







本文利用CUDA实现简单二维平面上的热传导模拟。假设有一个矩形房间,将其分成一个网格,在网格中随机散布一些热源,热源有不同的固定温度,然后就可以计算网格中每个单元的温度随时间的变化情况。本文将热传导模型做如下简化:某单元的新时刻温度等于原有温度加其与邻接单元的温差,邻接单元取上下左右四个单元。
温度更新算法:
Step1: 给定一个包含初始输入温度的网格,将其作为热源温度值复制到网格对应的单元;
Step2: 规定一个输入温度网格,根据热传导模型更新温度到输出网格;
Step3: 交换输入温度网格和输出温度网格的数据,转step1.
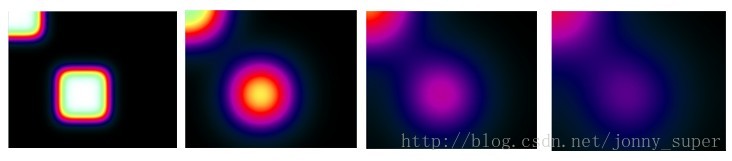
实验结果如下:下图显示按先后顺序的四个不同时刻的热量分布及变化情况。
主要程序代码如下:
/********************************************************************
* heatTransfer.cu
*********************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <cutil_inline.h>
#include "CPUAnim.h"
#define DIM 1024
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
struct DataBlock
{
unsigned char *outputBitmap;
float *dev_inSrc;
float *dev_outSrc;
float *dev_constSrc;
CPUAnimBitmap *bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
template< typename T >
void swap( T& a, T& b ) {
T t = a;
a = b;
b = t;
}
/************************************************************************/
/* Init CUDA */
/************************************************************************/
bool InitCUDA(void)
{
......
}
/************************************************************************/
__global__ void copyConstKernel(float *iPtr, const float *cPtr)
{
int x = threadIdx.x + blockIdx.x + blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
if (cPtr[offset] != 0)
{
iPtr[offset] = cPtr[offset];
}
}
__global__ void blendKernel(float* outSrc, const float* inSrc)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0)
{
left++;
}
if (x == DIM - 1)
{
right--;
}
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0)
{
top += DIM;
}
if (y == DIM -1)
{
bottom -= DIM;
}
outSrc[offset] = inSrc[offset] + SPEED * (inSrc[top] + inSrc[bottom]
+ inSrc[left] + inSrc[right] - 4 * inSrc[offset]);
}
__device__ unsigned char value( float n1, float n2, int hue )
{
......
}
__global__ void floatToColor( unsigned char *optr,
const float *outSrc )
{
......
}
void animGPU(DataBlock *d, int ticks)
{
cutilSafeCall(cudaEventRecord(d->start, 0));
dim3 blocks(DIM/16, DIM/16);
dim3 threads(16, 16);
CPUAnimBitmap *bitmap = d->bitmap;
for (int i=0; i<90; i++)
{
copyConstKernel<<<blocks, threads>>>(d->dev_inSrc, d->dev_constSrc);
blendKernel<<<blocks, threads>>>(d->dev_outSrc, d->dev_inSrc);
swap(d->dev_inSrc, d->dev_outSrc);
}
floatToColor<<<blocks, threads>>>(d->outputBitmap, d->dev_inSrc);
cudaMemcpy(bitmap->get_ptr(), d->outputBitmap, bitmap->image_size(), cudaMemcpyDeviceToHost);
cutilSafeCall(cudaEventRecord(d->stop, 0));
cutilSafeCall(cudaEventSynchronize(d->stop));
float elapsedTime;
cutilSafeCall(cudaEventElapsedTime(&elapsedTime, d->start, d->stop));
d->totalTime += elapsedTime;
++d->frames;
printf("Average Time per frame: %3.1f ms\n", d->totalTime/d->frames);
}
void animExit(DataBlock *d)
{
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
cutilSafeCall(cudaEventDestroy(d->start));
cutilSafeCall(cudaEventDestroy(d->stop));
}
/************************************************************************/
int main(int argc, char* argv[])
{
if(!InitCUDA()) {
return 0;
}
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
cutilSafeCall(cudaEventCreate(&data.start));
cutilSafeCall(cudaEventCreate(&data.stop));
cutilSafeCall(cudaMalloc((void**)&data.outputBitmap, data.bitmap->image_size()));
cutilSafeCall(cudaMalloc((void**)&data.dev_inSrc, data.bitmap->image_size()));
cutilSafeCall(cudaMalloc((void**)&data.dev_outSrc, data.bitmap->image_size()));
cutilSafeCall(cudaMalloc((void**)&data.dev_constSrc, data.bitmap->image_size()));
float *temp = (float*)malloc(bitmap.image_size());
for (int i=0; i<DIM*DIM; i++)
{
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x>300) && (x<600) && (y>301) && (y<601))
{
temp[i] = MAX_TEMP;
}
}
temp[DIM*100+100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM*700+100] = MIN_TEMP;
temp[DIM*300+300] = MIN_TEMP;
temp[DIM*200+700] = MIN_TEMP;
for (int y=800; y<900; y++)
{
for (int x=400; x<500; x++)
{
temp[x+y*DIM] = MIN_TEMP;
}
}
cutilSafeCall(cudaMemcpy(data.dev_constSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
for(int y=800; y<DIM; y++)
{
for (int x=0; x<200; x++)
{
temp[x+y*DIM] = MAX_TEMP;
}
}
cutilSafeCall(cudaMemcpy(data.dev_inSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice));
free(temp);
bitmap.anim_and_exit((void(*)(void*, int))animGPU, (void(*)(void*))animExit);
return 0;
}













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









