







0x0. 介绍
这篇文章主要是来介绍一下TVM的CodeGen流程。TVM自动代码生成的接口是tvm.build和tvm.relay.build,tvm.build是用来做算子的代码生成,而tvm.relay.build是用来做relay计算图的自动代码生成(这里代码生成已经包含了编译流程)。接下来我们就从这两个函数讲起,一直到TVM的Codegen的具体实现。阅读这篇文章之前建议先了解一下TVM的编译流程,即看一下【从零开始学深度学习编译器】六,TVM的编译流程详解 这篇文章。
0x1. 如何查看生成的代码
对于Relay要查看生成的代码示例如下:
from tvm import relay
from tvm.relay import testing
import tvm
# Resnet18 workload
resnet18_mod, resnet18_params = relay.testing.resnet.get_workload(num_layers=18)
with relay.build_config(opt_level=0):
graph, lib, params = relay.build_module.build(resnet18_mod, "llvm", params=resnet18_params)
# print relay ir
print(resnet18_mod.astext(show_meta_data=False))
# print source code
print(lib.get_source())
TVM给运行时Module提供了get_source来查看生成的代码,同时通过IRModule的astext函数可以查看ir中间描述。由于这里产生的的是指定设备(CPU)上的可运行的机器码,不具有可读性,就不贴了。
我们可以基于算子的自动代码生成例子来直观的感受TVM生成的代码是什么样子,因为在tvm.build接口中,target可以设置为c,即生成C语言代码。例子如下:
import tvm
from tvm import te
M = 1024
K = 1024
N = 1024
# Algorithm
k = te.reduce_axis((0, K), 'k')
A = te.placeholder((M, K), name='A')
B = te.placeholder((K, N), name='B')
C = te.compute(
(M, N),
lambda x, y: te.sum(A[x, k] * B[k, y], axis=k),
name='C')
# Default schedule
s = te.create_schedule(C.op)
ir_m = tvm.lower(s, [A, B, C], simple_mode=True,name='mmult')
rt_m = tvm.build(ir_m, [A, B, C], target='c', name='mmult')
# print tir
print("tir:\n", ir_m.astext(show_meta_data=False))
# print source code
print("source code:\n",rt_m.get_source())
生成的TIR和Source Code如下:
tir:
#[version = "0.0.5"]
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {
"global_symbol": "mmult", "tir.noalias": True}
buffers = {
C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),
B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], []),
A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], [])}
buffer_map = {
A_1: A, B_1: B, C_1: C} {
for (x: int32, 0, 1024) {
for (y: int32, 0, 1024) {
C_2[((x*1024) + y)] = 0f32
for (k: int32, 0, 1024) {
C_2[((x*1024) + y)] = ((float32*)C_2[((x*1024) + y)] + ((float32*)A_2[((x*1024) + k)]*(float32*)B_2[((k*1024) + y)]))
}
}
}
}
/* For debugging purposes the metadata section has been omitted.
* If you would like to see the full metadata section you can set the
* option to `True` when invoking `astext`.
*/
source code:
// tvm target: c -keys=cpu -link-params=0
#define TVM_EXPORTS
#include "tvm/runtime/c_runtime_api.h"
#include "tvm/runtime/c_backend_api.h"
#include <math.h>
void* __tvm_module_ctx = NULL;
#ifdef __cplusplus
extern "C"
#endif
TVM_DLL int32_t mmult(void* args, void* arg_type_ids, int32_t num_args, void* out_ret_value, void* out_ret_tcode, void* resource_handle) {
void* arg0 = (((TVMValue*)args)[0].v_handle);
int32_t arg0_code = ((int32_t*)arg_type_ids)[(0)];
void* arg1 = (((TVMValue*)args)[1].v_handle);
int32_t arg1_code = ((int32_t*)arg_type_ids)[(1)];
void* arg2 = (((TVMValue*)args)[2].v_handle);
int32_t arg2_code = ((int32_t*)arg_type_ids)[(2)];
void* A = (((DLTensor*)arg0)[0].data);
void* arg0_shape = (((DLTensor*)arg0)[0].shape);
void* arg0_strides = (((DLTensor*)arg0)[0].strides);
int32_t dev_id = (((DLTensor*)arg0)[0].device.device_id);
void* B = (((DLTensor*)arg1)[0].data);
void* arg1_shape = (((DLTensor*)arg1)[0].shape);
void* arg1_strides = (((DLTensor*)arg1)[0].strides);
void* C = (((DLTensor*)arg2)[0].data);
void* arg2_shape = (((DLTensor*)arg2)[0].shape);
void* arg2_strides = (((DLTensor*)arg2)[0].strides);
if (!(arg0_strides == NULL)) {
}
if (!(arg1_strides == NULL)) {
}
if (!(arg2_strides == NULL)) {
}
for (int32_t x = 0; x < 1024; ++x) {
for (int32_t y = 0; y < 1024; ++y) {
((float*)C)[(((x * 1024) + y))] = 0.000000e+00f;
for (int32_t k = 0; k < 1024; ++k) {
((float*)C)[(((x * 1024) + y))] = (((float*)C)[(((x * 1024) + y))] + (((float*)A)[(((x * 1024) + k))] * ((float*)B)[(((k * 1024) + y))]));
}
}
}
return 0;
}
直观的了解了一下TVM的代码生成接口(tvm.build和tvm.relay.build)之后,我们可以借助https://zhuanlan.zhihu.com/p/139089239这篇文章中总结的TVM的代码生成过程的流程图来更好的理解。
原文中的介绍是:
tvm代码生成接口上是IRModule到运行时module的转换,它完成tir或者relay ir到目标target代码的编译,例如c或者llvm IR等。下面的流程图描述整个代码的编译流程,深色表示C++代码,浅色表示python代码。算子编译时会首先进行tir的优化,分离出host和device部分,之后会调用注册的target.build.target函数进行编译。relay图编译相比算子稍微复杂一点,核心代码采用C++开发。它会通过relayBuildModule.Optimize进行relay图优化,之后针对module中的每个lower_funcs进行编译,合成最终的运行时module,其后部分的编译流程和算子编译相似。
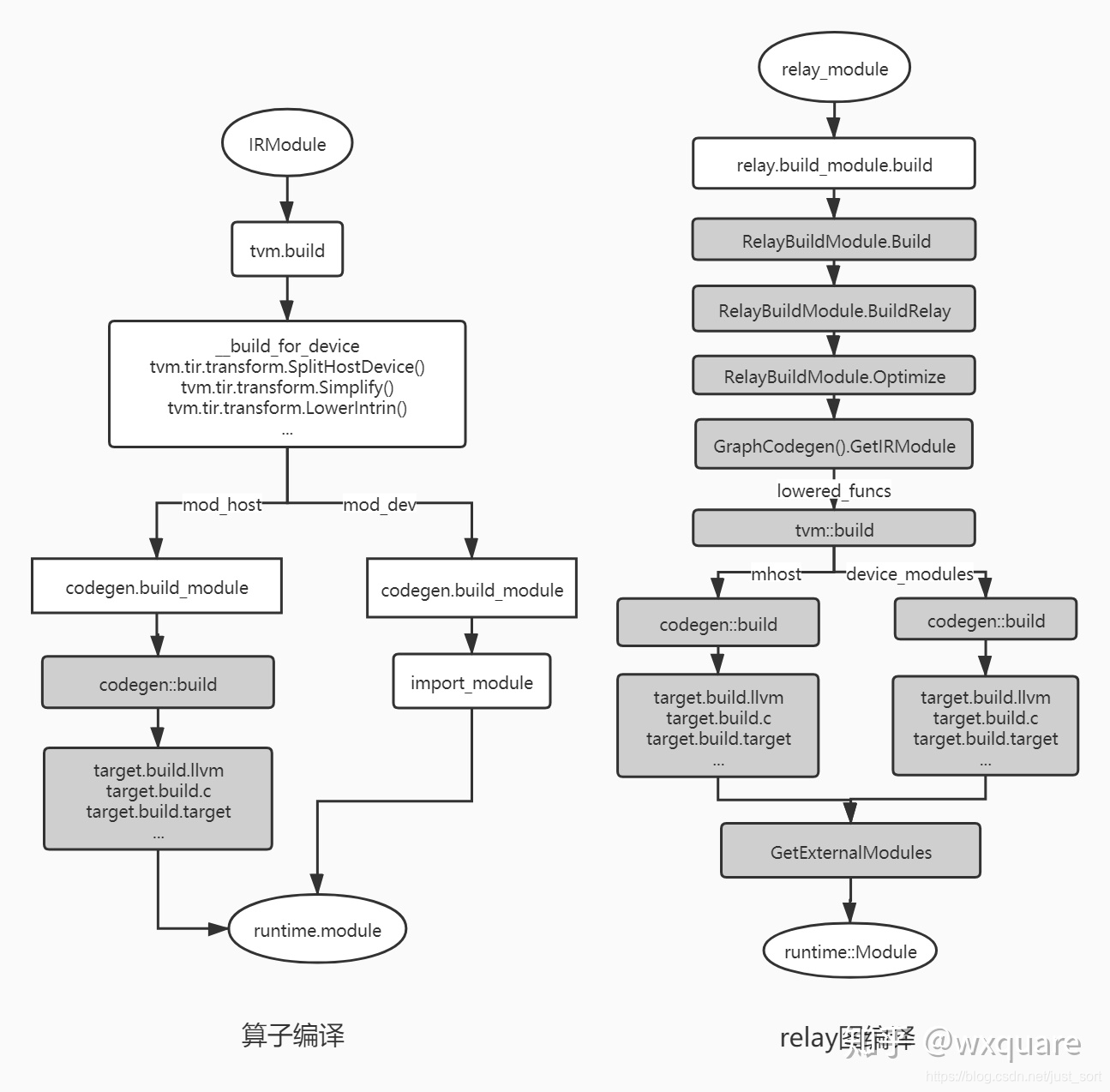
看上面的个流程图可以直观理解一下TVM Codegen的流程,这里以Relay为例子,在TVM的代码中简单的来对应一下。在上面的右图中展示了Relay Graph的完整编译流程,其中GraphCodeGen之前的部分我们已经在【从零开始学深度学习编译器】六,TVM的编译流程详解 讲过了,这里直接从创建GraphCodegen实例(graph_codegen_ = std::unique_ptr<GraphCodegen>(new GraphCodegen());)开始来梳理一下GraphCodegen的流程。这部分的代码如下:
void BuildRelay(IRModule relay_module,
const std::unordered_map<std::string, tvm::runtime::NDArray>& params) {
Target target_host = GetTargetHost();
// If no target_host has been set, we choose a default one, which is
// llvm if "codegen.LLVMModuleCreate" is accessible.
const runtime::PackedFunc* pf = runtime::Registry::Get("codegen.LLVMModuleCreate");
if (!target_host.defined()) target_host = (pf != nullptr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









