







4月16-20日,第七届Postgres Conference US大会(以下简称“PGConf US”)在美国纽约泽西城召开。PGConf US是美国最大的PostgreSQL教育和宣传平台,每届大会都将安排持续一个周的系列活动,包括培训、主题演讲及分组会议。中国PG分会代表一行赴美参与此次盛会,下面由瀚高软件研发工程师王亮为各位带来首日的会议速报。

在当前企业级数据爆发性增长的环境下,对结构化数据的数据量也在不断的增长,以至简单的单机数据库系统已经难于适应。分布式的数据库系统越来越多地被使用,随之数据库的多节点高可用性也变成了数据库领域最热门的话题之一。
第一天的会议基本上都是围绕着PostgreSQL的多节点用来谈起的。可见多节点下的高可用正在成为数据未来的发展方向之一。其中比较重要的两个内容如下:
01 第一章节
Modern PostgreSQL High Availability
会场现场,来自oneGre的创始人之一Alvaro Hernandez和开发者Pablo González Doval交替进行演讲。

Alvaro Hernandez认为当前很多的人对HA认识是错误的,或者说是过时的,甚至有些人认为stream replication就等同于HA。他给出了自己认为的真正的modern HA的概念如下图所示:
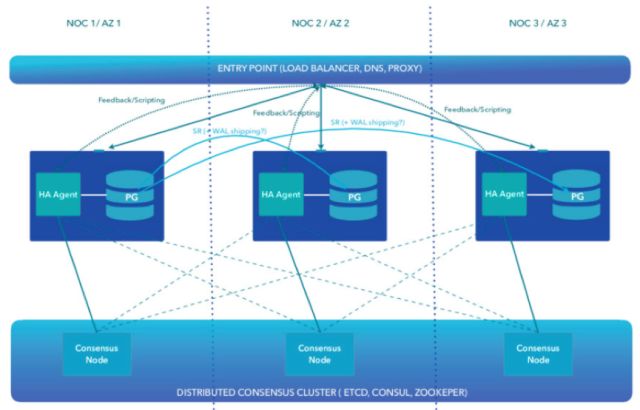
演讲后半段对PostgreSQL的HA的一些关键配置参数做了实战性的讲解。

在网络环境下,同步和异步模式各自面临的主要问题,需要根据自己的业务特点来进行选择。

在HA配置中,实际上同时存在着同步和异步的机制,这个也是最大限度的避免上面所说的单纯同步或者异步模式所带来的问题,并且这些问题会随着网络中节点数量的增加而被扩大。PostgreSQL在做replication的时候支持同步反馈节点数量的配置,即只是对配置中的replica接收方进行同步确认,其他的节点的接收反馈会被忽略。

PostgreSQL在客户端连接方面,并不支持任何cluster相关的参数,所以不能在客户端方面对PostgreSQL的网络拓扑结构做任何的知晓。
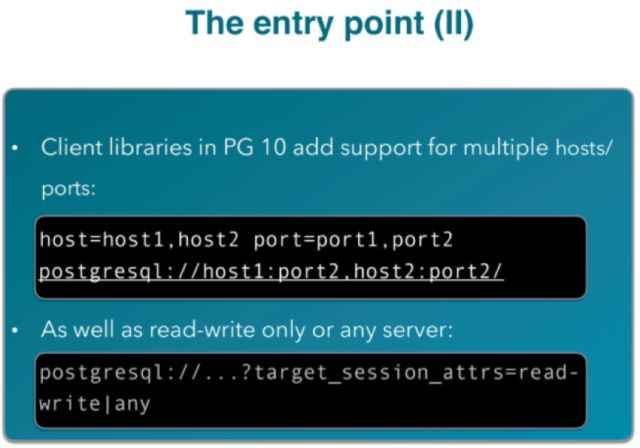
在PostgreSQL版本中,客户端的连接请求中加入了多个节点的支持,并且还对每一个节点提供一个读写的说明参数。这里实际上就让客户端在一定程度上面对数据库的网络拓扑情况有了一些认知。

在JDBC层面,同样的也提供了多个节点和每个节点的读写参数说明。

另外还有一些其他的第三方软件也能够帮助提供一个多节点的能够负载均衡的方案,但是性能上面肯定会受到比较大的影响,这个需要根据各自的需求场景来进行选择。

当然要想实现HA系统,自动化工具肯定是必须的,而且我们需要很多切换工作,需要很多的自动化工具来实现这些自动切换。此外固定的虚拟IP也是需要的,否者在切换了之后,原来角色的节点的IP也会改变,这样客户端还是知道的是老的IP,这样会产生很大的问题。
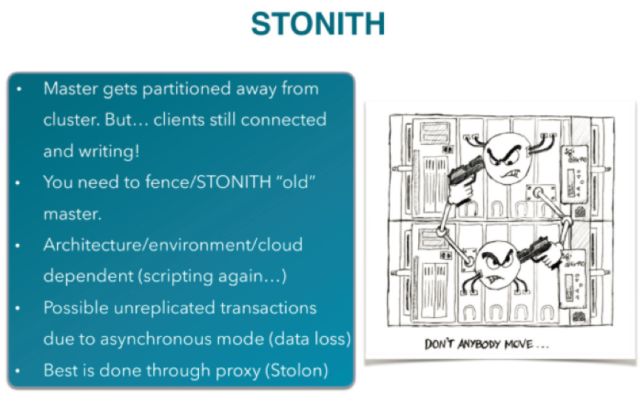
在主节点发生故障的时候,我们需要一个STONITH电源管理设备,进行主节点离线处理,否者会有脑裂的后果。

应用程序端需要支持对连接的重连,因为有时候正在处理请求的节点由于故障进行了切换,此时之前的连接已经不再存在,这是需要一个重连操作。

由于逻辑复制的种种限制,不要在HA的环境中使用逻辑复制。
02 第二章节
Aurora PostgreSQL Tutorial and Extended Deep Dive
Aurora数据库不同于现在普通的数据库cluster产品,普通的产品一般是每一个节点都各自拥有自己的存储系统,而Aurora提供了共享存储的节点组织模式,所有的数据库节点共享一份数据内容,这样做的基础实际上也依托了amazon发展了多年的强大的分布式存储平台,大部分关键的工作实际上都被底层文件系统所完成,上层数据库逻辑部分就可以采用更轻量级的方式来处理。
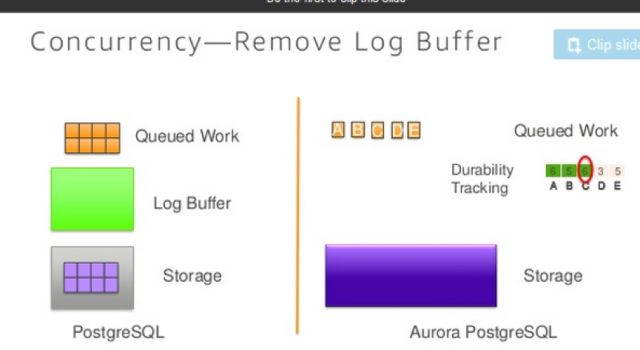
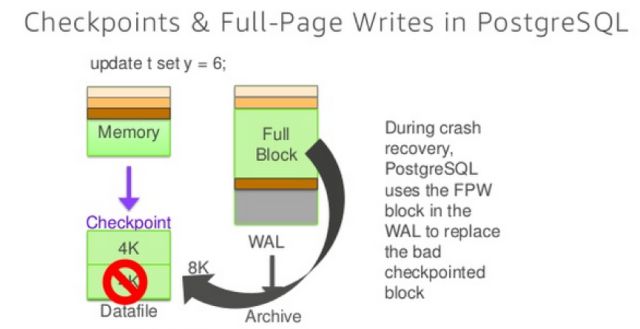
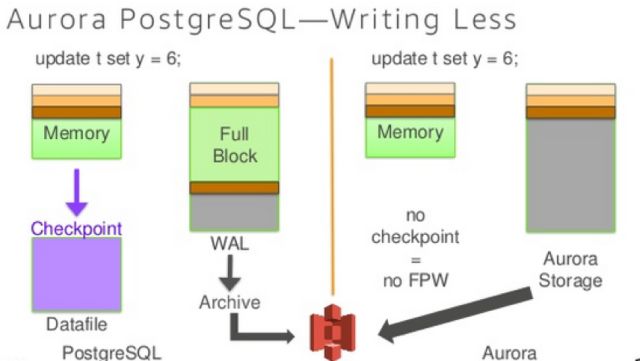
上面三个slide实际上就是说明Aurora用更少的写操作来提升数据库系统的性能,实际上可以认为Aurora就是一个日志存储系统,他对数据的存储只涉及到WAL日志的部分,数据部分都会被底层的文件系统所涵盖。
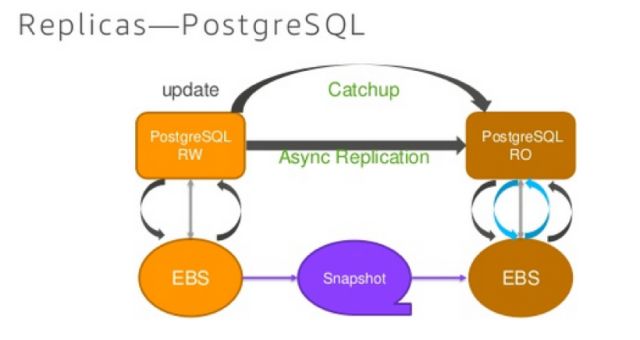
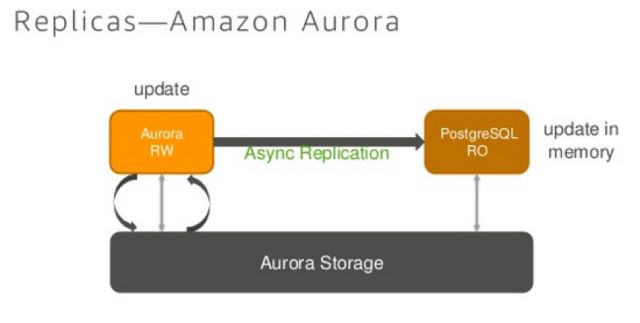
Aurora在主节点(读写节点)更新数据的时候,首先更新自己的磁盘数据的日志,然后会使用异步通知的方式通知所有的只读节点,告诉哪一个数据发生了变化,只读节点接收到通知以后查看自己的缓存中是否已经有了该数据,如果没有,那么什么也不会被处理,如果有,那么就会把自己的内存中相应的这个数据换出,然后再从磁盘加载到新的主节点更新完的数据。
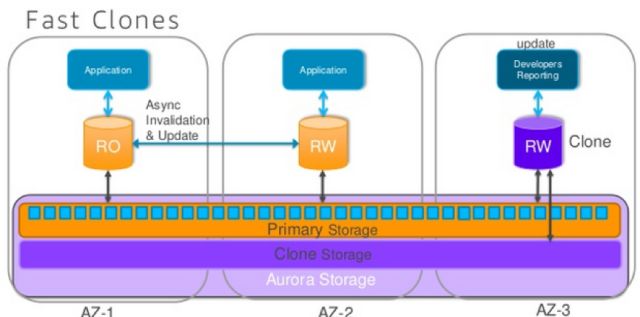
实际上每一个节点自己还是对应了一个实体的文件系统,只是这个文件系统是一个分布式文件系统的镜像,在写入节点写入数据之后,更新的数据会很快的复制到每一个分布式节点上面。
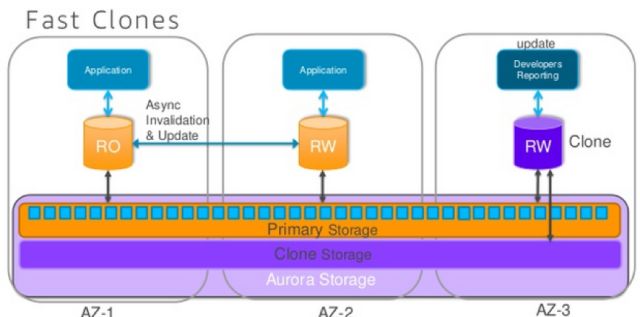
实际上每一个节点自己还是对应了一个实体的文件系统,只是这个文件系统是一个分布式文件系统的镜像,在写入节点写入数据之后,更新的数据会很快的复制到每一个分布式节点上面。
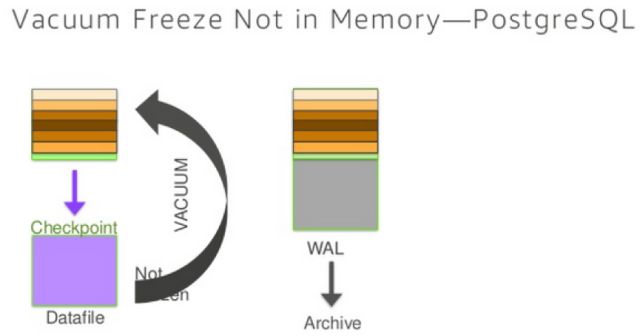
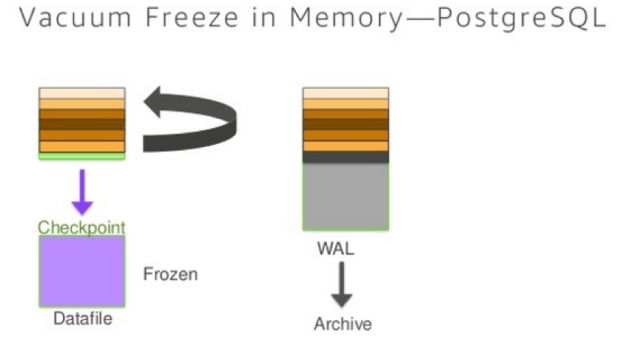
由于Aurora没有checkpoint机制,所以在vacuum的时候也不需要进行checkpointt操作,大大的提升了vacuum的性能。
03 第三章节
Mastering PostgreSQL Administration
来自 EnterpriseDB的Bruce Momjian进行的演讲,演讲内容主要集中在PostgreSQL的管理操作方面,基本上每一个主要的方面都有涉及,包括配置文件中重要的参数,关键的WAL日志机制,主备流复制机制,备份恢复机制等。因为内容非常详尽,并且演讲内容已经放到网上,可以通过如下地址进行访问:
会议首日主要是培训课程,以下为主要培训的课程简介:
一、谷歌云上的高可用PostgreSQL和Kubernetes
来自Google公司的两位软件技术人员Alexis Guajardo和Gabi Ferrara,给大家培训了如何通过使用谷歌的 Kubernetes 引擎和Cloud SQL快速开发基于Web的应用程序,并了解容器化应用程序管理和托管数据库服务。 Kubernetes 引擎通过简化应用程序和服务的部署,更新和管理,实现快速应用程序开发和迭代。 Cloud SQL可以让用户轻松设置,管理和管理他们在Google云端平台上的Postgres数据库。这个研讨会将帮助您在开发模因发电机的同时提高您的技能。
二、精通PosgreSQL管理
来自于PG全球开发者组织的联合创始人和核心团队成员Bruce Momjian,1996年开始从事PG方面的工作,2006年受雇于EnterpriseDB(EDB)。他给PG管理员带来了PG管理相关的各个方面,包括:安装,安全,文件结构,配置,报表,备份,日常维护,活动监控,磁盘空间计算和容灾。还介绍了如何控制主机的连通性,配置服务器,查找每个会话执行的查询,和每个数据库使用的磁盘空间。
三、 深入研究PostgreSQL身份验证方法
EDB公司首席架构师Abbas Butt带来了关于PG的身份验证相关的培训,包括访问,授权,身份验证和日志记录,与认证相关的PostgreSQL配置,PAM认证,Kerberos身份验证、LDAP身份验证、RADIUS身份验证等各种认证及加密方式。
四、 Migrating to PostgreSQL 迁移至PosgreSQL
由OpenSCG的CTO Jim Mlodgenski讲解,Jim有着20年对于数据敏感型应用和基础构架的开发经验,在加盟OpenSCG之前,Jim是StormDB(PostgreSQL-XC扩展公有云的解决方案)的CEO,在StormDB期间,Jim负责产品设计和所有的开发工作。现在有很多关键任务数据库迁移到PostgreSQL,这个讲座主要讲授了如何识别差异以及如何成功迁移应用程序,并通过使用包含SCT和DMS以及一些开源工具及AWS工具链进行示例迁移。
五、Patroni管理PostgreSQL集群
来自德国电子商务公司Zalando两位技术人员Alexey Klyukin 和 Alexander Kukushkin对如何使用Patroni管理PG集群进行了培训。Patroni是一个小型的Python守护进程,可以让用户通过几个简单的步骤创建基于热备份和流式复制的高可用性PostgreSQL集群。
六、CockroachDB 基础
纽约的本地公司Cockroach Labs为大家提供了他们公司的产品CockroachDB的培训,包括CockroachDB的设计和架构,涵盖数据分发,分布式事务,地理复制以及部署和操作基础知识。CockroachDB是一个分布式SQL数据库,可以在云-本地环境中运行。 CockroachDB旨在为具有地理分布用户和混合部署的应用提供支持。















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









