






K-Means聚类
源码与数据:github
一、 实验要求
1、编程实现K-means,对所提供数据(data.txt)进行聚类,cluster数量为3
2、数据形式为[x1, x2],其中x1,x2为样本属性
二、 实验原理:
2.1 K-means原理
K-means是一种基于距离的聚类算法,主要用于将数据点分成k个不同的簇,使得每个簇内的数据点相似度较高,不同簇之间的相似度较低。K-means是一种迭代算法,需要不断地迭代调整簇的中心点,直至满足停止迭代的条件。
2.2 K-means简要算法流程如下:
① 从数据集中随机选择k个数据点作为初始中心点(centroid)。
② 针对每个数据点,计算它与k个中心点的距离,并将它分配到距离最近的中心点所代表的簇中。
③ 针对每个簇,重新计算它的中心点,即将它的所有数据点的平均值作为新的中心点。
④ 重复步骤2和步骤3,直到簇的分配不再发生变化,或者达到预先设定的迭代次数。
⑤ 算法结束,输出最终的簇分配结果和中心点坐标。
2.3 k值
在实际应用中,簇的数量k可以根据领域知识、经验或试错法来确定。
2.4 K-means优缺点
1、优点:
① 算法简单易实现。
② 对于大规模数据集,K-means算法可以通过并行化技术加速计算。
③ 聚类效果较好,且能够适用于各种不同类型的数据。
2、缺点:
① 需要手动设定簇的数量k,这可能需要领域知识或试错法来确定。
② 对于不同的随机初始中心点,可能会得到不同的聚类结果,这会导致算法的不稳定性。
③ 算法可能会收敛到一个局部最优解,而不是全局最优解。
三、 实验过程:
3.1 读取数据
数据保存在“data.txt”中,保存格式如图:

根据数据的保存格式读取数据。
data_list = []
with open(path,"r") as f:
lines = f.readlines()
for line in lines:
line = line.strip()
tmp = line.strip('[]').split()
data_list.append([float(num) for num in tmp])
data = np.array(data_list)
print(data.shape)
“data_list”保存处理后的每行数据,读取完数据后,将其转化为“ndarray”并打印数据的形状。
利用“strip”函数去掉空格和中括号,通过列表生成式生成每行数据,并用“float”进行数字类型转换。
如图所示,数据集形状为90*2,即有90个样本,每个样本有两个属性。

3.2 分析k值
以散点图形式打印数据集,观察数据集的分布。
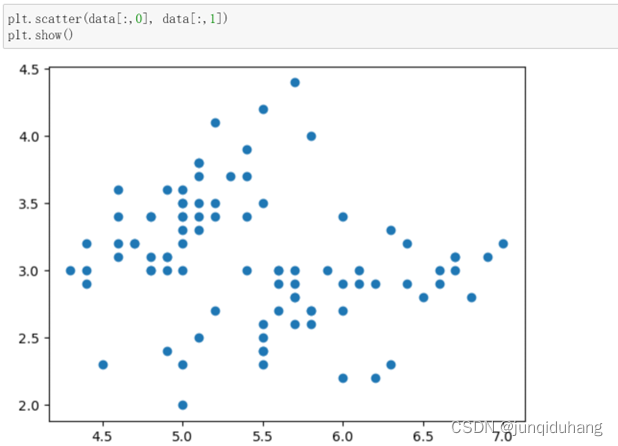
如图所示,数据集大致由两簇组成,因此暂时确定k值为2。
3.3 K-means算法辅助函数
1、计算欧氏距离
通过欧氏距离评估样本和中心点的距离
#计算欧氏距离
def getDistance(x,y):
return np.sqrt(np.sum((x-y)**2))
2、随机中心点
刚开始聚类时,需要根据k值确定随机中心点以展开聚类。随机中心点的优劣对聚类结果具有重要影响。
#初始化中心点
def getCenter(dataset,k):
m,n = dataset.shape
centerDots = np.zeros((k,n))
for i in range(k):
row = np.random.randint(m)
centerDots[i,:] = dataset[row,:]
return centerDots
3.4 K-means算法实现
说明见2.2。
本实验中判断聚类结束的条件为:当前轮次没有点更换过簇。反之,若某个点的簇发生了变化,则继续聚类。
每轮聚类结束后,需要更新各个簇的中心点。本实验中取各类样本的均值作为各类的中心点。
聚类结束后,返回聚类中心和各个样本的类别。
#Kmeans算法
def Kmeans(dataset,k):
m,n = dataset.shape
clusters = np.mat(np.zeros((m,2)))#构造m*2存储分类属性
centerDots = getCenter(dataset, k)#获取随机中心
Continuing = True
while(Continuing):
Continuing = False
for i in range(m):
minDistance = 1e5
minindex = -1
for j in range(k):
#计算当前记录离那个中心更近
distance = getDistance(centerDots[j,:], dataset[i,:])
if distance < minDistance:
minDistance = distance
minindex = j
#更新i记录类别
if clusters[i,0] != minindex:
Continuing = True
clusters[i,:] = minindex,minDistance
#更新中心点
for j in range(k):
cur_cluster = dataset[np.nonzero(clusters[:,0].A == j)[0]]
centerDots[j] = np.mean(cur_cluster,axis=0)
print("聚类完成")
return centerDots,clusters[:,0].ravel().tolist()
3.5 K-means聚类结果评估
使用两种方式进行评估:
① 聚类结果可视化
② 对比分析:使用sklearn库的Kmeans算法对统一数据集进行聚类并可视化
#设置k值
k = 2
plt.figure(dpi=100)
#上述Kmeans实现聚类并可视化
plt.subplot(121)
centroids,labels = Kmeans(data,k)
plt.scatter(data[:,0], data[:,1], c=labels)
plt.title("Kmeans from self")
#绘制中心点
centerDots = centroids
for i in range(len(centerDots)):
plt.annotate("center", xy=(centerDots[i,0],centerDots[i,1]),arrowprops=dict(facecolor="yellow"))
#使用sklearn库的Kmeans算法进行聚类并可视化
plt.subplot(122)
estimator = KMeans(n_clusters=k).fit(data)
plt.scatter(data[:,0], data[:,1], c=estimator.labels_)
centerDots = estimator.cluster_centers_
for i in range(len(estimator.cluster_centers_)):
plt.annotate("center", xy=(centerDots[i,0],centerDots[i,1]),arrowprops=dict(facecolor="yellow"))
plt.title("Kmeans from sklearn")
plt.show()
2、结果
① 结果1

3、分析
对比结果1中展示的两个聚类结果,可以发现,上述代码实现的K-means算法聚类效果与sklearn库中的K-means算法效果基本一致,且二者的聚类结果都比较符合数据集实际分布情况。















 4748
4748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









