






一. ARM System MMU architecture框架
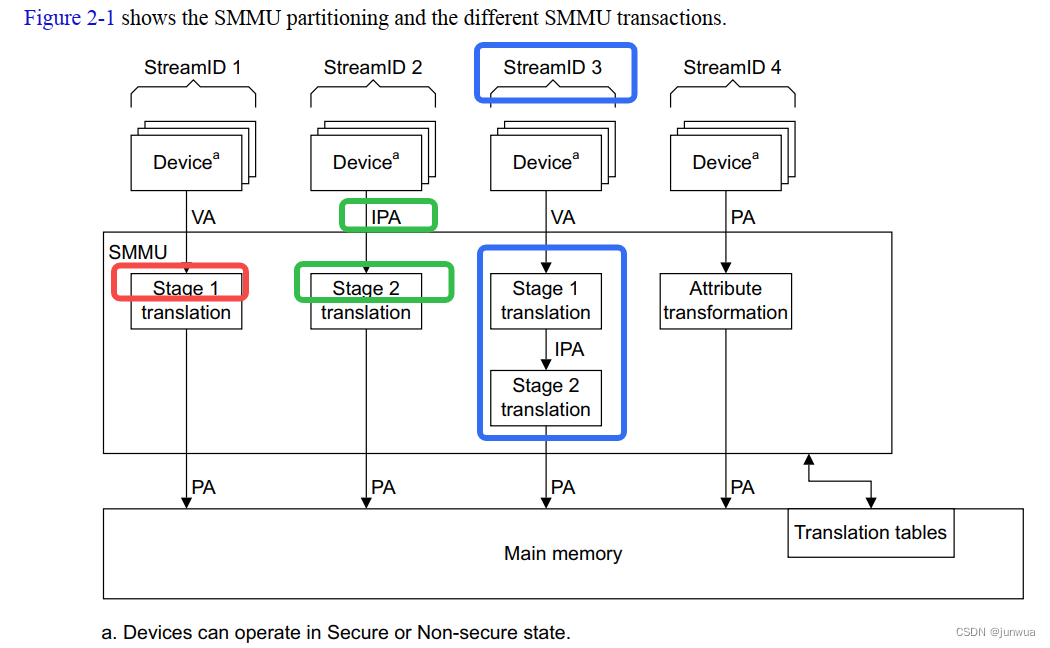
The ARM System MMU (SMMU) architecture provides a flexible implementation framework for a Memory Management Unit (MMU) implementation, with a number of IMPLEMENTATION DEFINED options. The architecture can be used for a system-level MMU. It supports address translation from an input address to an output address, based on address mapping and memory attribute information held in translation tables. An address translation from an input address to an output address is described as a stage of address translation. The SMMU architecture also supports the concept of translation regimes, in which a required memory access might require two stages of address translation.
For example, in a virtualized processor implementation: • An operating system defines the translation tables for its own memory accesses, and for accesses by applications running under it. It does this believing it is mapping the virtual addresses (VAs) used by the processor to physical addresses (PAs) in the physical memory system. However, it actually defines addresses in an intermediate physical address (IPA) memory map. • A hypervisor defines the translation tables that translate the IPAs for a particular guest operating system to PAs.
当Guest OS 和应用程序访问内存时,需要2个Stage This means that any memory access by a Guest OS, or by an application, requires two stages of translation, that together define a single translation regime: • Stage 1, from VA to IPA. • Stage 2, from IPA to PA. Within this system, the hypervisor must also define the required translation tables for its own memory accesses. These are in a separate translation regime, with only one stage of translation in which the stage 1 translation maps VAs to PAs.
当hypervisor虚拟机监控程序(VMM)访问内存时,可以只需要Stage 1,VAs to PAs
A single stage of address translation can require multiple translation table lookups. In this case, each translation table lookup is described as a level of address lookup.
An implementation of the ARM SMMU architecture can provide: • Multiple transaction contexts that apply to specific streams of transactions. • Single or two stage translation. • For any stage of translation, multiple levels of address lookup, to provide fine-grained memory control. • Fault handling, logging, and signaling functionality. • Debug and OPTIONAL performance monitoring functionality
-
什么是SMMU
SMMU(system mmu),是I/O device与总线之间的地址转换桥。
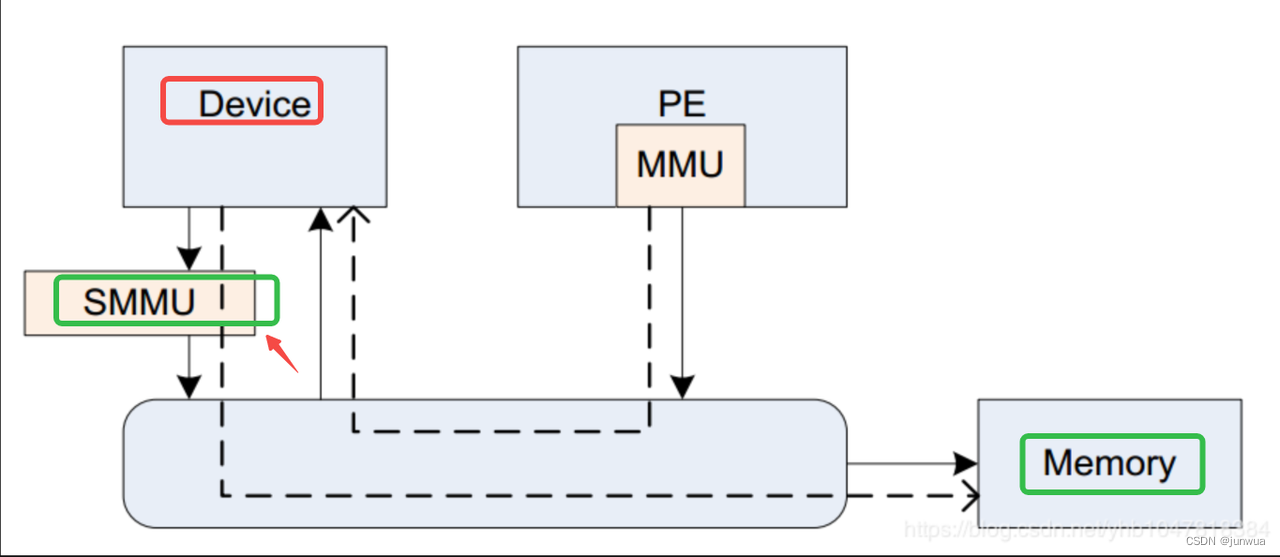
-
为什么需要SMMU
了解SMMU出现的背景,需要知道系统中的两个概念:DMA和虚拟化。
1-DMA
DMA:((Direct Memory Access),直接内存存取, 是一种外部设备不通过CPU而直接与系统内存交换数据的接口技术 。外设可以通过DMA,将数据批量传输到内存,然后再发送一个中断通知CPU取,其传输过程并不经过CPU, 减轻了CPU的负担。但由于DMA不能像CPU一样通过MMU操作虚拟地址,所以DMA需要连续的物理地址。
2-虚拟化
虚拟化:在虚拟化场景, 所有的VM都运行在中间层hypervisor上,每一个VM独立运行自己的OS(guest OS), Hypervisor完成硬件资源的共享, 隔离和切换。
VA : virtual addresses (VAs) 虚拟地址
IPA : intermediate physical address (IPA) memory map 中间层 物理地址
PA : physical addresses (PAs) 物理地址
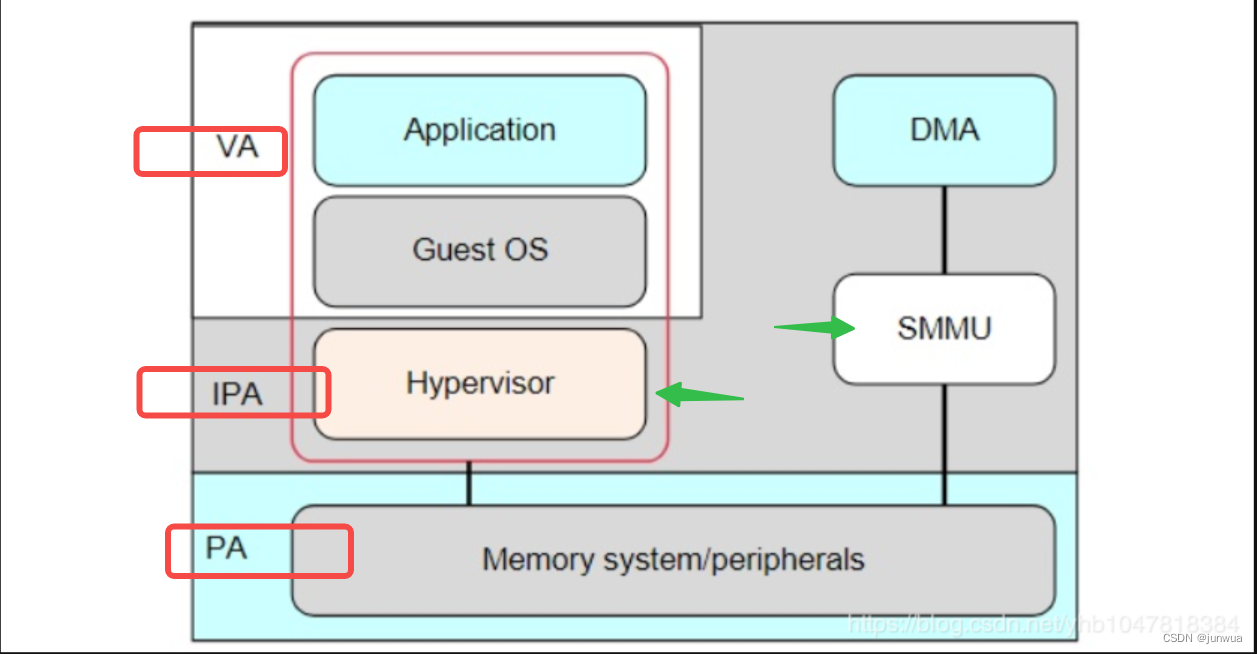
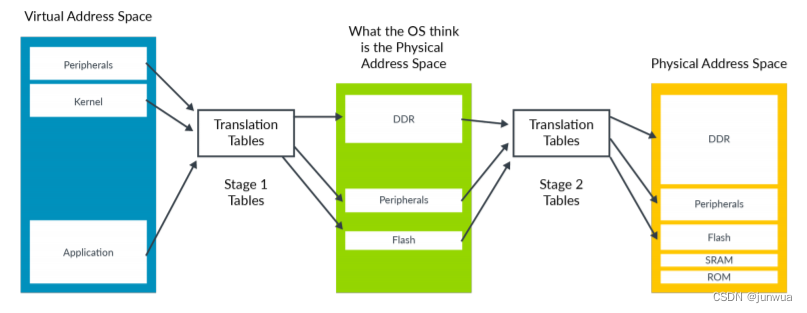
地址转换:SMMU跟MMU一样,支持两级转换Stage 1 Translation和Stage2 Translation,例如VA<->IPA<->PA,但是在现实使用中,也可以直接bypass,stage 1 only,stage2 only,或者Stage 1+Stage 2
内存保护:(S)MMU除了支持地址转换外,内存属性也是重要的部分,例如可以在页表内配置读写权限,执行权限,访问权限等
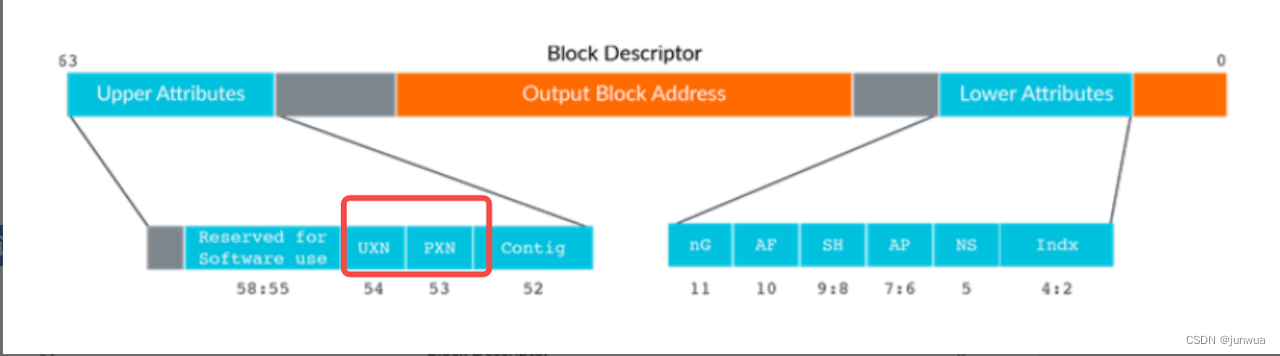
内存区域权限 由 AP、APX 和 Domain(域) 共同控制,如下:
AP/APX:字段 AP 和 APX 的不同组合将形成不同的 访问权限,如图所示。按照笔者理解,
Privileged 指的是 CPU 处于 svc 等状态,而 Unprivileged 则为 CPU 处于 user 状态。
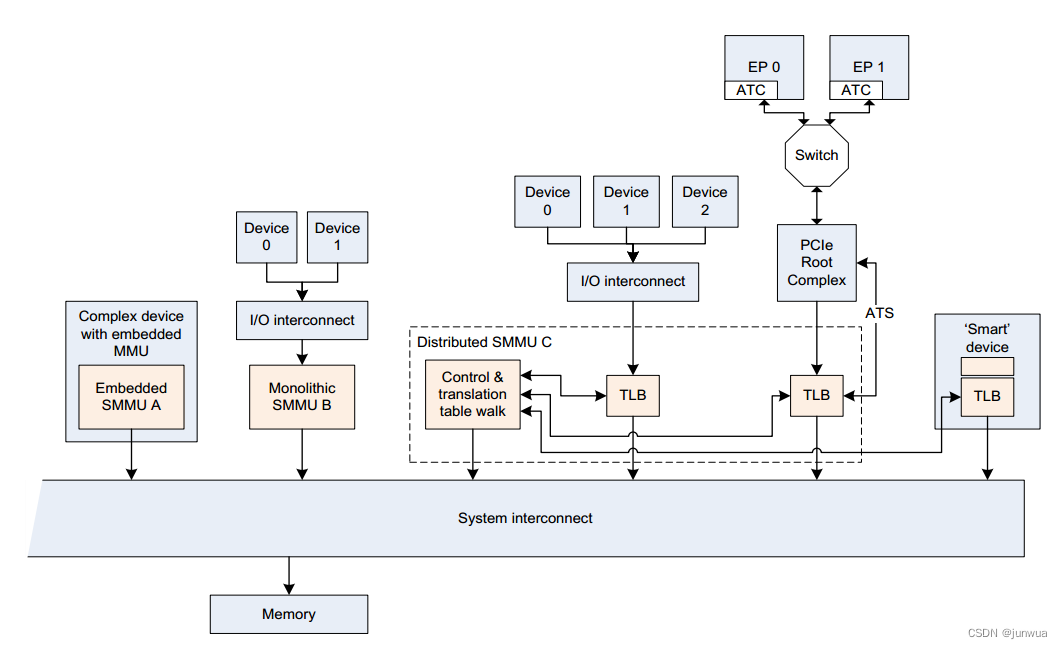
隔离:SMMU同时可以给多个Master使用,例如SMMUv2支持128个contexts,SMMUv3支持更多的Contexts,因为在SMMUv2中contexts的信息是保存在寄存器,在SMMUv3中context的信息是存储在内存里面,通过StreamID来查询,Stream ID是32位的。CPU可以和其他Master使用同一套页表,或者CPU可以SMMU单独建立页表,或者可以为每个Master建立一套或者多套页表,来控制不同的访问区域。
访问非连续的地址
现在系统中很少再预留连续的memory,如果Master需要很多memory,可以通过SMMU把一些非连续的PA映射到连续的VA,例如给DMA,VPU,DPU使用。
32位转换成64位
现在很多系统是64位的,但是有些Master还是32位的,只能访问低4GB空间,如果访问更大的地址空间需要软硬件参与交换memory,实现起来比较复杂,也可以通过SMMU来解决,Master发出来的32位的地址,通过SMMU转换成64位,就很容易访问高地址空间。
限制Master的访问空间
Master理论上可以访问所有的地址空间,可以通过SMMU来对Master的访问进行过滤,只让Master访问受限的区域,那这个区域也可以通过CPU对SMMU建立页表时动态控制。
用户态驱动
现在我们也看到很多系统把设备驱动做在用户态,调用驱动时不需要在切换到内核态,但是存在一些安全隐患,就是用户态直接控制驱动,有可能访问到内核空间,这种情况下也可以用SMMU来实现限制设备的访问空间
TCU:translation control unit 传输控制单元
TBU:tanslation buffer unit 用于缓存设备和SMMU之间交互的事务
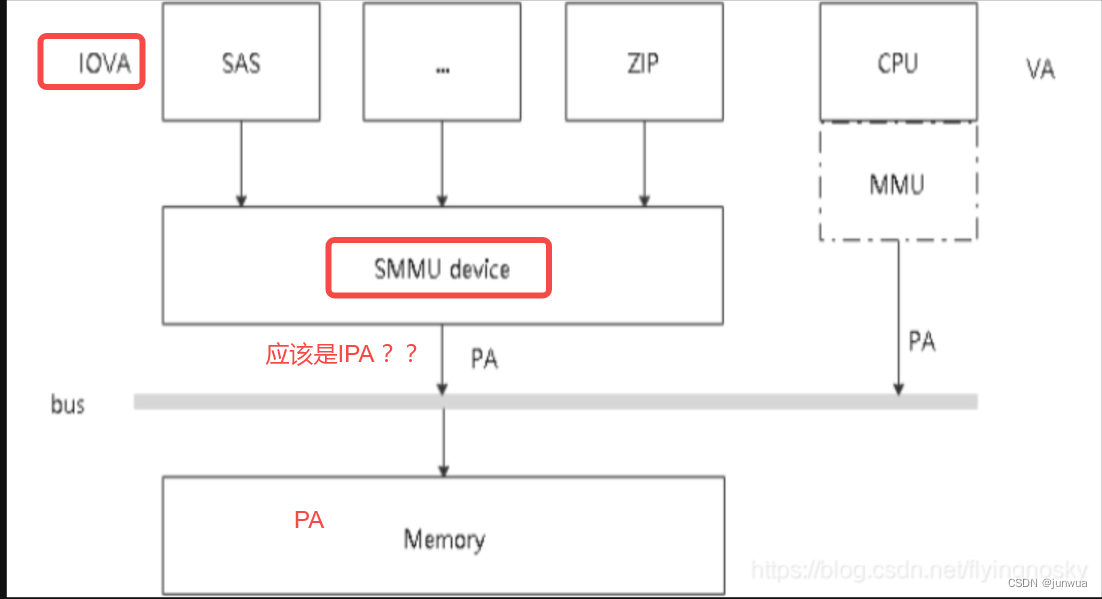
IOVA:IO virtual address IOVA 是设备的虚拟地址,它是设备看到的地址。
StreamID: device 通过物理线连接到SMMU ,这个StreamID就是用来标识SMMU上连接的设备。
TCU 用来管理页表,master发出一个VA请求,首先到TCU,TCU会去找页表,找到之后将PA传给TBU,TBU实际发送访问
TCU:SMMU(System MMU)中的子模块,主要负责地址转换和内存访问权限的控制。
在虚拟化环境中,SMMU起到了管理设备和主存之间内存映射关系的作用。SMMU TCU是其中一个重要的组成部分,它负责处理虚拟地址到物理地址的转换和权限控制。
SMMU TCU 通过管理页表或映射表等数据结构来实现地址转换。当设备发送一个虚拟地址到SMMU时,TCU会根据页表或映射表查找相应的映射关系,然后将虚拟地址转换为物理地址。这个过程可能需要考虑页表的级联、TLB(Translation Lookaside Buffer)缓存的管理等。
同时,SMMU TCU也负责对内存访问的权限进行控制。它会检查设备对内存的读写权限,并与页表或映射表中的权限位进行比较,以确定是否允许设备执行相应的内存访问操作。
通过使用SMMU TCU,可以实现对设备访问物理内存的控制和隔离。它可以保护系统的安全性,防止设备越权访问内存,并提供更灵活的内存管理和地址转换功能,以适应虚拟化环境的需求。
TBU:SMMU(System MMU)中的子模块,主要用于缓存设备和SMMU之间交互的事务,以提高系统性能。
在虚拟化环境中,SMMU起到了管理设备与主存之间内存映射关系的作用。当设备进行一次内存访问时,需要经过多次的地址转换和权限检查等操作。这些操作可能涉及到多个硬件模块和复杂的计算,会对系统性能产生负面影响。
为了提高系统性能,SMMU引入了TBU模块。当设备发送一个内存访问请求到SMMU时,TBU会将请求缓存到内部的事务队列中,并等待SMMU完成相关操作后再将结果返回给设备。这样,在多个访问请求之间可以实现乱序执行,从而提高系统并发度和吞吐量。
同时,SMMU TBU还支持多种优化技术,例如乱序执行、流水线运行、事务合并等。这些技术可以进一步提高系统性能,减少因硬件调度带来的延迟和开销,并确保设备和SMMU之间的数据一致性
IOVA 是设备的虚拟地址,它是设备看到的地址。当设备进行DMA访问时,使用的是IOVA作为地址进行内存操作。IOVA通常是由设备驱动程序根据设备的规格和约束生成的,用于标识设备需要读写的内存位置。
IPA 是系统中的一个特定地址空间,用于表示设备访问的中间物理地址。当设备的IOVA需要转换成物理地址时,系统会使用SMMU(System MMU)等硬件模块将IOVA转换为IPA,然后再进一步转换为最终的物理地址。
这个IOVA到IPA的转换过程涉及到地址映射和权限控制等操作。在虚拟化环境下,SMMU负责管理设备和主存之间的内存映射关系,并进行IOVA到IPA的转换。SMMU会根据页表或映射表等数据结构,查找对应的映射关系,将IOVA转换为IPA,然后再由物理地址生成最终的物理地址。
TLB:System MMU Translation Lookaside Buffer,是SMMU的翻译后备缓冲器,快速匹配相当于cache
StreamID: device 通过物理线连接到SMMU ,这个StreamID就是用来标识SMMU上连接的设备。想象一个8 ports hub上连接了8个物理设备,这8个设备就可以通过portID来标识,比如port 0代表第一个设备,同理steamID。
STE: stream Table Entry,可以理解为SMMU页表转换的第一级索引,每一个streamID代表着一个STE,通过这个STE指向的连接可以找到真正的虚地址-->物理地址转换的页表。假设SMMU上连接着8个具体设备,每个设备都有自己的StreamID,那就有至少8个STE表项。
CD: Context Descriptor, stage 1的页表配置项,用于一个设备中不同的进程,它其中的TTB0指向了真正的页表信息,比如PGD, PMD, PTE等,完全和MMU的页表转换原理一样;
GPA: guest VM使用的物理地址是GPA
但对于Hypervisor + GuestOS的虚拟化系统来说, guest VM使用的物理地址是GPA, 看到的内存并非实际的物理地址(也就是HPA),因此Guest OS无法正常的将连续的物理地址分给硬件。(分给外设)
因此,为了支持I/O透传机制中的DMA设备传输**,而引入了IOMMU技术(ARM称作SMMU)。**
总而言之,SMMU可以为ARM架构下实现虚拟化扩展提供支持。它可以和MMU一样,提供
S1: stage1转换(VA->PA), 或者
S2: stage2转换(IPA->PA) Hypervisor层的地址转换 Xml 代码中的S2意思 ,或者
stage1 + stage2转换(VA->IPA->PA)的灵活配置。
-
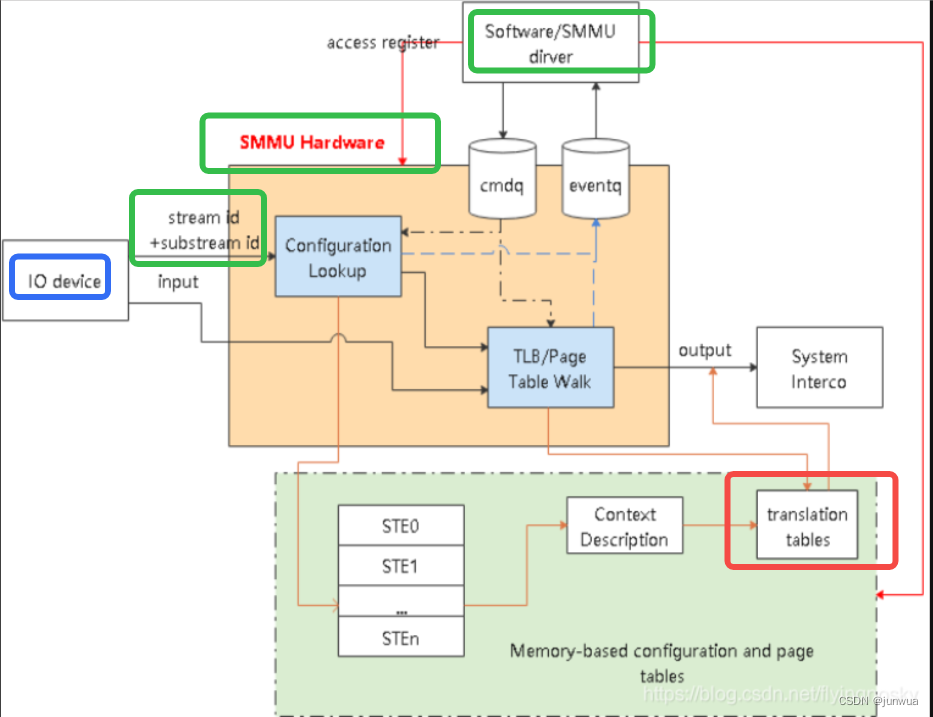
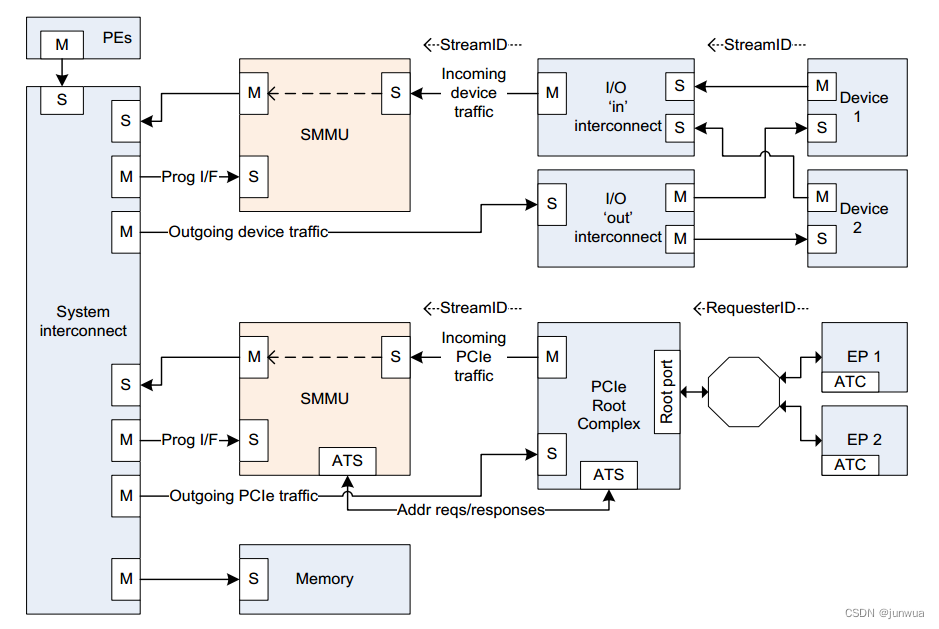
SMMU在系统中位置和作用
SMMU功能与MMU功能类似,将IO设备的DMA地址请求(IOVA)转化为系统总线地址(PA),实现地址映射、属性转换、权限检查等功能,实现不同设备的DMA地址空间隔离。
4. SMMU软硬件交互过程
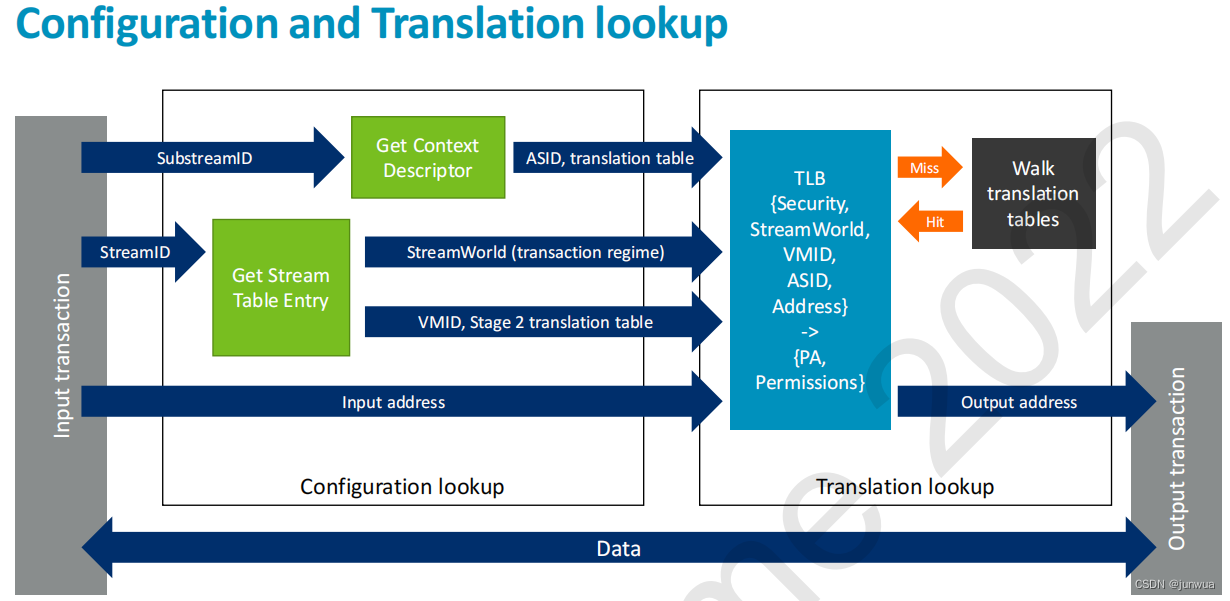
查找过程:
假设stream ID为16的设备发起了DMA操作(如下动作完全自动完成,前提是之前配置好了SMMU中所有的表项):
StreamID=16, 所以从寄存器strtab_base指向的地址中找到偏移为16的STE表项
该表项中的s1ContexPtr指向了下一级的stage 1转换地址 CD(Context Descriptor)
CD 中的TTB0指向了一个页表转换的基地址PGD
PGD- PMD- PTE 完成了虚拟地址到物理地址的转换(和MMU工作原理一样)
注:其中引入的VMID, ASID的原因和MMU一样,都是为了在TLB中加于区别,防止cache bouncing
Stage2 的转换原理基本和Stage 1一致,不过没有额外的CD
ASID:Address Space ID 地址空间标识符
HPA: Host Phyical Address 主机物理地址
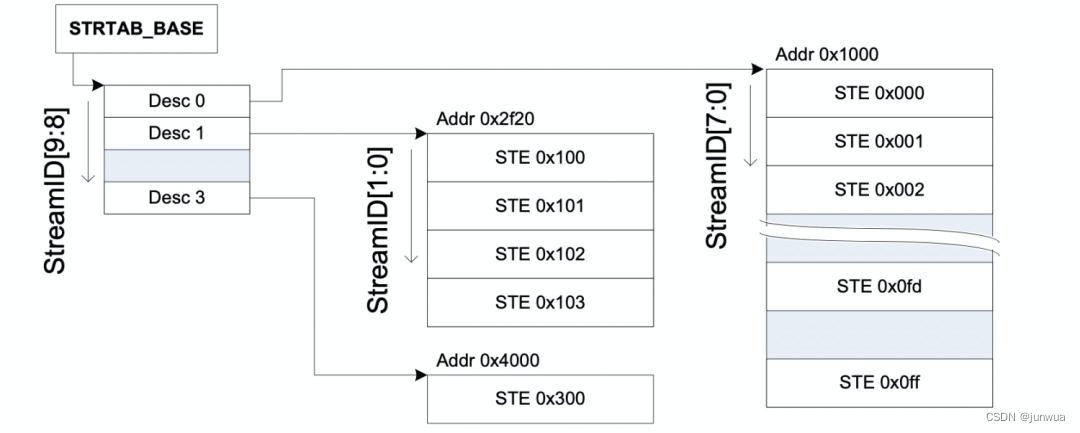
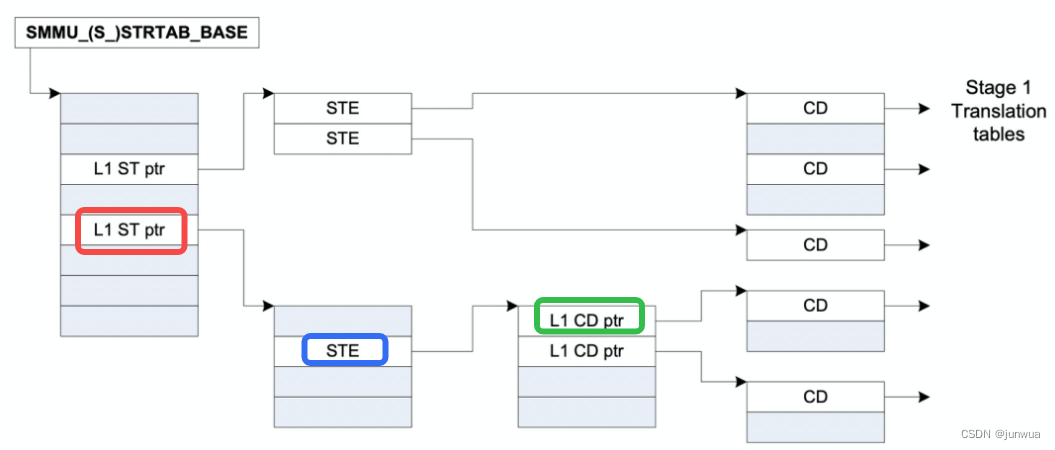
StreamTable (STE)
smmu的重要的用来dma地址翻译的数据结构都是放在内存中的,由smmu的寄存器保存着这些表在内存中的基地址,首先就是StreamTable(STE),这ste 表既包含stage1的翻译表结构也包含stage2的翻译结构,所谓stage1负责VA 到 PA的转换,stage2负责IPA到PA的转换。
对smmu来说,一个smmu可以给很多个设备服务,所以,在smmu里面为了区分的对每个设备进行管理,smmu 给每一个设备一个ste entry,那设备如何定位这个ste entry呢?对于一个smmu来说,我们给他所管理的每个设备一个唯一的device id,这个device id又叫 stream id,硬件设计相关;对于设备比较少的情况下,我们的smmu 的ste 表,很明显只需要是1维数组就可以了,如下图:
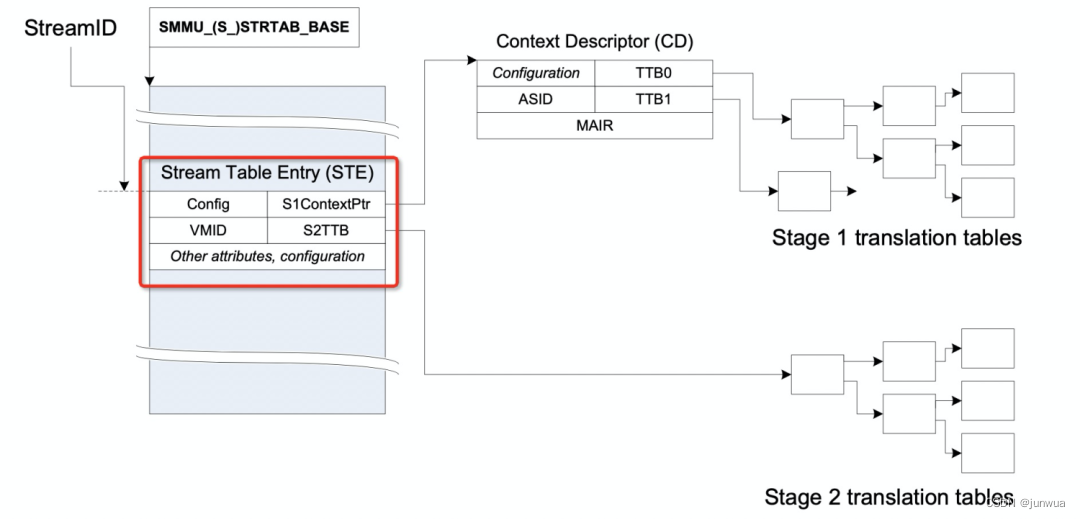
如上图所示,红框中就是smmu中一个ste entry的全貌了,从红框中能看出来,这个ste entry同时管理了stage1 和 stage2的数据结构;其中config是表示ste有关的配置项,这个不需要理解也不需要记忆,不知道的查一下smmuv3的手册即可,里面的VMID是指虚拟机ID,这里我们重点关注一下S1ContextPtr和S2TTB。
首先我们来说S1ContextPtr:
这个S1ContextPtr指向的一个Context Descriptor的目录结构,这张图为了好理解只画了一个,在我们arm中,如果没有虚拟机参与的话,无论是cpu还是smmu地址翻译都是从va->pa/iova->pa,我们称之为stage1,也就是不涉及虚拟,只是一阶段翻译而已。
重要的CD表,读到这里,你是不是会问一个问题,在smmu中我们为何要使用CD表呢?原因是这样的,一个smmu可以管理很多设备,所以用ste表来区分每个设备的数据结构,每个设备一个ste表。那如果每个设备上跑了多个任务,这些任务又同时使用了不同的page table 的话,那咋管理呢?对不对?所以smmu 采用了CD表来管理每个page table;
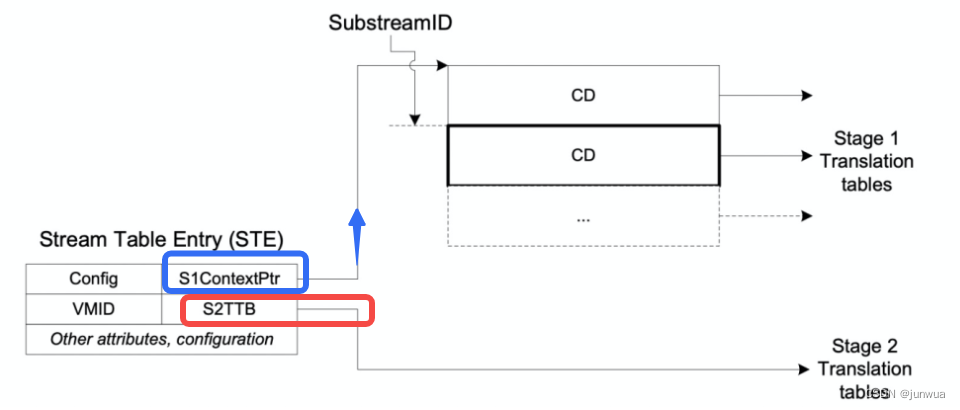
先说另外一个重要的概念:SubstreamID(pasid),这个叫substreamid又称之为pasid,也是非常简单的概念,既然有表了,那也得有id来协助查找啊,所以就出来了这个id,从这里也可以看出来,道理都一样,用了表了就有id
SSID(substream id)指明了CD数据结构的偏移,如上图所示;举例:如果SMMU选择进行linear, 则使用S1ContextPTR + 64 * ssid 找到CD。
SMMUv1主要是支持Armv7-A的页表格式,SMMUv2主要是支持Armv8.1-A的页表格式,SMMUv3相对SMMUv2更新很大,除了支持最新Armv8.x-A的特性,同时支持更多的context,支持PCIe,也支持Message based interrupt配合GICv3等。那其他Master通过SMMU可以支持下面的功能:
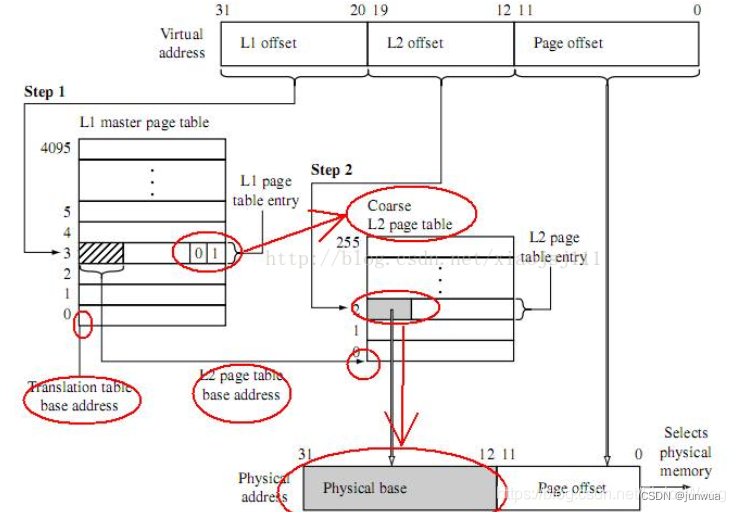
MMU工作时候需要类似如下的页表转换来支撑,同样SMMU也需要。
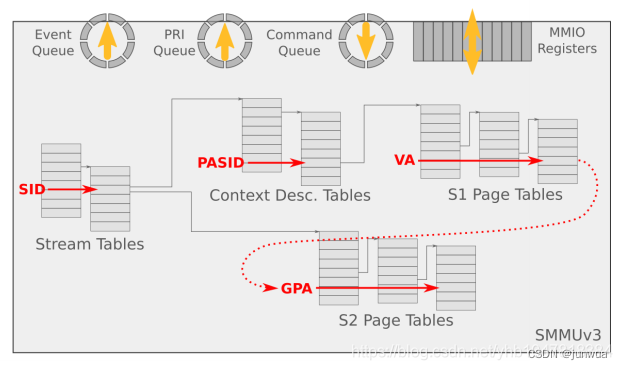
在两阶段地址翻译场景下, 地址转换流程步骤:
-
Guest驱动发起DMA请求,这个DMA请求包含VA + SID前缀
-
DMA请求到达SMMU,SMMU提取DMA请求中的SID就知道这个请求是哪个设备发来的,然后去StreamTable索引对应的STE
-
从对应的STE表中查找到对应的CD,然后用ssid到CD中进行索引找到对应的S1 Page Table
-
IOMMU进行S1 Page Table Walk,将VA翻译成IPA并作为S2的输入
-
IOMMU执行S2 Page Table Walk,将IPA翻译成PA,地址转化结束
SMMU command queue 与 event queue
系统软件通过Command Queue和Event Queue来和SMMU打交道,这2个Queue都是循环队列。
Command queue用于软件与SMMU的硬件交互,软件写命令到command queue, SMMU从command queue中 地区命令处理。 Event Queue用于SMMU发生软件配置错误的状态信息记录,SMMU将配置错误信息写到Event queue中,软件通过读取Event queue获得配置错误信息并进行配置错误处理。
SubstreamID (pasid) GPA: guest VM使用的物理地址

















 1919
1919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









