










基础环境
基础环境使用镜像:registry.cn-hangzhou.aliyuncs.com/allen135681/easyml:ubuntu18.04-nvidia_cuda10.0-base-Miniconda3-py39_4.9.2_paddlepaddle2.0.1_paddlehub2.0.4_paddlenlp2.0.0rc10 pyin paddle
额外安装:
pip list|grep "paddle\|cv"
opencv-python 4.2.0.32
paddlehub 2.0.4
paddlepaddle 2.0.1
代码
hub install humanseg_server==1.2.1humanseg_server_test.py
http://nn.wenming.cn/wmcj/201511/t20151123_2140790.html 网上随意找的图片

图片视频语义分割 人像图像分割
import cv2
import paddlehub as hub
human_seg = hub.Module(name='humanseg_server')
im = cv2.imread('1.jpg')
res = human_seg.segment(images=[im], visualization=True, output_dir="image_segment_output") #visualization=True可以用于查看超分图片效果,可设置为False提升运行速度。
human_seg.video_segment('./1.mp4', save_dir="video_segment_output")
human_seg.save_inference_model('./MODEL')图片和视频里的人像都被分割出来了。

图片视频语义分割 人像图像分割
图片视频语义分割 人像图像分割
分析
DeepLabv3+ 是Google DeepLab语义分割系列网络的最新作,其前作有 DeepLabv1, DeepLabv2, DeepLabv3。在最新作中,作者通过encoder-decoder进行多尺度信息的融合,同时保留了原来的空洞卷积和ASSP层, 其骨干网络使用了Xception模型,提高了语义分割的健壮性和运行速率,在 PASCAL VOC 2012 dataset取得新的state-of-art performance。该PaddleHub Module使用百度自建数据集进行训练,可用于人像分割,支持任意大小的图片输入。
高精度模型,适用于服务端GPU且背景复杂的人像场景, 模型结构为Deeplabv3+/Xcetion65, 模型大小为158M,网络结构如图:

其他
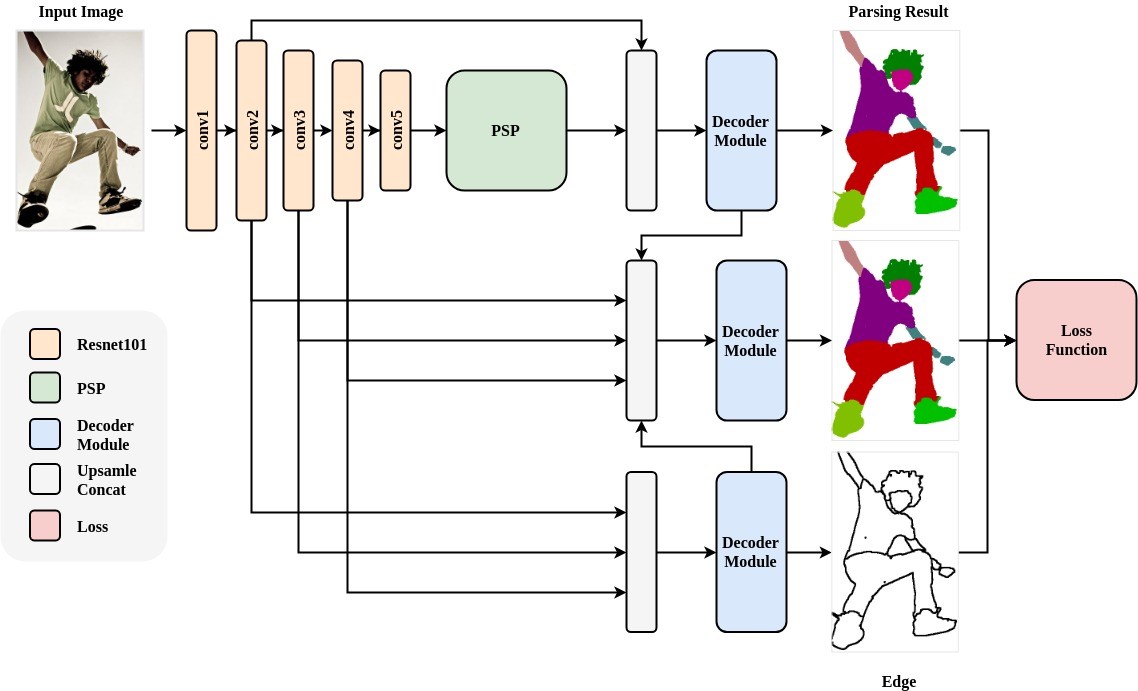
人体解析(Human Parsing)是细粒度的语义分割任务,其旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征,全局上下文信息和边缘细节,端到端地训练学习人体解析任务。该结构针对Intersection over Union指标进行针对性的优化学习,提升准确率。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名。该PaddleHub Module采用ResNet101作为骨干网络,接受输入图片大小为473x473x3。
hub install ace2p==1.1.0import paddlehub as hub
import cv2
human_parser = hub.Module(name="ace2p")
result = human_parser.segmentation(images=[cv2.imread('./2.jpg')],
paths=None,
batch_size=1,
use_gpu=False,
output_dir='ace2p_output',
visualization=True)

模型介绍
参考
https://www.paddlepaddle.org.cn/hubdetail?name=humanseg_server&en_category=ImageSegmentation
https://www.paddlepaddle.org.cn/hubdetail?name=ace2p&en_category=ImageSegmentation
















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











