割长度 | 13.6 ± 20.3 | 7.4 ± 2.96 | 8.99 ± 10.8 | 5.15 ± 4.57 | 3.33 ± 3.05 | 35.72 | 24.15 | 25.9 | 7.4 | 7.2 | 6.3 | 5.1 | |||
| 分割个数 | 3.48 ± 2.23 | 9.98 ± 0.12 | 127 ± 42.9 | 12.2 ± 2.79 | 6.82 ± 2.57 | 5.0 | 16.6 | 7.9 | 7.0 | 6.4 | |||||
| 句子数 | 31868 | 27551 | 58071 |
趋势
- 2020的基本都是基于bert的(本博客暂没有涉及)
- 还有一个趋势就是多任务的目标函数















 1856
1856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









