






Cassandra
1.特点介绍
面向列的NoSQL数据库有HBase。存储jsaon文本的NoSQL有 MongoDB。存储key-value键值对的有Redis。
关系型数据库:
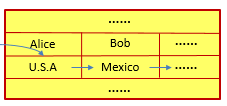
非关系型数据库:
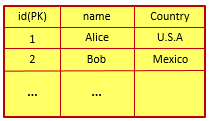
Cassandra是NoSQL数据库 , 是一个面向列的列存储数据库,特点如下:
- 可以线性扩展, 通过增加群集中的节点数量提高吞吐量
- 每个节点都有相同数据的副本,可容错, 每个节点是独立的,同时与其他节点互连。集群中的所有节点都扮演着相同的角色, 每个节点都可以接受读取和写入请求
- 支持事务,诸如原子性,一致性,隔离和持久性(ACID)等属性。
- 数据分发简单, 可以灵活地通过在多个数据中心复制数据来分发所需的数据。
- 执行快速写入,可以存储数百TB的数据,而不会牺牲读取效率。
2.组成部分
Cassandra的主要组成部分主要有:
-
节点(Node):Cassandra节点是存储数据的地方。
-
数据中心(Data center):数据中心是相关节点的集合。
-
集群(Cluster):集群是包含一个或多个数据中心的组件。
-
提交日志(Commit log):在Cassandra中,提交日志是一个崩溃恢复机制。 每个写入操作都将写入提交日志。
-
存储表(Mem-table):内存表是内存记录着最近所做的修改。 提交日志后,数据将被写入内存表。 有时,对于单列系列,将有多个内容表。
-
SSTable:SSTable在磁盘上记录着Cassandra所承载的绝大部分数据,当内容达到阈值时,它是从内存表刷新数据的磁盘文件。在SSTable内部记录着一系列根据键排列的一系列键值对
-
布鲁姆过滤器(Bloom filter):这些只是快速,非确定性的,用于测试元素是否是集合成员的算法。 它是一种特殊的缓存。 每次查询后都会访问Bloom过滤器。
3.写操作/读操作
在写操作中,首先提交日志(Commit log)捕获每次写操作,接着将其存储在内存表(memtable)中。当内存表已满时,数据将被写入SSTable数据文件。 所有写入在整个集群中自动分区和复制。 Cassandra定期整合SSTables,丢弃不必要的数据。

在读操作中,Cassandra从mem-table中获取值,并通过bloom过滤器找到包含所需数据的适当SSTable。 每个SSTable都有一个Bloom Filter,以用来判断与其关联的SSTable是否包含当前查询所请求的一条或多条数据。如果是,Cassandra将尝试从该SSTable中取出数据;如果不是,Cassandra则会忽略该SSTable,以减少不必要的磁盘访问。
4.数据模型
提供了数据过期功能, 在数据插入期间,以秒为单位指定“ttl”值,这段时间后,数据会被自动清除
-
集群: Cassandra按照环形格式将节点排列在集群中,并为它们分配数据。
-
键空间(keyspace): 是Cassandra中数据的最外层容器,有三个属性:
-
复制因子 - 它指定集群中的机器数量,将接收相同数据的副本。
-
副本放置策略 -有简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)等策略。
-
列族 - 键空间是一个或多个列族的列表的容器。列族表示数据的结构。每个键空间至少有一个,通常是许多列族。是一系列列的集合并且每一个列都会有一个key

列:是Cassandra的基本数据结构,具有三个值,即键或列名称,值和时间戳。
-
5.安装
python2.7 JDK8 Cassandra3.11.6
在配置conf时,不要自己写,去掉注释即可
6.基本操作
键空间
DURABLE_WRITES:使用此选项,可以指示Cassandra是否对当前KeySpace的更新使用commitlog
| 策略名称 | 描述 |
|---|---|
| SimpleStrategy | 为集群指定简单的复制因子。 |
| NetworkTopologyStrategy | 使用此选项,可以单独为每个数据中心设置复制因子。 |
cassandra -R
cqlsh启动
//创建一个名为tutorial01的键空间,并使用简单策略,复制因子为3
CREATE KEYSPACE tutorial01 WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
//验证
DESCRIBE tutorial01;
//查看所有的键空间
DESCRIBE keyspace;
//使用键空间
use tutorial01;
//修改键空间tutorial01,使用网络拓扑策略,复制因子为1,禁用DURABLE_WRITES(持久写入)
//Cassandra中的键名称不能更改。
ALTER KEYSPACE tutorial01
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = false;
//删除键空间tutorial01
DROP KEYSPACE tutorial01;
表(列家族)
//使用键空间tutorial01,并创建表
USE tutorial01;
CREATE TABLE student(
student_id int PRIMARY KEY,
student_name text,
student_city text,
student_fees varint,
student_phone varint
);
//验证
SELECT * FROM student;
//修改表,加入一列文本类型的student_email
ALTER TABLE student ADD student_email text;
//删除3列
ALTER TABLE student DROP (student_email, student_phone,student_fees);
//删除表
DROP TABLE student;
//验证
DESCRIBE COLUMNFAMILIES;
//向表中插入三行数据
INSERT INTO student (student_id,student_name,student_city)
VALUES(1,'Maxsu','NY');
if not exists;
INSERT INTO student (student_id,student_name,student_city)
VALUES(2,'Jack','DC');
INSERT INTO student (student_id,student_name,student_city)
VALUES(3,'kyle','LA');
//截断操作(删除表中所有数据)
TRUNCATE student;
//为student表中的student_name列创建索引,创建索引后可以通过索引进行查找
CREATE INDEX name ON student (student_name);
//批量操作增删改查
//1.添加两条数据;2.删除id为2的行;3.更新id为3的行的名字和城市
BEGIN BATCH
INSERT INTO student(student_id,student_name,student_city)
values(4, 'Rose', 'DE');
INSERT INTO student(student_id,student_name,student_city)
values(5, 'Green', 'SC');
UPDATE student SET student_name='Kid',student_city='GA' WHERE student_id=3;
DELETE student_fees FROM student WHERE student_id=2;
APPLY BATCH;
删除/读取补充
//删除student表中的指定行的指定列的数据
DELETE student_name FROM student WHERE student_id=2;
//读取表中指定的两列
SELECT student_id, student_name FROM student;
//读取student表中id为2的行
SELECT * FROM student WHERE student_id=2
7. CQL数据类
cassandra中集合类型不能做主键,不能建索引
-
set集合:用于存储一组元素的数据类型。集合的元素将按排序顺序返回。
-
不允许null值,key重复会被更新
-
使用列表中元素的索引来获取列表数据类型的值
//创建 CREATE TABLE data1 (name text PRIMARY KEY, phone set<varint>); //插入值 INSERT INTO data1 (name, phone) VALUES ('aa',{12345,54321}); //向set集合中添加 UPDATE data1 ... SET phone = phone + {9848022330} ... where name = 'aa'; //删除指定元素 UPDATE data1 set phone=phone-{12345} where name='aa'; -
Map集合:用于存储元素的键值对的数据类型。
//创建 CREATE TABLE data2 (name text PRIMARY KEY, address map<timestamp,text>); //插入值 INSERT INTO data2 (name, address) VALUES ('bb', {'home' : 'nanjing' , 'office' : 'suning' } ); //向Map集合中添加 UPDATE data2 ... SET address = address+{'office':'xiaomi'} ... WHERE name = 'bb'; //删除指定元素 delete address[‘office’] from data2 where name = 'bb‘; //嵌套map complex map<text,frozen<map<text,text>>> -
list集合:将保持元素的顺序,并且值将被多次存储。
-
不允许null值,key重复会被更新
//创建 CREATE TABLE data3 (name text PRIMARY KEY, email list<text>); //插入值 INSERT INTO data3 (name, email) VALUES ('cc', ['abc@gmail.com','cba@yahoo.com']) //向列表中添加 UPDATE data3 ... SET email = email +['xyz@gmail.com','xyz@qq.com'] ... where name = 'cc'; //删除指定元素 UPDATE data3 set phone=phone-['xyz@qq.com'] where name='cc';【注】: Cassandra 会按照set内数据类型进行排序返回查询结果,如果希望按照插入序返回结果,请使用list.















 1386
1386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









