







CUDA Memory Model
对于程序员来说,memory可以分为下面两类:
- Programmable:我们可以灵活操作的部分。
- Non-programmable:不能操作,由一套自动机制来达到很好的性能。
在CPU的存储结构中,L1和L2 cache都是non-programmable的。对于CUDA来说,programmable的类型很丰富:
- Registers
- Shared memory
- Local memory
- Constant memory
- Texture memory
- Global memory
下图展示了memory的结构,他们各自都有不用的空间、生命期和cache。
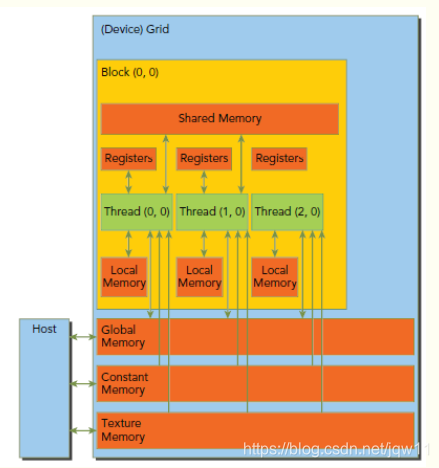
Global Memory
global Memory是空间最大,latency最高,GPU最基础的memory。“global”指明了其生命周期。任意SM都可以在整个程序的生命期中获取其状态。global中的变量既可以是静态也可以是动态声明。可以使用__device__修饰符来限定其属性。global memory的分配就是之前频繁使用的cudaMalloc,释放使用cudaFree。global memory驻留在devicememory,可以通过32-byte、64-byte或者128-byte三种格式传输。这些memory transaction必须是对齐的,也就是说首地址必须是32、64或者128的倍数。优化memory transaction对于性能提升至关重要。当warp执行memory load/store时,需要的transaction数量依赖于下面两个因素:
- Distribution of memory address across the thread of that warp 就是前文的连续
- Alignment of memory address per transaction 对齐
一般来说,所需求的transaction越多,潜在的不必要数据传输就越多,从而导致throughput efficiency降低。
对于一个既定的warp memory请求,transaction的数量和throughput efficiency是由CC版本决定的。对于CC1.0和1.1来说,对于global memory的获取是非常严格的。而1.1以上,由于cache的存在,获取要轻松的多。
下面代码是通过可以通过32-byte、64-byte或者128-byte三种格式传输,优化传输效率:
template <typename T>
__device__ inline uint32_t pack_uint8x4(T x, T y, T z, T w){
uchar4 uint8x4;
uint8x4.x = static_cast<uint8_t>(x);
uint8x4.y = static_cast<uint8_t>(y);
uint8x4.z = static_cast<uint8_t>(z);
uint8x4.w = static_cast<uint8_t>(w);
return load_as<uint32_t>(&uint8x4);
}
template <unsigned int N>
__device__ inline void store_uint8_vector(uint8_t *dest, const uint32_t *ptr);
template <>
__device__ inline void store_uint8_vector<1u>(uint8_t *dest, const uint32_t *ptr){
dest[0] = static_cast<uint8_t>(ptr[0]);
}
template <>
__device__ inline void store_uint8_vector<2u>(uint8_t *dest, const uint32_t *ptr){
uchar2 uint8x2;
uint8x2.x = static_cast<uint8_t>(ptr[0]);
uint8x2.y = static_cast<uint8_t>(ptr[0]);
store_as<uchar2>(dest, uint8x2);
}
template <>
__device__ inline void store_uint8_vector<4u>(uint8_t *dest, const uint32_t *ptr){
store_as<uint32_t>(dest, pack_uint8x4(ptr[0], ptr[1], ptr[2], ptr[3]));
}
template <>
__device__ inline void store_uint8_vector<8u>(uint8_t *dest, const uint32_t *ptr){
uint2 uint32x2;
uint32x2.x = pack_uint8x4(ptr[0], ptr[1], ptr[2], ptr[3]);
uint32x2.y = pack_uint8x4(ptr[4], ptr[5], ptr[6], ptr[7]);
store_as<uint2>(dest, uint32x2);
}
template <>
__device__ inline void store_uint8_vector<16u>(uint8_t *dest, const uint32_t *ptr){
uint4 uint32x4;
uint32x4.x = pack_uint8x4(ptr[ 0], ptr[ 1], ptr[ 2], ptr[ 3]);
uint32x4.y = pack_uint8x4(ptr[ 4], ptr[ 5], ptr[ 6], ptr[ 7]);
uint32x4.z = pack_uint8x4(ptr[ 8], ptr[ 9], ptr[10], ptr[11]);
uint32x4.w = pack_uint8x4(ptr[12], ptr[13], ptr[14], ptr[15]);
store_as<uint4>(dest, uint32x4);
}
例子代码见:
https://github.com/Alexjqw/cuda-learning
参考:https://www.cnblogs.com/1024incn/p/4564726.html














 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









