






最近看ctc看了很多遍,因为一直看不懂,所以就死磕到底,最后发现越看越有感觉,就记录一下。
1、CTC 主要解决的问题
CTC Loss要解决的问题就是当label长度小于模型输出长度时,如何做损失函数。
一般做分类时,已有的softmax loss都是模型输出长度和label长度相同且严格对齐,而语音识别或者手写体识别中,无法预知一句话或者一张图应该输出多长的文字,这时做法有两种:seq2seq+attention机制,不限制输出长度,在最后加一个结束符号,让模型自动和gt label对齐;另一种是给定一个模型输出的最大长度,但是这些输出并没有对齐的label怎么办呢,这时就需要CTC loss了。
2、对比传统方法
在传统的语音识别的模型中,我们对语音模型进行训练之前,往往都要将文本与语音进行严格的对齐操作。这样就有两点不太好:
1. 严格对齐要花费人力、时间。
2. 严格对齐之后,模型预测出的label只是局部分类的结果,而无法给出整个序列的输出结果,往往要对预测出的label做一些后处理才可以得到我们最终想要的结果。
虽然现在已经有了一些比较成熟的开源对齐工具供大家使用,但是随着deep learning越来越火,有人就会想,能不能让我们的网络自己去学习对齐方式呢?因此CTC(Connectionist temporal classification)就应运而生啦。
想一想,为什么CTC就不需要去对齐语音和文本呢?因为CTC它允许我们的神经网络在任意一个时间段预测label,只有一个要求:就是输出的序列顺序只要是正确的就ok啦~这样我们就不在需要让文本和语音严格对齐了,而且CTC输出的是整个序列标签,因此也不需要我们再去做一些后处理操作。
对一段音频使用CTC和使用文本对齐的例子如下图所示:
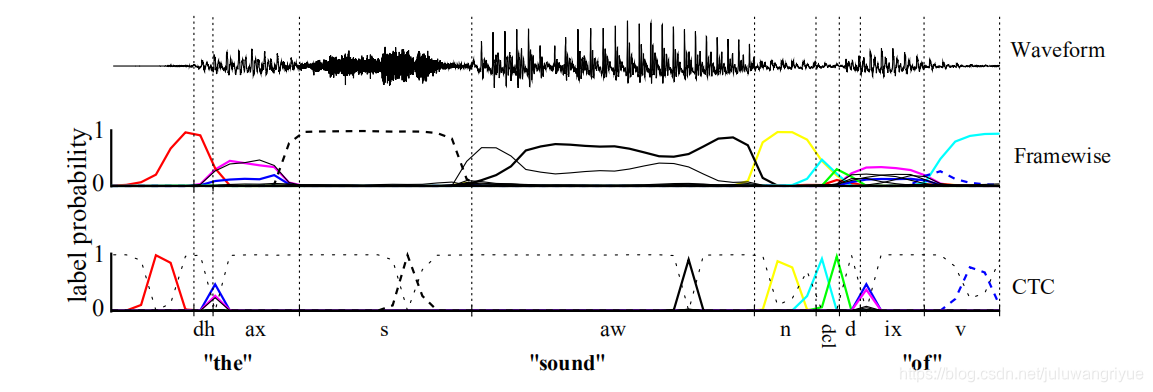
如上图,传统的Framewise训练需要进行语音和音素发音的对齐,比如“s”对应的一整段语音的标注都是s;而CTC引入了blank(该帧没有预测值),“s”对应的一整段语音中只有一个spike(尖峰)被认为是s,其他的认为是blank。对于一段语音,CTC最后的输出是spike的序列,不关心每一个音素对应的时间长度。
与传统神经网络主要区别
训练流程和传统的神经网络类似,构建loss function,然后根据BP算法进行训练,不同之处在于传统的神经网络的训练准则是针对每帧数据,即每帧数据的训练误差最小,而CTC的训练准则是基于序列(比如语音识别的一整句话)的,比如最大化p(z|x)p(z|x) ,序列化的概率求解比较复杂,因为一个输出序列可以对应很多的路径,所有引入前后向算法来简化计算。
输出
语音识别中的DNN训练,每一帧都有相应的状态标记,比如有5帧输入x1,x2,x3,x4,x5,对应的标注分别是状态a1,a1,a1,a2,a2。
CTC的不同之处在于输出状态引入了一个blank,输出和label满足如下的等价关系:
F(a−ab−)=F(−aa−−abb)=aab
多个输出序列可以映射到一个输出。
前期准备

前后向算法
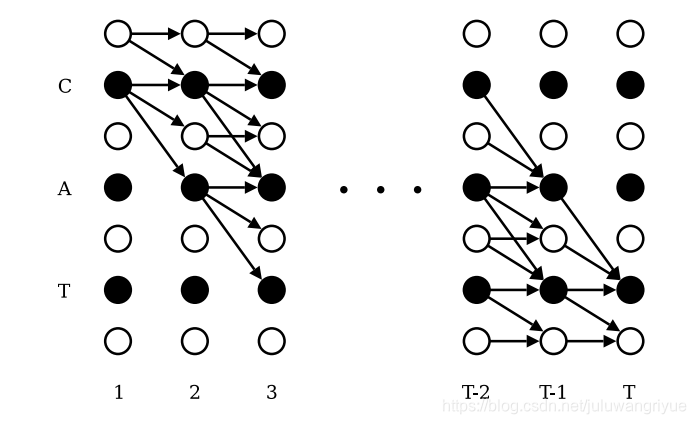
考虑到计算
p
(
l
∣
x
)
p(l|x)
p(l∣x)需要计算很多条路径的概率,随着输入长度呈指数化增加,可以引入类似于HMM的前后向算法来计算该概率值。
为了引入blank节点,在label首尾以及中间插入blank节点,如果label序列原来的长度为U,那么现在变为U’=2U+1。
为看清全貌,假设T=7,则上图全貌如下:
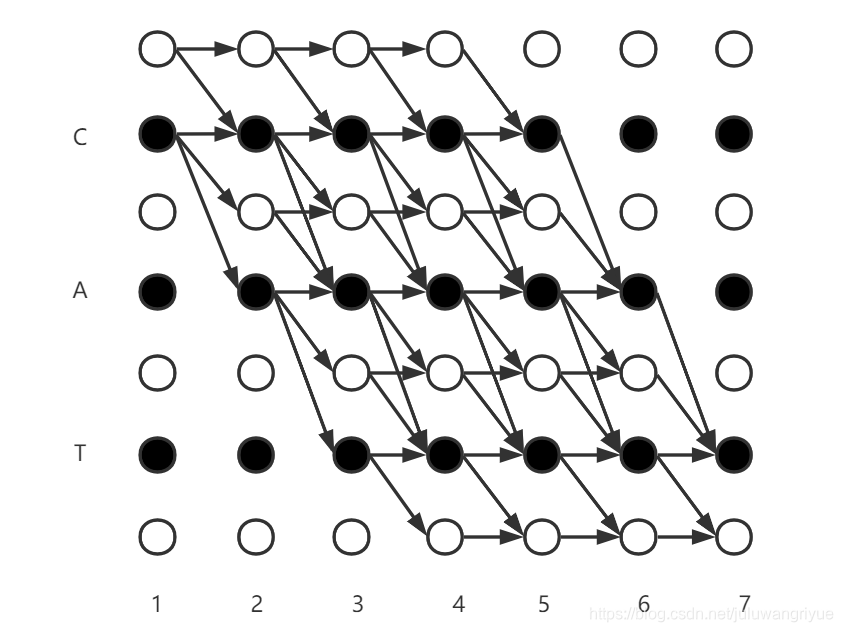
前向(将前向与后向对比)
前向变量
α
t
(
s
)
\alpha_t(s)
αt(s) ,表示
t
t
t时刻在节点
s
s
s的前向概率值,其中
s
∈
[
1
,
2
∣
l
∣
+
1
]
s\in[1, 2|l|+1]
s∈[1,2∣l∣+1]。
初始化值如下:
α
1
(
1
)
=
y
b
1
\alpha_1(1)=y_b^1
α1(1)=yb1
α
1
(
2
)
=
y
l
1
1
\alpha_1(2)=y_{l_1}^1
α1(2)=yl11
α
1
(
s
)
=
0
,
∀
s
>
2
\alpha_1(s)=0,\quad \forall s > 2
α1(s)=0,∀s>2
递推关系:
α
t
(
s
)
=
{
α
ˉ
t
(
s
)
y
l
s
′
t
i
f
l
s
′
=
b
o
r
l
s
−
2
′
=
l
s
′
(
α
ˉ
t
(
s
)
+
α
t
−
1
(
s
−
2
)
)
y
l
s
′
t
o
t
h
e
r
w
i
s
e
\alpha_t(s)=\left\{ \begin{matrix} \bar{\alpha}_t(s)y_{l_s^{'}}^t \quad if l_s^{'}=b \quad or \quad l^{'}_{s-2}=l^{'}_s \\ (\bar\alpha_t(s)+\alpha_{t-1}(s-2))y_{l_s^{'}}^t \quad otherwise \end{matrix} \right.
αt(s)={αˉt(s)yls′tifls′=borls−2′=ls′(αˉt(s)+αt−1(s−2))yls′totherwise
其中:
α
ˉ
t
(
s
)
=
d
e
f
α
t
−
1
(
s
)
+
α
t
−
1
(
s
−
1
)
\bar\alpha_t(s)\xlongequal{def}\alpha_{t-1}(s)+\alpha_{t-1}(s-1)
αˉt(s)defαt−1(s)+αt−1(s−1)

后向
初始化值:
β
T
(
∣
l
′
∣
)
=
y
b
T
\beta_T(|l^{'}|)=y_b^T
βT(∣l′∣)=ybT
β
T
(
∣
l
′
∣
−
1
)
=
y
l
∣
l
∣
T
\beta_T(|l^{'}|-1)=y_{l_{|l|}}^T
βT(∣l′∣−1)=yl∣l∣T



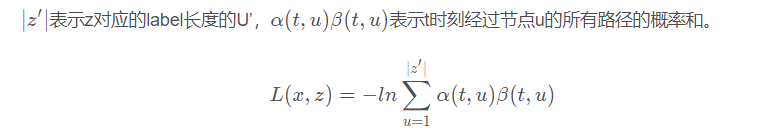


ctc代码学习参考ctc
图1. 序列建模【src】
虽然并没为限定 Nw 具体形式,下面为假设其了某种神经网络(e.g. RNN)。
下面代码示例 toy Nw:
import numpy as np
np.random.seed(1111)
T, V = 12, 5
m, n = 6, V
x = np.random.random([T, m]) # T x m
w = np.random.random([m, n]) # weights, m x n
def softmax(logits):
max_value = np.max(logits, axis=1, keepdims=True)
exp = np.exp(logits - max_value)
exp_sum = np.sum(exp, axis=1, keepdims=True)
dist = exp / exp_sum
return dist
def toy_nw(x):
y = np.matmul(x, w) # T x n
y = softmax(y)
return y
y = toy_nw(x)
print(y)
print(y.sum(1, keepdims=True))
参考:CTC loss 理解
参考:《Supervised Sequence Labelling with Recurrent Neural Networks》 chapter7
参考:【Learning Notes】CTC 原理及实现


















 4235
4235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











