







0. Hadoop分布式环境搭建之环境介绍
我这里准备了三台机器,IP地址如下:
192.168.153.113
192.168.153.186
192.168.153.223
1. 网络配置
首先在这三台机器上修改主机名以及配置其他机器的主机名
1.1 修改主机名(三台机器都要修改)
[root@bigdata100 ~]# hostnamectl set-hostname bigdata100
1.2 编辑/etc/hosts配置文件(三台机器都要修改)
[root@bigdata100 ~]# vim /etc/hosts
修改为如下
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.153.113 bigdata100
192.168.153.186 bigdata101
192.168.153.223 bigdata102
1.3 配置ssh免密码登录(三台机器都要修改)
[root@bigdata100 ~]# ssh-keygen -t rsa # 三台机器都需要执行这个命令生成密钥对
[root@bigdata100 ~]# ls .ssh/
authorized_keys id_rsa id_rsa.pub known_hosts
[root@bigdata100 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata100
[root@bigdata100 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata101
[root@bigdata100 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata102
1.4 测试
[root@bigdata100 ~]# ping bigdata100
[root@bigdata100 ~]# ping bigdata101
[root@bigdata100 ~]# ping bigdata102
[root@bigdata100 ~]# ssh bigdata101
[root@bigdata100 ~]# ssh bigdata102
2. JDK安装与配置
下载压缩包 jdk-8u151-linux-x64.tar.gz
2.1 解压
[root@bigdata100 ~]# tar -zxvf jdk-8u151-linux-x64.tar.gz
2.2 移动到自己目录(这里我的目录是bigDataSoftware)
[root@bigdata100 ~]# mv ./jdk1.8.0_151 /home/bigDataSoftware/JDK_1.8
2.3 配置环境变量
[root@bigdata100 ~]# vim /etc/profile
在最后添加
export JAVA_HOME=/home/bigDataSoftware/JDK_1.8
export JRE_HOME=/home/bigDataSoftware/JDK_1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
加载配置文件,让其生效
[root@bigdata100 ~]# source /etc/profile
2.4 测试
[root@bigdata100 ~]# java -version
[root@bigdata100 ~]# javac -version
2.5 JDK及环境变量分发
[root@bigdata100 ~]# rsync -av /home/bigDataSoftware/JDK_1.8 bigdata101:/home/bigDataSoftware
[root@bigdata100 ~]# rsync -av /home/bigDataSoftware/JDK_1.8 bigdata101:/home/bigDataSoftware
[root@bigdata100 ~]# rsync -av /etc/profile bigdata101:/etc/profile
[root@bigdata100 ~]# rsync -av /etc/profile bigdata101:/etc/profile
3. Hadoop安装与配置
3.1 将Hadoop压缩包拖入解压
[root@bigdata100 /home/bigDataSoftware]# tar -zxvf hadoop-2.7.7.tar.gz
3.2 在hadoop-2.7.7文件夹里面先创建4个文件夹:
hadoop-2.7.7/hdfs
hadoop-2.7.7/hdfs/tmp
hadoop-2.7.7/hdfs/name
hadoop-2.7.7/hdfs/data
3.3 配置Hadoop文件
进入/home/bigDataSoftware/hadoop-2.7.7/etc/hadoop
3.3.1 配置core-site.xml文件
vim core-site.xml
在中加入以下代码:
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/bigDataSoftware/hadoop-2.7.7/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata100:9000</value>
</property>
注意:第一个属性中的value和我们之前创建的/hadoop-2.7.7/hdfs/tmp路径要一致。
3.3.2 配置 hadoop-env.sh文件
将JAVA_HOME文件配置为本机JAVA_HOME路径
# The java implementation to use.
export JAVA_HOME=/home/bigDataSoftware/JDK_1.8
3.3.3 配置 yarn-env.sh
将其中的JAVA_HOME修改为本机JAVA_HOME路径(先把这一行的#去掉)
# some Java parameters
export JAVA_HOME=/home/bigDataSoftware/JDK_1.8
if [ "$JAVA_HOME" != "" ]; then
3.3.4 配置hdfs-site.xml
在中加入以下代码
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/bigDataSoftware/hadoop-2.7.7/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/bigDataSoftware/hadoop-2.7.7/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata100:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
因为这里有两个从主机,所以dfs.replication设置为2
3.3.5 复制mapred-site.xml.template文件,并命名为mapred-site.xml
配置 mapred-site.xml,在标签中添加以下代码
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.3.6 配置yarn-site.xml
在标签中添加以下代码
<property>
<name>yarn.resourcemanager.address</name>
<value>bigdata100:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bigdata100:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata100:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bigdata100:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>bigdata100:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
3.3.7 配置slaves 文件
修改为如下
bigdata101
bigdata102
3.3.8 配置hadoop的环境,就像配置jdk一样
在/etc/profile文件最后添加如下
export HADOOP_HOME=/home/bigDataSoftware/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
3.3.9 Hadoop分发
rsync -av /home/bigDataSoftware/hadoop-2.7.7/ bigdata101:/home/bigDataSoftware/hadoop-2.7.7/
rsync -av /home/bigDataSoftware/hadoop-2.7.7/ bigdata102:/home/bigDataSoftware/hadoop-2.7.7/
环境变量配置文件分发
rsync -av /etc/profile bigdata101:/etc/profile
rsync -av /etc/profile bigdata102:/etc/profile
分别在其他两台主机上source
3.4 Hadoop格式化及启停
hdfs namenode -format
hadoop启动
start-all.sh
查看是否有一下进程启动
[root@bigdata100 ~]# jps
6256 Jps
5843 ResourceManager
5413 NameNode
5702 SecondaryNameNode
[root@bigdata101 ~]# jps
3425 DataNode
3538 NodeManager
3833 Jps
[root@bigdata102 ~]# jps
3425 DataNode
3538 NodeManager
3833 Jps
hadoop关闭
stop-all.sh
3.5 web管理
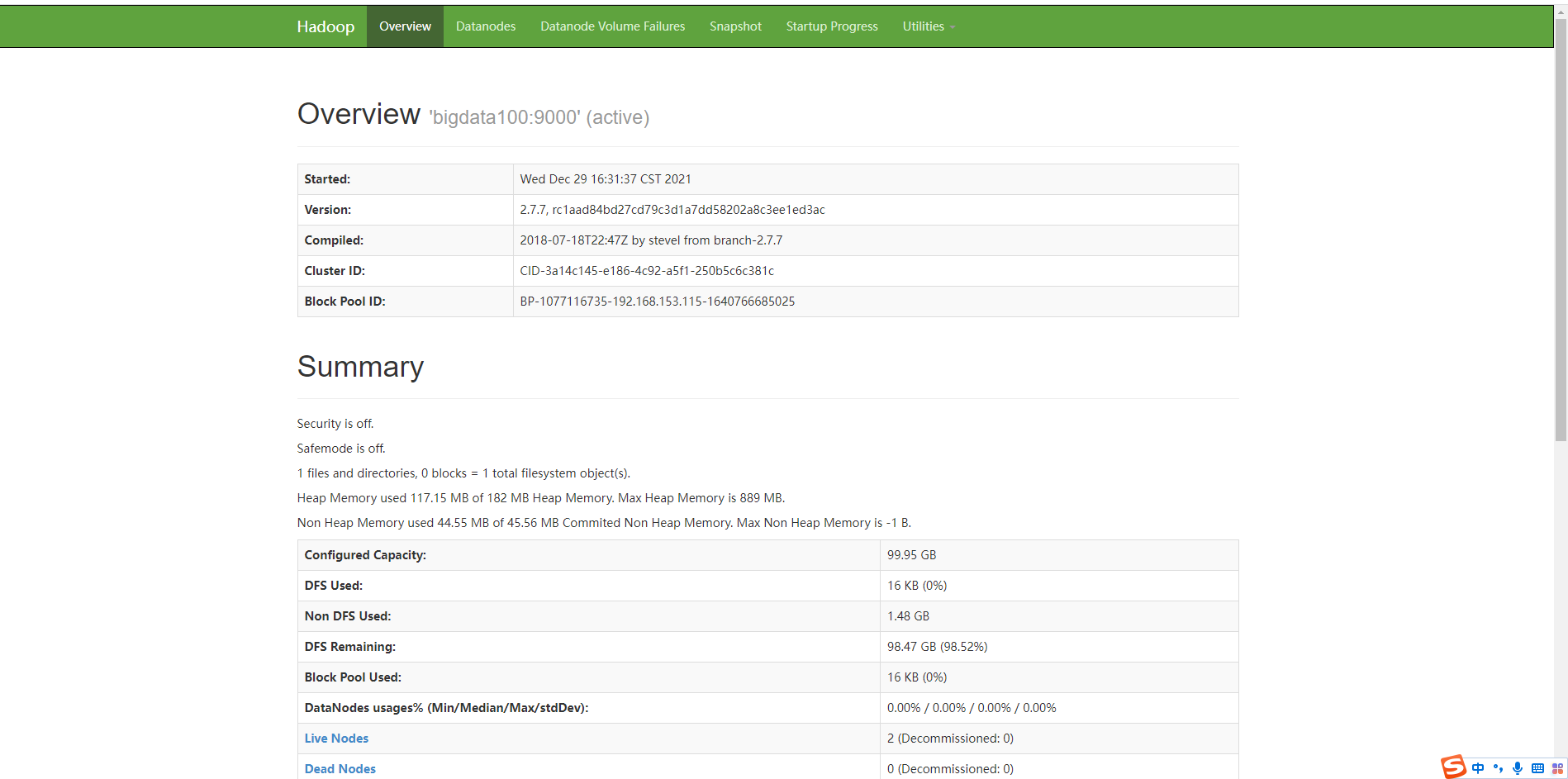
各机器的进程检查完成,并且确定没有问题后,在浏览器上访问主节点的50070端口,例如:192.168.153.115:50070。会访问到如下页面:
查看存活的节点:
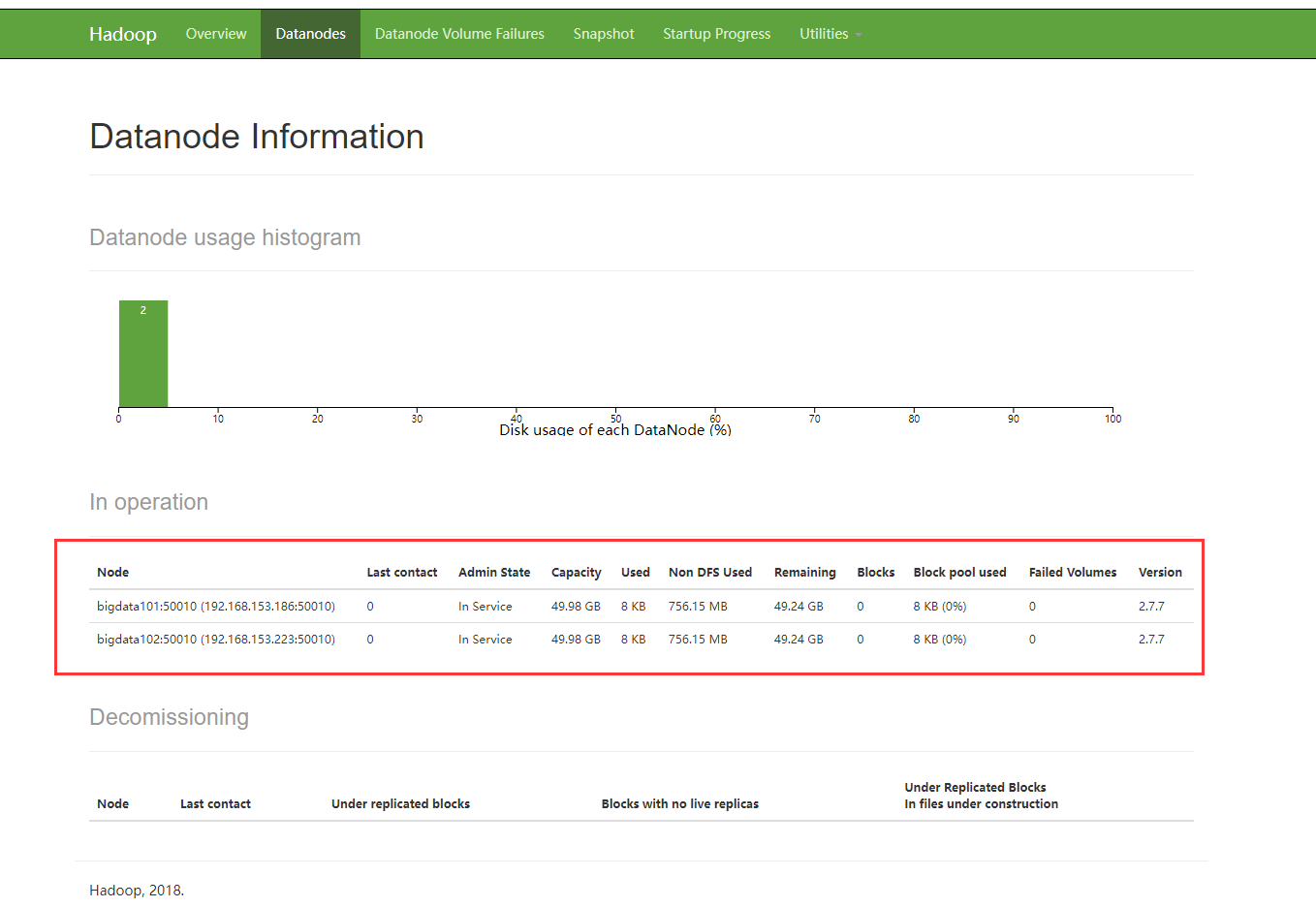
如上,可以访问50070端口就代表集群中的HDFS是正常的。
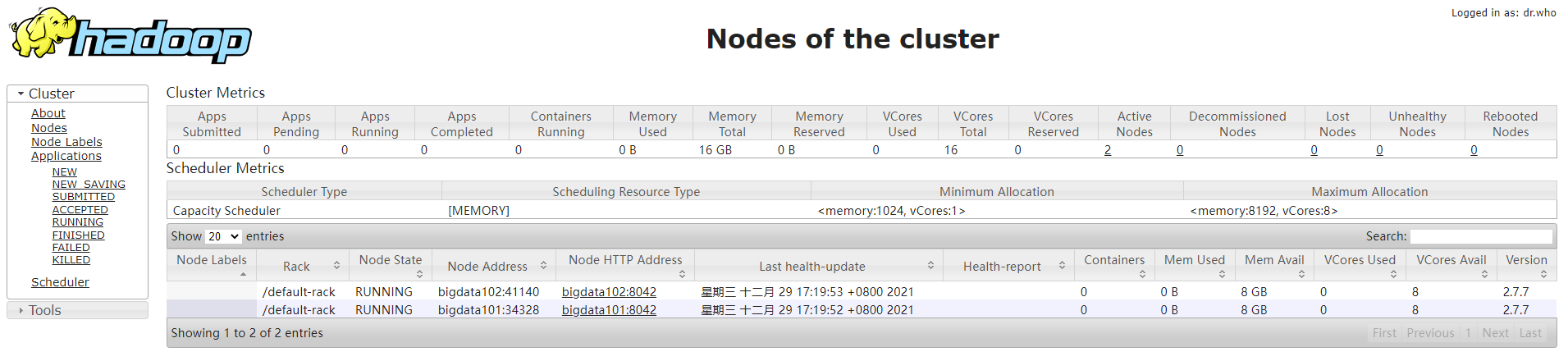
接下来我们还需要访问主节点的8088端口,这是YARN的web服务端口,例如:192.168.153.115:18088。如下:
参考:
https://cloud.tencent.com/developer/article/1703113
https://blog.csdn.net/fanxin_i/article/details/80425461
问题:
hadoop启动start-all.sh,slave节点没有datanode的问题 https://blog.csdn.net/long085/article/details/78535873
















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











