







前言
本片博客主要学习了CTC并在动态规划求CTC loss的理解上学习了这篇博客
由于在看的过程中,还是花了很长时间反复推敲作者的理解,因此在这边用更加简单的话来解释一下CTC loss
背景
在OCR光学字符识别,语音识别,文本生成等任务中,我们常常会遇到输入长度与输出长度不等的情况,这种情况通常需要我们事先让输入输出对齐,因为一一对应才能进行判别或预测。seq2seq模型可以用于输入输出长度不相等的情况,但是Transformer-Seq2Seq预测效率比较低,而RNN-Seq2Seq准确率无法达到要求,虽然目前已经提出多种策略来加速Transformer-Seq2Seq的解码效率,不过这是以后我们会讲的,本节主要讲解CTC损失。针对上述痛点,CTC论文提出了CTC损失,CTC损失可以应用于任意输入与输出长度不等的任务,但是有一个前提条件,输入长度必须大于输出长度,因为CTC并不能凭空生成,而是从已有的Source Feature中选择出Target Sentence。
整体理解
CTC loss能够解决输入输出长度不等任务的原因在于两点:第一,CTC让模型可以在连续的时间片段中,输出相同的字符,并通过合并相同字符的方式,让连续时间片段的输出为单一字符;第二,在目标输出中存在重复字符的时候,比如hello的l,CTC引入了blank字符,在blank字符前后的相同字符不会被合并,例如 h e e l ⟨ b ⟩ l o h eel\langle b \rangle lo heel⟨b⟩lo中,e的输出会合并,而l的输出不会被合并,最终输出 h e l l o hello hello。因为有重复字符以及blank的存在,相同输出可能存在多条路径,因此CTC loss的目的就是最大化所有可能路径的概率。下面章节讲述了CTC loss的一些细节以及程序实现
CTC Loss

CTC引入了一个新的输出字符blank,用
ϵ
\epsilon
ϵ表示,如上图所示。上图为语音任务中CTC标签的应用。以输出字符集合
y
=
{
h
,
e
,
l
,
o
}
y=\{h,e,l,o\}
y={h,e,l,o}为例,CTC构建了
Y
=
y
∪
{
ϵ
}
\mathcal{Y}=y\cup\{\epsilon\}
Y=y∪{ϵ},令
T
T
T为总步长,
S
=
∣
Y
∣
S=|\mathcal{Y}|
S=∣Y∣为输出字符集合的数量。上述语音任务可描述为在每一步有5种可能的情况下,找到T=10的最可能解。对于找到的解,我们通过移除
ϵ
\epsilon
ϵ并合并重复字符得到最终解。
CTC假设任意时刻的输入与输出之间的条件独立的,因此我们可以计算出对输入X和输出Y的CTC条件概率
p
(
Y
∣
X
)
=
∑
A
∈
A
X
,
Y
∏
t
=
1
T
p
t
(
a
t
∣
X
)
p(Y|X)=\sum_{A\in A_{X,Y}}\prod_{t=1}^Tp_t(a_t|X)
p(Y∣X)=A∈AX,Y∑t=1∏Tpt(at∣X)
这里的
A
X
,
Y
A_{X,Y}
AX,Y代表了所有可能的路径,
A
A
A代表其中一条路径,因此上式代表所有路径的可能性之和
得到概率后计算损失就很容易了,由于概率都是模型给出的softmax结果,因此概率和的负对数就是交叉熵损失:
L
o
s
s
=
∑
(
X
,
Y
)
∈
D
−
l
o
g
(
p
(
Y
∣
X
)
)
Loss=\sum_{(X,Y)\in \mathcal{D}}-log(p(Y|X))
Loss=(X,Y)∈D∑−log(p(Y∣X))
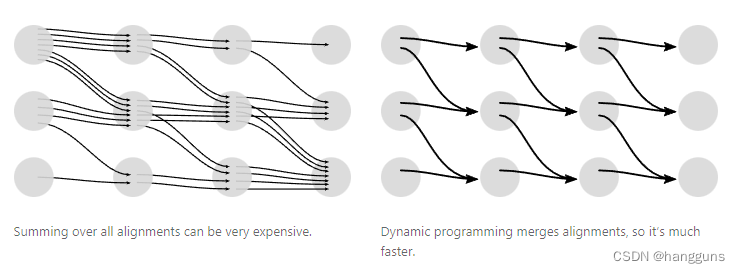
然而计算所有路径的可能性会让时间成本大大增加,我们可以采用动态规划的办法来降低时间成本。在左图中,如果我们每次计算一条路径的可能性,那么我们一共需要计算36次,而通过动态规划的方法,每次计算通过当前节点的可能性之和,那么在经过同一输入输出节点的情况下,我们只需计算一次,因此可以将计算量从36次降低到15次,大大减少时间成本。
由于
ϵ
\epsilon
ϵ可以出现在任意字符的前面或者后面,因此我们可以假设一个通用
Z
Z
Z
Z
=
[
ϵ
,
y
1
,
ϵ
,
y
2
,
.
.
.
,
ϵ
,
y
U
,
ϵ
]
Z=[\epsilon,y_1,\epsilon,y_2,...,\epsilon,y_U,\epsilon]
Z=[ϵ,y1,ϵ,y2,...,ϵ,yU,ϵ]
并通过Z来进行CTC求解,在每一时间节点的路径选择中,会出现2种情况:
第一种
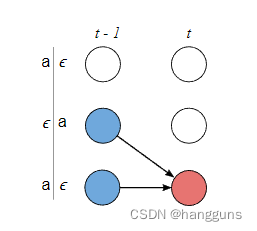
令纵轴坐标从上往下依次为
[
s
−
2
,
s
−
1
,
s
]
[s-2,s-1,s]
[s−2,s−1,s],
α
s
,
t
\alpha_{s,t}
αs,t代表在s位置,t时刻节点的CTC分数,
α
s
,
t
\alpha_{s,t}
αs,t的分数仅由
α
s
−
1
,
t
−
1
\alpha_{s-1,t-1}
αs−1,t−1和
α
s
,
t
−
1
\alpha_{s,t-1}
αs,t−1获得:
α
s
,
t
=
(
α
s
−
1
,
t
−
1
+
α
s
,
t
−
1
)
∗
p
t
(
z
s
∣
X
)
\alpha_{s,t}=(\alpha_{s-1,t-1}+\alpha_{s,t-1})*p_t(z_s|X)
αs,t=(αs−1,t−1+αs,t−1)∗pt(zs∣X)
原因:当
z
s
,
t
−
1
=
ϵ
z_{s,t-1}=\epsilon
zs,t−1=ϵ或
z
s
−
1
,
t
−
1
=
ϵ
z_{s-1,t-1}=\epsilon
zs−1,t−1=ϵ且
z
s
−
2
,
t
−
1
=
z
s
,
t
−
1
z_{s-2,t-1}=z_{s,t-1}
zs−2,t−1=zs,t−1时,只有
z
s
−
1
,
t
−
1
z_{s-1,t-1}
zs−1,t−1和
z
s
,
t
−
1
z_{s,t-1}
zs,t−1可以到达
z
s
,
t
z_{s,t}
zs,t,也就是只有2条路径。因为当
z
s
,
t
−
1
=
ϵ
z_{s,t-1}=\epsilon
zs,t−1=ϵ时,上一个
z
s
−
1
,
t
−
1
z_{s-1, t-1}
zs−1,t−1一定为字符,上上一个
z
s
−
2
,
t
−
1
=
ϵ
z_{s-2,t-1}=\epsilon
zs−2,t−1=ϵ,而
ϵ
\epsilon
ϵ不能直接跳过字符,否则与目标不一致;当
z
s
−
1
,
t
−
1
=
ϵ
z_{s-1,t-1}=\epsilon
zs−1,t−1=ϵ且
z
s
−
2
,
t
−
1
=
z
s
,
t
−
1
z_{s-2,t-1}=z_{s,t-1}
zs−2,t−1=zs,t−1时,
z
s
−
2
,
t
−
1
z_{s-2,t-1}
zs−2,t−1也不能跳过
z
s
−
1
,
t
−
1
z_{s-1,t-1}
zs−1,t−1直接到达
z
s
,
t
z_{s,t}
zs,t,因为跳过中间的
ϵ
\epsilon
ϵ后,重复的字符会被合并,而目标中是不合并的,导致不一致。
第二种
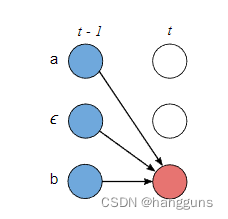
当
Z
s
−
2
:
s
+
1
=
[
a
,
ϵ
,
b
]
Z_{s-2:s+1}=[a,\epsilon,b]
Zs−2:s+1=[a,ϵ,b]时,
α
s
,
t
\alpha_{s,t}
αs,t的分数为前一时刻的三条路径和:
α
s
,
t
=
(
α
s
−
1
,
t
−
1
+
α
s
,
t
−
1
+
α
s
−
2
,
t
−
1
)
∗
p
t
(
z
s
∣
X
)
\alpha_{s,t}=(\alpha_{s-1,t-1}+\alpha_{s,t-1}+\alpha_{s-2,t-1})*p_t(z_s|X)
αs,t=(αs−1,t−1+αs,t−1+αs−2,t−1)∗pt(zs∣X)
动态规划例子
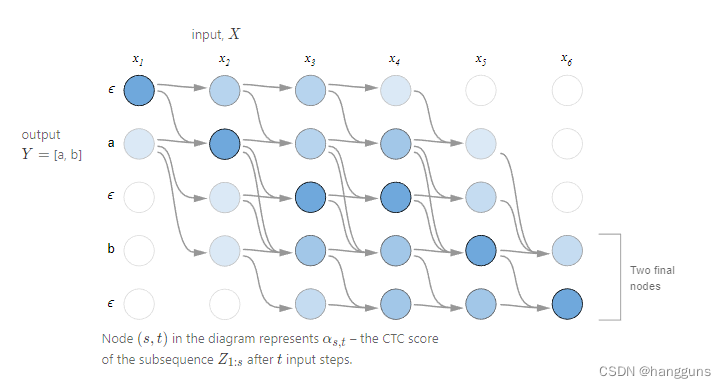
以上是整体动态规划的例子,所有可行路径的最终结果均为
Y
=
[
a
,
b
]
Y=[a,b]
Y=[a,b]。在初始的时候,
x
1
∈
[
ϵ
,
a
]
x_1\in[\epsilon,a]
x1∈[ϵ,a],因此可行的出发点只有两个,最终可行的结束点也只有两个,最终的CTC 分数只需将最终的两个点的CTC分数相加即可
给一个python实现的例子,并进行了注释
import numpy as np
def forward(y, labels):
T, V = y.shape
L = len(labels)
alpha = np.zeros([L, T])
# 初始时,alpha0,0等于空白的概率,alpha1,0等于第一个字符的概率
alpha[0, 0] = y[labels[0], 0]
alpha[1, 0] = y[labels[1], 0]
for t in range(1, T):
# 从t=1时刻开始计算每一时刻的alpha值
for i in range(L):
s = labels[i]
#首先记录上一时刻当前节点的值
a = alpha[i, t - 1]
if i - 1 >= 0:
# case1:直接将上一个字符的CTC分数加上
a += alpha[i - 1, t - 1]
# case2:加上上上字符的CTC分数
if i - 2 >= 0 and s != 0 and s != labels[i - 2]:
a += alpha[i - 2, t - 1]
# 乘以概率
alpha[i, t] = a * y[t, s]
return alpha
y = np.array([
[0.1, 0.3, 0.6],
[0.2, 0.4, 0.4],
[0.3, 0.6, 0.1],
[0.4, 0.5, 0.1],
[0.5, 0.1, 0.4]
])
labels = [0, 1, 0, 2, 0] # 0 for blank
alpha = forward(y, labels)
loss = -np.log(np.sum(alpha[:, -1]))
print(f"alpha is : {alpha}")
print(f"loss is : {loss}")
alpha is : [[0.1 0.02 0.006 0.0024 0.0012 ]
[0.2 0.12 0.084 0.045 0.00474]
[0. 0.04 0.048 0.0528 0.0489 ]
[0. 0.08 0.024 0.0156 0.04536]
[0. 0. 0.024 0.0192 0.0174 ]]
loss is : 2.1404662435176105
我们可以用keras的ctc_batch_cost对上面的例子进行测试比较,代码如下:
import keras.backend as K
labels = np.array([1,2])[None, ...] # [samples, max_string_length] 真实标签只有2个,0为空白标签
y = np.array(y)[None, ...] # [samples, time_steps, num_categories] y和上面代码片段中使用的一致
input_length = np.array([[y.shape[1]]]) # [samples, 1]
target_length = np.array([[labels.shape[1]]]) # [samples, 1]
print(K.ctc_batch_cost(labels, y, input_length, target_length))
loss is: <tf.Tensor: shape=(1, 1), dtype=float64, numpy=array([[2.18426897]])>
结果和手动计算的类似

















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









