







In the previous parts of this series, we saw some C++11 Synchronization techniques: locks, lock guards and atomic references.
In this small post, I will present the results of a little benchmark I did run to compare the different techniques. In this benchmark, the critical section is a single increment to an integer. The critical section is protected using three techniques:
- A single std::mutex with calls to lock() and unlock()
- A single std::mutex locked with std::lock_guard
- An atomic reference on the integer
The tests have been made with 1, 2, 4, 8, 16, 32, 64 and 128 threads. Each test is repeated 5 times.
The results are presented in the following figure:
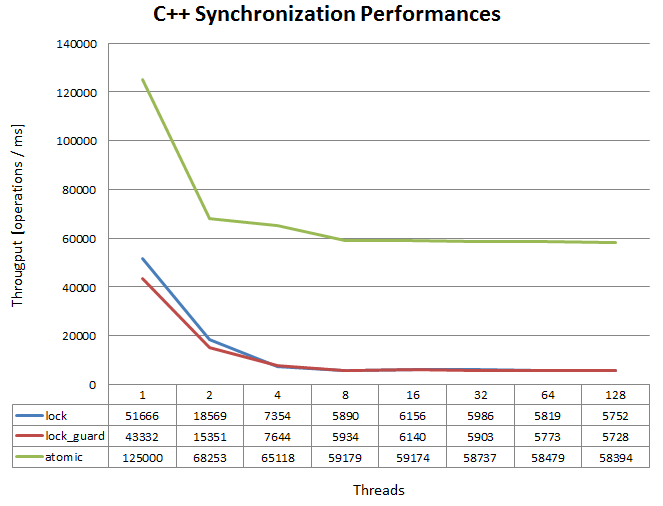
C++11 Synchronization Benchmark Result
As expected, the mutex versions are much slower than the atomic one. An interesting point is that the the atomic version has not a very good scalability. I would have expected that the impact of adding one thread would not be that high.
I’m also surprised that the lock guard version has a non-negligible overhead when there are few threads.
In conclusion, do not locks when all you need is modifying integral types. For that, std::atomic is much faster. Good Lock-Free algorithms are almost always faster than the algorithms with lock.
Code for benchmark:
#include <chrono>
#include <iostream>
#include <vector>
#include <thread>
#include <atomic>
#include <mutex>
typedef std::chrono::high_resolution_clock Clock;
typedef std::chrono::milliseconds milliseconds;
#define OPERATIONS 250000
#define REPEAT 5
template<int Threads>
void bench_lock() {
std::mutex mutex;
unsigned long throughput = 0;
for (int i = 0; i < REPEAT; ++i) {
int counter = 0;
std::vector<std::thread> threads;
Clock::time_point t0 = Clock::now();
for (int i = 0; i < Threads; ++i) {
threads.push_back(std::thread([&]() {
for (int i = 0; i < OPERATIONS; ++i) {
mutex.lock();
++counter;
mutex.unlock();
}
}));
}
for (auto& thread : threads) {
thread.join();
}
Clock::time_point t1 = Clock::now();
milliseconds ms = std::chrono::duration_cast<milliseconds>(t1 - t0);
throughput += (Threads * OPERATIONS) / ms.count();
}
std::cout << "lock with " << Threads << " threads throughput = " << (throughput / REPEAT) << std::endl;
}
template<int Threads>
void bench_lock_guard() {
std::mutex mutex;
unsigned long throughput = 0;
for (int i = 0; i < REPEAT; ++i) {
int counter = 0;
std::vector<std::thread> threads;
Clock::time_point t0 = Clock::now();
for (int i = 0; i < Threads; ++i) {
threads.push_back(std::thread([&]() {
for (int i = 0; i < OPERATIONS; ++i) {
std::lock_guard<std::mutex> guard(mutex);
++counter;
}
}));
}
for (auto& thread : threads) {
thread.join();
}
Clock::time_point t1 = Clock::now();
milliseconds ms = std::chrono::duration_cast<milliseconds>(t1 - t0);
throughput += (Threads * OPERATIONS) / ms.count();
}
std::cout << "lock_guard with " << Threads << " threads throughput = " << (throughput / REPEAT) << std::endl;
}
template<int Threads>
void bench_atomic() {
std::mutex mutex;
unsigned long throughput = 0;
for (int i = 0; i < REPEAT; ++i) {
std::atomic<int> counter;
counter.store(0);
std::vector<std::thread> threads;
Clock::time_point t0 = Clock::now();
for (int i = 0; i < Threads; ++i) {
threads.push_back(std::thread([&]() {
for (int i = 0; i < OPERATIONS; ++i) {
++counter;
}
}));
}
for (auto& thread : threads) {
thread.join();
}
Clock::time_point t1 = Clock::now();
milliseconds ms = std::chrono::duration_cast<milliseconds>(t1 - t0);
throughput += (Threads * OPERATIONS) / ms.count();
}
std::cout << "atomic with " << Threads << " threads throughput = " << (throughput / REPEAT) << std::endl;
}
#define bench(name)\
name<1>();\
name<2>();\
name<4>();\
name<8>();\
name<16>();\
name<32>();\
name<64>();\
name<128>();
int main() {
bench(bench_lock);
bench(bench_lock_guard);
bench(bench_atomic);
return 0;
}
from http://www.baptiste-wicht.com/2012/07/c11-synchronization-benchmark/















 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









