







目录
一、分布式计算领域概览
当前分布式计算模型主要分为以下4种:
-
Bulk Synchronous Parallel Model(块同步并行模型)
-
BSP模型在大数据处理场景下应用非常广泛,例如MapReduce、Spark等框架都是采用BSP模型。BSP编程模型的实现较为简单,但也具有相当多的限制。
-
BSP模型具有以下特点:
-
BSP模型将计算划分为一个一个的超步(superstep),有效避免死锁。
-
它将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
-
采用障碍同步的方式以硬件实现的全局同步是在可控的粗粒度级,从而提供了执行紧耦合同步式并行算法的有效方式,而程序员并无过分的负担;
-
在分析BSP模型的性能时,假定局部操作可以在一个时间步内完成,而在每一个超级步中,一个处理器至多发送或接收h条消息(称为h-relation)。假定s是传输建立时间,所以传送h条消息的时间为gh+s,如果 ,则障碍同步时间L至少应该大于等于gh。很清楚,硬件可以将L设置尽量小(例如使用流水线或大的通信带宽使g尽量小),而软件可以设置L的上限(因为L越大,并行粒度越大)。在实际使用中,g可以定义为每秒处理器所能完成的局部计算数目与每秒路由器所能传输的数据量之比。如果能够合适的平衡计算和通信,则BSP模型在可编程性方面具有主要的优点,而直接在BSP模型上执行算法(不是自动的编译它们),这个优点将随着g的增加而更加明显;
-
BSP的成本模型:一个超步的计算成本

,其中wi是进程I的局部计算时间,hi是进程I发送或接受的最大通信包数,g是带宽的倒数(时间步/通信包),L是障碍同步时间。在BSP计算中,如果使用了s个超步,那总的运行时间为:
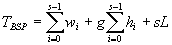
-
-
为PRAM模型所设计的算法,都可以采用在每个BSP处理器上模拟一些PRAM处理器的方法来实现。
-
-
但BSP模型的限制在于,它不支持状态,而且在无法天然拆解为多个超步(可以理解为MapReduce)的应用场景下并行计算就会变得非常困难。
-
-
Task Parallel Model(任务并行模型)
-
Task Parallel Model允许以分布式的方式执行任意无副作用的函数,任务之间可以任意地传输数据。
-
Task Parallel Model比BSP模型更强大,而且与单机顺序程序的表达方式更兼容。它可以通过checkpoint或是lineage来实现容错,但同样也不支持状态。
-
-
Communicating Processes Model(通信进程模型)
-
通信进程模型支持状态,它是task parallel model的通用化,因为每个task 并行程序都可以再一个通信进程上执行,方法是将函数调度到正确的进程上。
-
通信进程有几种实现方式,包括消息传递实现,例如MPI,或是actor system,例如Erlang/ Akka/ Orleans。这里我们可以重点关注actor system,因为它足够强大,同时编程模型更结构化。
-
-
Distributed Shared Memory Model(分布式共享内存模型)
-
分布式共享内存模型是一个理想的版本,它将整个集群暴露为一个单一的大核机器,可以使用多个执行线程进行编程,这些线程通过共享内存的读写进行通信。
-
实际上这种理想状态是无法实现的。通过网络访问远程内存的延迟通常比访问本地内存的延迟大得多。此外,这种架构不具有容错性。
-
二、Spark计算模型分析
Spark其应用程序在集群中以独立的进程组来运行,分为Driver和Executor两个角色。Driver即用户的主程序,Executor会为用户的应用程序处理计算和数据程序,d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









