









maskformer:Per-Pixel Classification is Not All You Need for Semantic Segmentation
论文地址:https://arxiv.org/pdf/2107.06278
1.概述
传统的语义分割方法通常采用逐像素分类(per-pixel classification),而实例分割则使用不同的掩模分类(mask classification)方法。能否用掩膜分类的方法处理语义分割呢?当然是可以的。(掩膜分类:与逐像素分类不同,掩膜分类不是对每个像素单独分类,而是预测整个区域的掩膜(即区域的边界和形状),并将整个掩膜分类到一个类别。这种方法识别整个对象或区域,而不仅仅是单个像素。)
MaskFormer方法通过预测与单一类预测关联的一组二进制掩模来解耦图像分割和分类的过程,提供了一种比逐像素分类更灵活的方法。掩模分类足够通用,可以同时解决语义和实例级别的分割任务。
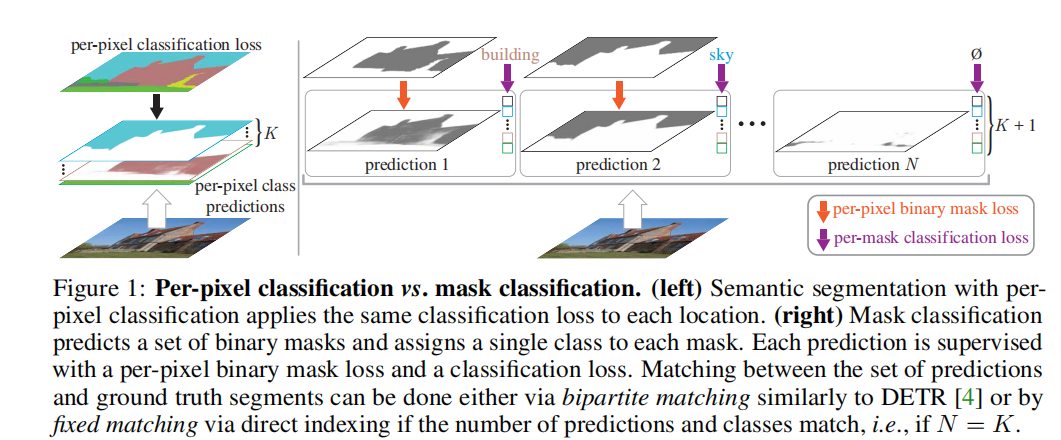
2.详细流程
MaskFormer 是一种用于图像分割的模型,它整合了多个组件来处理语义和实例级分割任务。这个模型包括三个主要模块:像素级模块(Pixel-level module)、Transformer模块(Transformer module)和分割模块(Segmentation module)。具体流程为:

(1)像素级模块(Pixel-level Module)
- 输入和特征提取:输入是一张大小为 H×W 的图像。通过一个骨架网络(backbone),例如ResNet或VGG,提取低分辨率的特征图 F。这个特征图的尺寸为
,其中
是通道数,S 是步长(通常设为32)。
- 特征上采样:像素解码器(pixel decoder)逐渐上采样这些特征,生成每像素嵌入 pixel×pixel。这个过程旨在从低分辨率特征图中恢复更详细的空间信息,为后续的掩模预测提供支持。
(2)变换器模块(Transformer Module)
- 生成掩模嵌入:变换器解码器(transformer decoder)接收上采样的像素嵌入,并使用 N 个位置嵌入(查询)生成 N 个掩模嵌入𝑄。这些嵌入捕捉图像中每个潜在分割区域的全局信息。
- 并行处理:解码器并行输出所有预测,每个嵌入对应一个特定的掩模预测。
(3)分割模块(Segmentation Module)
- 分类和掩模预测:应用线性分类器和 softmax 激活函数在掩模嵌入上,生成每个掩模的类别概率预测
。此外,通过多层感知机(MLP)处理掩模嵌入𝑄,生成掩模
的二进制预测。
- 二值掩模生成:使用点积操作将每个掩模嵌入与对应的像素嵌入结合,然后通过 sigmoid 激活函数生成最终的二进制掩模
(4)掩模分类推理(Mask-Classification Inference)
- 通用推理:将图像分割为若干个掩模区域,通过匹配每个像素的最大类别概率和掩模概率来分配像素。
- 语义推理:为语义分割任务专门设计,通过矩阵乘法合并所有二进制掩模和它们的类别预测,生成每个像素的类别标签。
3.实验
mask2former
1.概述
Maskformer存在着计算量大、收敛困难的问题,针对于这个问题,这篇论文提出了Mask2former,这种架构的关键特点是:
-
掩码注意力(Masked Attention):该机制通过在Transformer解码器中对预测的掩码区域内的特征进行聚焦,从而允许模型在保持高效性的同时提取出具有高度局部相关性的特征。
-
多尺度高分辨率特征利用:为了改善对小物体的分割效果,作者提出在不同的Transformer解码器层中使用来自像素解码器的不同分辨率的特征图。
-
优化的注意力顺序和查询特征学习:通过改变自注意力和交叉注意力的顺序,使查询特征可学习,并移除dropout,这些优化措施提高了性能并减少了所需的计算量。
-
训练效率的提高:通过在计算掩码损失时只采样随机点而非全图,显著减少了训练过程中的内存需求,使得模型更易于训练和部署。
2.具体流程
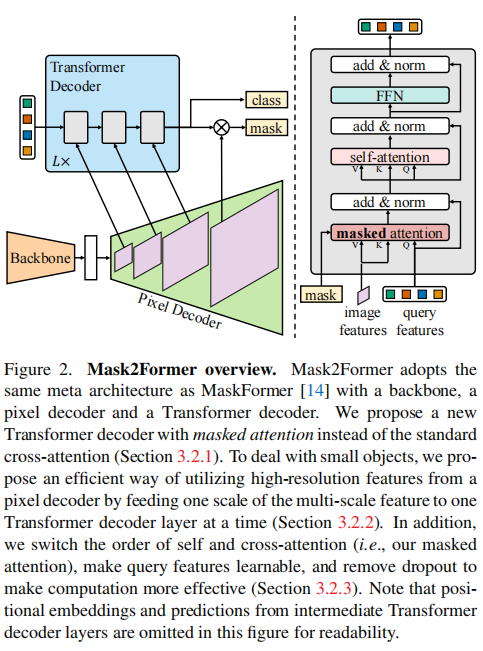
Mask2former主要建立在Maskformer的基础之上。
(1)Transformer解码器与掩码注意力
Mask2Former引入了掩码注意力机制。这种注意力机制的核心是在预测掩码的前景区域内约束交叉注意力,从而提取局部化的特征。这一策略旨在提高模型处理小对象的能力,并通过以下几种方法优化模型性能:
掩码注意力
- 基本概念:掩码注意力是一种交叉注意力的变体,它只在预测掩码的前景区域内聚焦,而不是整个特征图。
- 实现方式:通过修改标准交叉注意力的注意力矩阵,使其在预测掩码的有效区域内应用softmax操作,通过将背景区域值置为负无穷从而排除背景区域,实现局部聚焦。

高分辨率特征
- 策略描述:为了在不显著增加计算负担的情况下处理小对象,Mask2Former引入了一种多尺度策略,利用像素解码器输出的多尺度特征图。这些特征图按从低到高的分辨率供给给Transformer解码器的不同层,从而使每一层都能接收到适合其处理需求的特征级别。
- 细节实现:例如,特征图的分辨率可以是1/32、1/16、1/8原图大小,通过这种方法,可以在不同层上应用不同分辨率的特征图,以此优化性能并减少计算资源的消耗。
优化改进
- 解码器改进:在标准的Transformer解码器层中,包含自注意力模块、交叉注意力和前向馈网络(FFN)。为了提高效率和性能,Mask2Former在这一结构上做出了调整,包括改变自注意力和交叉注意力的顺序,使查询特征可学习,并去除dropout。
- 训练效率提升:通过在匹配和最终损失计算中使用采样点而非完整掩码,显著降低了训练过程中的内存需求,从18GB减少到6GB,这使得模型在有限的计算资源下更加易于训练和使用。
3.实验
在多个数据集上实现了新的sota

















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











