







预备知识1:SPPnet
最后的卷积层和全连接层之间加入SPP层。
ALEXNET共有5个卷积层。
具体做法是:在conv5层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为
4
∗
4
4*4
4∗4、
2
∗
2
2*2
2∗2、
1
∗
1
1*1
1∗1,然后每个网格做
m
a
x
p
o
o
l
i
n
g
max pooling
maxpooling,这样256层特征图就形成了
16
∗
256
16*256
16∗256,
4
∗
256
4*256
4∗256,
1
∗
256
1*256
1∗256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。这样不管最后卷积层的输出是多少,都可以通过SPP层将其变成21*256的固定大小送入全连接层。

通过下图对卷积层可视化发现:输入图片的某个位置的特征反应在特征图上也是在相同位置。基于这一事实,对某个ROI区域的特征提取只需要在特征图上的相应位置提取就可以了。

NOW !直接对整张图像进行一次卷积操作,通过候选窗从feature map映射得到对应的特征,再通过SPP转化为固定大小输入到全连接层。
预备知识2:SVD分解
方阵A可以通过特征向量和特征值进行分解,如方阵A可以写成
A
=
W
∑
W
T
A=W{\sum}W^{T}
A=W∑WT
其中W为特征向量组成的矩阵,
∑
{\sum}
∑对角线位置为特征值,其他位置为0,但是对于非方阵如何进行这种分解呢,如下图所示,U为
A
A
T
AA^{T}
AAT的特征向量(左奇异向量)组成的矩阵,V为
A
T
A
A^{T}A
ATA的特征向量(右奇异向量)组成的矩阵,最后计算中间的奇异值。
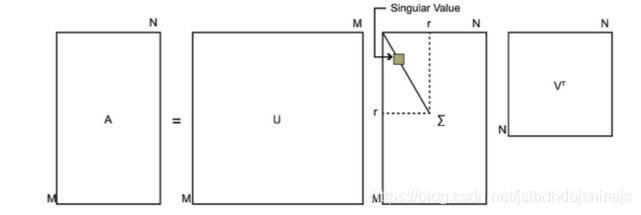
注意回顾PCA降维,是根据最大的k个特征值的特征向量组成映射矩阵映射到低纬度,尽可能的保留数据的信息
预备知识3:全连接层与softmax
送给全连接层的数据为
13
∗
13
∗
10
13*13*10
13∗13∗10,7分类任务,全连接层输出为7层,有两种理解方式:
1 用7个
13
∗
13
∗
10
13*13*10
13∗13∗10的卷积模板得到7个值
2 先将
13
∗
13
∗
10
13*13*10
13∗13∗10排成一列1690的向量(flatten),然后对应每个输出都有1690个参数w和一个偏置(bias可有可无?),即全连接层相当于一个
1690
∗
7
1690*7
1690∗7的参数矩阵(不免联想到了SVD分解)
现在得到的这7个值的范围是负无穷到无穷,再通过softmax将其变成和为1 的7个得分。
预备知识4:交叉熵损失

Fast R-CNN
大致流程:将原图输入卷积网络的到feature map,再由候选框映射得到候选框的特征,将其输入到ROI POOLING层,输出为固定大小送至全连接层,得到得分和候选框,使用多任务损失函数来联合训练分类和边界框回归。
实现细节
SPPnet对R-CNN的改进在后面的分类也是基于SVM来做的,因此他和R-CNN一样训练也是多阶段的(RCNN的训练:ILSVRC 2012上预训练CNN,PASCAL VOC 2007上微调CNN,做20类SVM分类器的训练和20类bounding-box回归器的训练;这些不连续过程必然涉及到特征存储、浪费磁盘空间等问题。)Fast R-CNN综合这两者进行了改进,他是单阶段的训练,使用了多任务损失函数。
对预训练网络的初始化
当一个在ImageNet上面预训练的网络初始化Fast R-CNN网络时,它经历(undergoes)了三次转换(transformations):
- 最后一个最大池化层被RoI池化层所取代,该RoI池化层通过设置合理H和W实现了与第一个全连接层兼容性配置(例如,H=W=7,对于VGG16)
- 网络的最后的全连接层和softmax层(被训练1000个类别在ImageNet分类数据集上)被两个同级并列的层所取代(一个是K+1个类别的softmax分类层,另一个是指定类别的边界框回归偏移量)。
- 网络被修改为两种数据输入:一个是图像列表,另一个是这些图像的RoI列表。
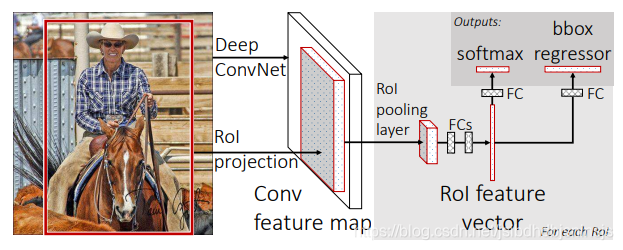
ROI Pooling
每个感兴趣区域RoI被池化为固定尺寸的特征映射,然后通过全连接层映射到特征向量。网络中每个RoI有两个输出向量:softmax概率和每个类别的编辑框回归偏移量。该架构使用多任务损失函数实现了端到端的训练,(使用Selective Search提取Region Proposals,没有实现真正意义上的端对端,操作也十分耗时),RoI pooling层相当于一个简化的SPPnet层(它是只有一个尺度的金字塔层,一个尺度相对于多尺度来说准确率会低一点,但是经过作者测试,单尺度的准确率并没有差多少,但是速度比多尺度快了很多),加在全连接层前面。
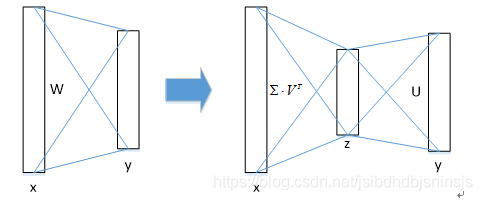
SVD加速
几乎有一半的前向计算时间被花费于全连接层,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算,如下图比如全连接层输入x输出y,全连接层参数为W,再对比上面的SVD看一看就悟了,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度。SVD分解后SVD压缩

多任务损失
举例说明后面的部分
假设一张图像中有3个物体和他的GT,现在通过SS方法得到了100个候选框,从IOU>0.5的候选框中选择25%,假设是17个,依次送进去,得到将送进去的每个候选框的LOSS叠加后再反向传播,STOP!现在的数据是:17个候选框对应的21个得分和4*21个边框值,然后每个框有一个对应的GT,然后来做LOSS,有3至于一个物体有多个框的问题最后有NMS来处理。有问题?
多任务损失函数
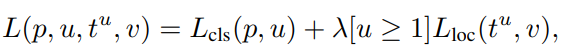
得分的交叉熵损失和边框回归, 边框回归不是很懂
Caffe:卷积神经网络框架
receptive field:感受野
mini-batches:小批量
Multi-task loss:多任务损失
CrossEntropy Loss:交叉熵损失
End-to-End:端到端
残留问题
- 为啥SPPNet不能去更新空间金字塔池化层之下的卷积层权重??传播的时候不是相当于池化层吗?那池化层也没影响反向传播啊??
上面SVD分解的图相当于第一个全连接层不含偏置,第二个全连接层含偏置啥意思?为啥SVD可以加快速度??本来是 150 ∗ 7 150*7 150∗7个参数,现在变成 150 ∗ 150 + 7 ∗ 7 + 奇 异 值 150*150+7*7+奇异值 150∗150+7∗7+奇异值个了,参数还变多了啊是这样的吧 一个一个候选框特征经过ROIPOOLING送至全连接层,输出这个region得分和边框???比如现在一个图像我有三个目标和对应的GT,那SS方法选了很多的候选框,经过卷积和ROI赤化得到很多个候选框特征,那要怎么计算损失啊,对比YOLO提前设定anchor,输入的候选框的数量是固定的,标签和网络的输出都是一一对应的。(IOU大于0.5的计算加入边框回归,)- SGD随机梯度下降














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









