







一、逻辑回归
1.1 逻辑回归中的分类问题
分类问题的例子有:将电子邮件识别为垃圾邮件或非垃圾邮件;确定肿瘤是恶行还是良性。
如果我们继续用线性回归的模型进行肿瘤的预测,再增加几个数据点,生成的线性模型与数据不匹配:

因此,我们便引入了逻辑回归。
1.2 逻辑回归的逻辑表达
对于分类任务,我们可以从线性回归模型开始,𝑓𝐰,𝑏(𝐱(𝑖))=𝐰⋅𝐱(𝑖)+𝑏,然而,我们希望分类模型的预测值介于0和1之间,考虑将输出的取值范围控制在(0,1)之间。以此,逻辑回归需要在线性回归的基础上,再进行一次映射,可以使用将所有输入值映射到0或1之间的值的sigmoid函数。
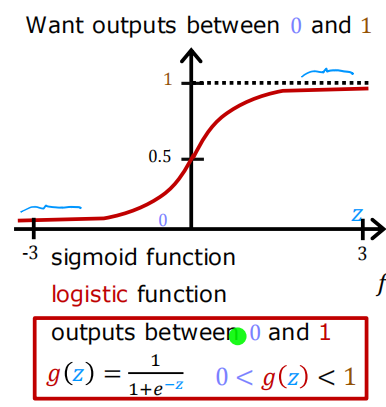
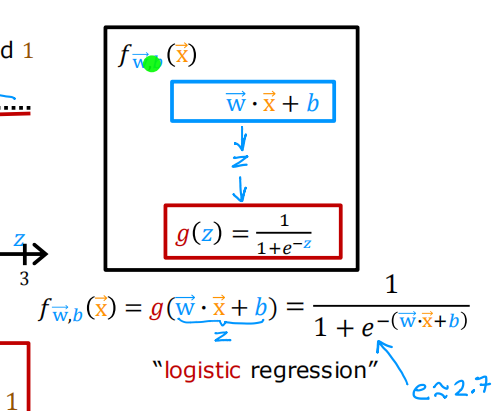
1.3 逻辑回归的决策边界
对于逻辑回归,模型表示为:



二分类为例,通常以0.5 为阈值。

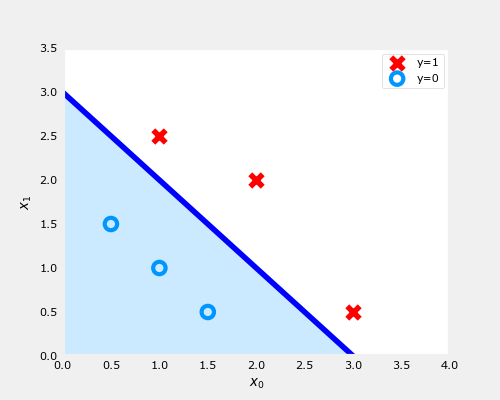
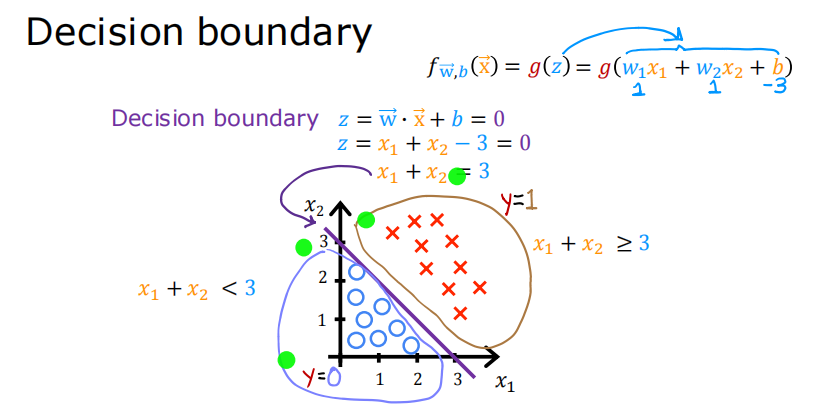
在上面的图中,蓝色线表示线𝑥0+𝑥1−3=0,它应该在3处与x1轴相交(如果我们设置𝑥1 = 3, 𝑥0=0),x0轴为3(如果我们设置𝑥1 = 0, 𝑥0 = 3).
阴影区域表示−3+𝑥0+𝑥1<0 . 线上方的区域为−3+𝑥0+𝑥1>0 .
阴影区域(线下)中的任何点都被分类为𝑦=0 . 线路上或上方的任何点均被分类为𝑦=1.该曲线将样本数据分割在两侧,一侧代表一类事物这条线被称为“决策边界”。
二、逻辑回归中的损失函数和代价函数
2.1 平方误差损失函数还能用吗?
平方误差函数适用于线性回归问题,其有一个特点,即遵循成本的导数可以达到最小值。然而我们在逻辑回归中使用平方误差损失函数,得到的成本曲面图为:
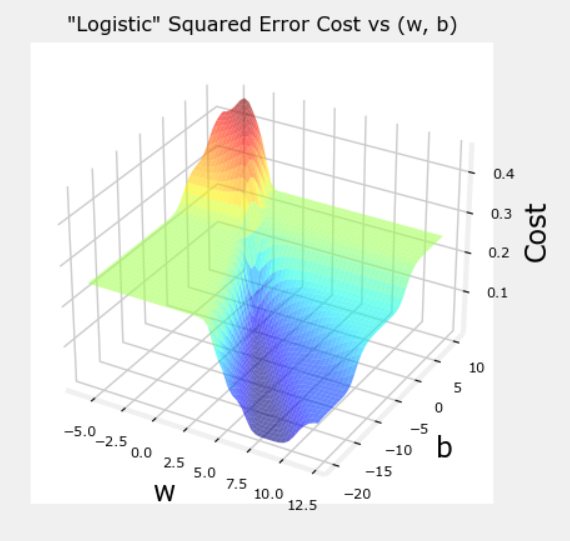
并不是光滑下降,所以该分类任务中并不适合使用平方误差函数。
逻辑回归中,更需要使用适合分类任务的损失函数,我们需要的损失函数为:

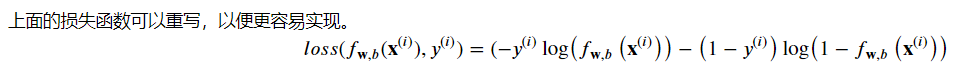
该损失函数的定义特征是它使用了两条单独的曲线。一个用于当目标为零或(𝑦=0y=0)时的情况,另一个用于目标为一(𝑦=1y=1)时:
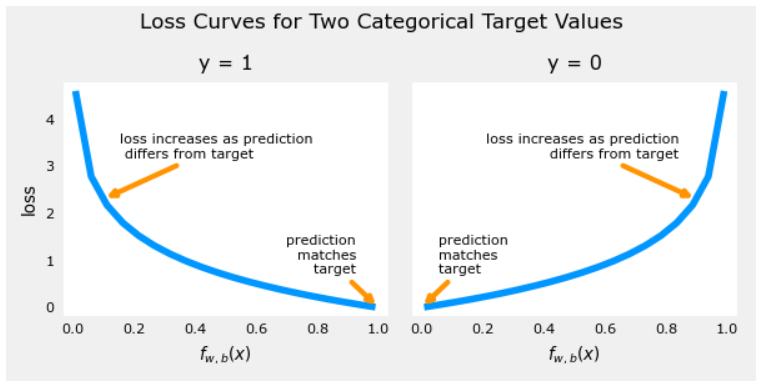
2.2 代价函数表示
损失函数只适用于一个示例。
将损失合并为成本,构造代价函数。

代价函数:
def compute_cost_logistic(X, y, w, b):
"""
Computes cost
Args:
X (ndarray (m,n)): Data, m examples with n features
y (ndarray (m,)) : target values
w (ndarray (n,)) : model parameters
b (scalar) : model parameter
Returns:
cost (scalar): cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i],w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i)
cost = cost / m
return cost
三、逻辑回归的梯度下降
3.1 逻辑回归损失函数的梯度计算
逻辑回归中梯度下降:

步骤如下:
def compute_gradient_logistic(X, y, w, b):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
Returns
dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar) : The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape
dj_dw = np.zeros((n,)) #(n,)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar
err_i = f_wb_i - y[i] #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar
dj_db = dj_db + err_i
dj_dw = dj_dw/m #(n,)
dj_db = dj_db/m #scalar
return dj_db, dj_dw 3.2 执行批次梯度下降

def gradient_descent(X, y, w_in, b_in, alpha, num_iters):
"""
执行批次梯度下降
Args:
X (ndarray (m,n) : Data, m examples with n features
y (ndarray (m,)) : target values
w_in (ndarray (n,)): Initial values of model parameters
b_in (scalar) : Initial values of model parameter
alpha (float) : Learning rate
num_iters (scalar) : number of iterations to run gradient descent
Returns:
w (ndarray (n,)) : Updated values of parameters
b (scalar) : Updated value of parameter
"""
# An array to store cost J and w's at each iteration primarily for graphing later
J_history = []
w = copy.deepcopy(w_in) #avoid modifying global w within function
b = b_in
for i in range(num_iters):
# Calculate the gradient and update the parameters
dj_db, dj_dw = compute_gradient_logistic(X, y, w, b)
# Update Parameters using w, b, alpha and gradient
w = w - alpha * dj_dw
b = b - alpha * dj_db
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
J_history.append( compute_cost_logistic(X, y, w, b) )
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4d}: Cost {J_history[-1]} ")
return w, b, J_history #return final w,b and J history for graphing
四、过拟合与正则化
4.1 过拟合含义
目标函数的数学模型如果阶数太高或太复杂,很容易过拟合。这时,虽然在训练集的样本点上拟合情况很好,但是在未知的测试集里可能效果就很差。这就是过拟合现象。
当变量过多时,训练出来的假设能很好地拟合训练集,所以代价函数实际上可能非常接近于0,但得到的曲线为了千方百计的拟合数据集,导致它无法泛化到新的样本中,无法预测新样本数据。
泛化
指一个假设模型应用到新样本的能力。
以下为欠拟合、拟合适中、过拟合的例子:

4.2 解决过拟合方法
使用更多的数据集
减少特征数量
正则化,可以保留所有的特征,但是正则化会惩罚参数过大的情况,即避免了某个参数非常大的情况。
4.3 正则化
线性回归和逻辑回归的成本函数差异显著,但在方程中加入正则化是一样的。
正则线性回归的成本函数:
def compute_cost_linear_reg(X, y, w, b, lambda_ = 1):
"""
Computes the cost over all examples
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns:
total_cost (scalar): cost
"""
m = X.shape[0]
n = len(w)
cost = 0.
for i in range(m):
f_wb_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dot
cost = cost + (f_wb_i - y[i])**2 #scalar
cost = cost / (2 * m) #scalar
reg_cost = 0
for j in range(n):
reg_cost += (w[j]**2) #scalar
reg_cost = (lambda_/(2*m)) * reg_cost #scalar
total_cost = cost + reg_cost #scalar
return total_cost #scalar正则线性回归的梯度函数:
def compute_gradient_linear_reg(X, y, w, b, lambda_):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns:
dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar): The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape #(number of examples, number of features)
dj_dw = np.zeros((n,))
dj_db = 0.
for i in range(m):
err = (np.dot(X[i], w) + b) - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err * X[i, j]
dj_db = dj_db + err
dj_dw = dj_dw / m
dj_db = dj_db / m
for j in range(n):
dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]
return dj_db, dj_dw正则逻辑回归的成本函数:
def compute_cost_logistic_reg(X, y, w, b, lambda_ = 1):
"""
Computes the cost over all examples
Args:
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns:
total_cost (scalar): cost
"""
m,n = X.shape
cost = 0.
for i in range(m):
z_i = np.dot(X[i], w) + b #(n,)(n,)=scalar, see np.dot
f_wb_i = sigmoid(z_i) #scalar
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i) #scalar
cost = cost/m #scalar
reg_cost = 0
for j in range(n):
reg_cost += (w[j]**2) #scalar
reg_cost = (lambda_/(2*m)) * reg_cost #scalar
total_cost = cost + reg_cost #scalar
return total_cost #scalar正则逻辑回归的梯度函数:
def compute_gradient_logistic_reg(X, y, w, b, lambda_):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
lambda_ (scalar): Controls amount of regularization
Returns
dj_dw (ndarray Shape (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar) : The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape
dj_dw = np.zeros((n,)) #(n,)
dj_db = 0.0 #scalar
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar
err_i = f_wb_i - y[i] #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar
dj_db = dj_db + err_i
dj_dw = dj_dw/m #(n,)
dj_db = dj_db/m #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]
return dj_db, dj_dw















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









