




逐渐更新ing
一、基础知识
1. 什么是NLP(自然语言处理)
- 定义:NLP 是人工智能的一个分支,致力于让计算机理解、处理和生成人类语言。
- 任务:
- 文本分类(如情感分析)
- 机器翻译
- 问答系统
- 文本生成
- 命名实体识别
- 等等。
- 技术发展:
- 早期:基于规则的方法(如正则表达式、语法分析)。
- 中期:基于统计的方法(如隐马尔可夫模型、条件随机场)。
- 现代:基于深度学习的方法(如 RNN、LSTM、Transformer)。
2. 什么是Transformer
- 定义:Transformer 是一种基于 自注意力机制(Self-Attention) 的神经网络架构,首次在 2017 年的论文《Attention is All You Need》中提出。
- 核心思想:
- 通过自注意力机制捕捉输入序列中不同位置之间的关系。
- 摒弃了传统的 RNN 和 CNN 结构,完全基于注意力机制。
- 优点:
- 并行计算效率高。
- 能够捕捉长距离依赖关系。
- 应用:
- Transformer 是 BERT 和 GPT 等模型的基础架构。
3. 什么是BERT(Bidirectional Encoder Representations from Transformers)
BERT 模型 主要利用了 Transformer 的 Encoder 部分,通过这种设计,BERT 能够将句子中的每个字(或词)转换为包含上下文信息的向量
- 定义:BERT 是一种基于 Transformer 的预训练语言模型,由 Google 在 2018 年提出。
- 核心特点:
- 双向编码:BERT 通过同时考虑上下文(左和右)来理解词语的语义。
-
a.预训练任务:
- 掩码语言模型(Masked Language Model, MLM):预测被掩码的词。
- 下一句预测(Next Sentence Prediction, NSP):判断两个句子是否连续。
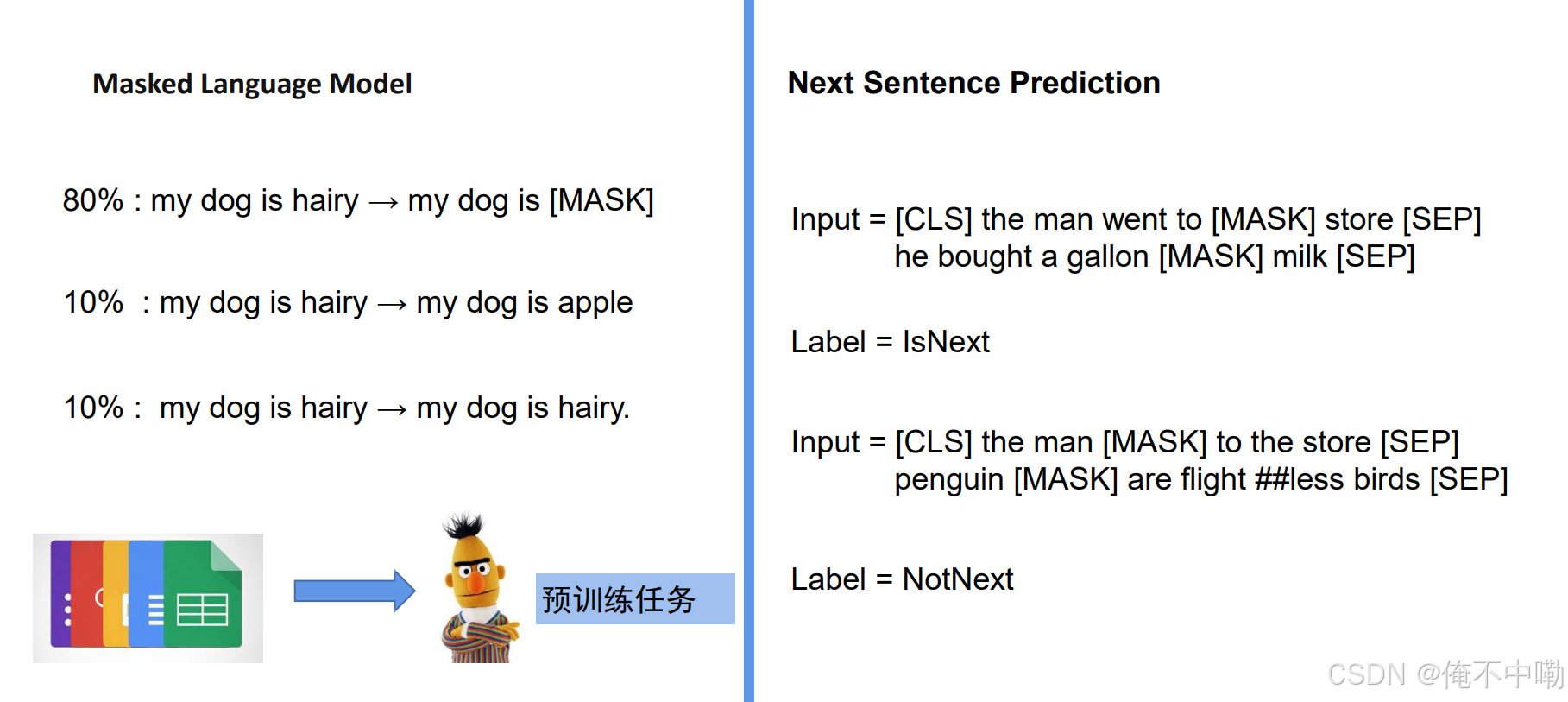
- MLM 通过掩码策略让模型学习上下文信息。
- NSP 通过判断句子关系让模型理解篇章结构。
- 应用:
- 文本分类
- 问答系统
- 命名实体识别
b.BERT 模型的核心结构
BERT 模型的核心结构包括以下几个主要组件:
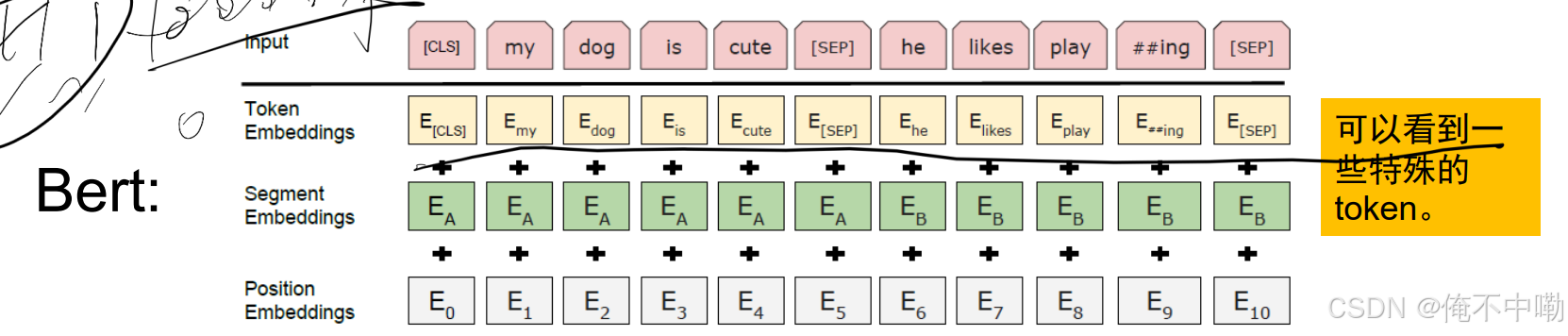
(1) Embedding 层
- 作用:将输入的文本数据(如单词或字)转换为向量表示。通过 Token Embeddings、Segment Embeddings 和 Position Embeddings 的组合,能够将输入文本转换为包含语义、句子关系和位置信息的向量表示。这种设计使得 BERT 在问答系统、文本匹配和自然语言推理等任务中表现出色
- 组成:
- Token Embedding:将每个词转换为固定维度的向量。
- Position Embedding:为每个词添加位置信息,解决 Transformer 无法直接处理序列顺序的问题。
- Segment Embedding:区分不同句子(如句子 A 和句子 B),用于处理句子对任务。
- 输出:将上述三种嵌入(都转换为比如说768维的)相加,得到最终的输入向量。
[CLS]
图中的**
dog** 和 **[CLS]** 都是 Token。以下是关于 Token 和 **[CLS]** 的原理和作用的详细解释:
[CLS]是 BERT 模型中的一个特殊 Token,用于聚合整个序列的全局信息,常用于分类任务和表示整个序列。
1. 什么是 Token?
Token 是 BERT 模型对输入文本进行分割后的最小单位。它可以是单词、符号或子词(subword)。
示例:
单词
dog是一个 Token。特殊符号
[CLS]和[SEP]也是 Token。作用:Token 是 BERT 模型处理文本的基本单位,每个 Token 都会被转换为对应的向量表示(Token Embedding)。
2.
[CLS]的原理和作用**(1) 什么是
[CLS]?**
**
[CLS]** 是 BERT 模型中的一个 特殊 Token,全称为 Classification Token。位置:通常放在输入序列的开头。
**(2)
[CLS]的原理**
全局信息聚合:
在 BERT 模型中,
[CLS]会通过多层 Transformer Encoder 的处理,逐步聚合整个输入序列的上下文信息。由于
[CLS]位于序列的开头,它在自注意力机制中可以与序列中的所有 Token 进行交互,从而捕捉全局信息。输出向量:
在模型的最后一层,
[CLS]对应的输出向量会被用作整个序列的表示。**(3)
[CLS]的作用**
分类任务:
在文本分类任务中,
[CLS]的输出向量会被输入到一个分类器中,用于预测类别。例如,在情感分析任务中,
[CLS]的输出向量可以用于判断文本的情感是正面还是负面。表示整个序列:
[CLS]的输出向量可以看作是对整个输入序列的汇总表示,常用于需要全局信息的任务(如文本分类、问答系统等)。其他任务:
在句子对任务(如文本匹配、自然语言推理)中,
[CLS]的输出向量也可以用于判断两个句子之间的关系。
(2) BERT Layers(BERT 层)
- 组成:每个 BERT 层包含两个核心模块:
- Multi-Head Attention(多头注意力机制):
- 通过多个注意力头并行计算,捕捉输入序列中不同位置的关系。
- 每个注意力头独立计算注意力权重,最后将结果拼接并线性变换。
- Feed Forward(前馈神经网络):
- 通过两层全连接网络(通常使用 ReLU 激活函数)进一步提取特征
- Add & Norm(残差连接和层归一化):
- 残差连接将输入直接加到输出上,缓解梯度消失问题。
- 层归一化对输出进行归一化,稳定训练过程。
- 重复次数:BERT 模型通常包含多个 BERT 层(如 B



 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3211
3211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









