







0x0. 系列文章
- DeepSpeed-Chat 打造类ChatGPT全流程 笔记二之监督指令微调
- DeepSpeed-Chat 打造类ChatGPT全流程 笔记一
- 【DeepSpeed 教程翻译】三,在 DeepSpeed中使用 PyTorch Profiler和Flops Profiler
- DeepSpeed结合Megatron-LM训练GPT2模型笔记(上)
- 【DeepSpeed 教程翻译】二,Megatron-LM GPT2,Zero 和 ZeRO-Offload
- 【DeepSpeed 教程翻译】开始,安装细节和CIFAR-10 Tutorial
0x1. DeepSpeed ZeRO++: 大型语言模型和聊天模型训练的速度飞跃,通信量减少4倍(博客翻译)
要获取更多细节建议查看原始论文:https://www.microsoft.com/en-us/research/publication/zero-extremely-efficient-collective-communication-for-giant-model-training/
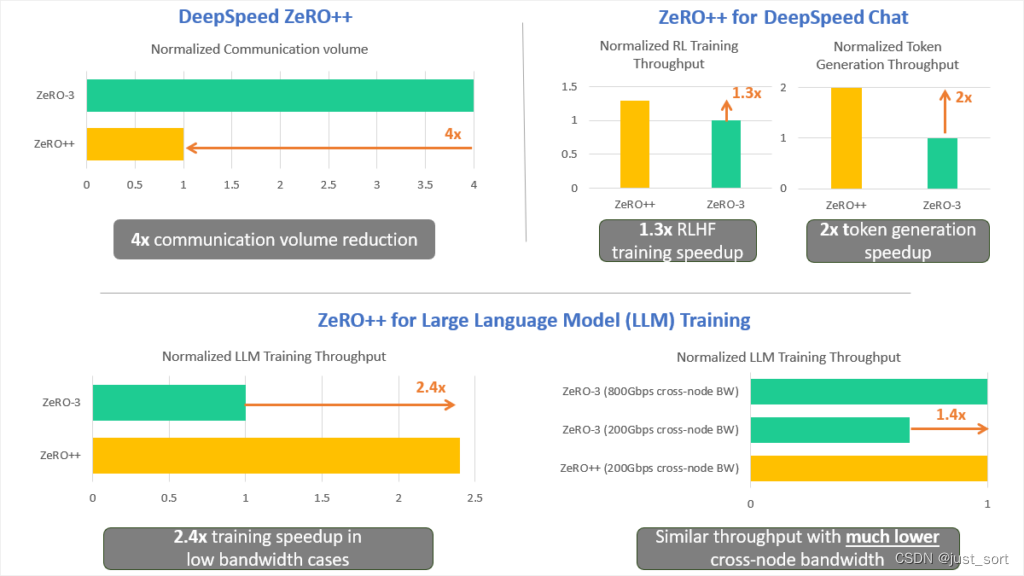
图 1:ZeRO++项目亮点展示。左上子图显示,与ZeRO阶段3相比,ZeRO++将通信量减少了4倍。右上子图显示了ZeRO++在RLHF模型训练上的表现,其中ZeRO++使RLHF训练速度提高了1.3倍,token生成速度提高了2倍。
大型AI模型正在改变数字世界。由大型语言模型(LLMs)驱动的生成性语言模型,如Turing-NLG、ChatGPT和GPT-4,具有惊人的多功能性,能够执行摘要、编码和翻译等任务。同样,像DALL·E、Microsoft Designer和Bing Image Creator这样的大型多模态生成模型可以生成艺术、建筑、视频和其它数字资产,赋能内容创作者、建筑师和工程师探索创新生产力的新疆界。
然而,训练这些大型模型需要在数百甚至数千个GPU设备上消耗大量的内存和计算资源。例如,训练Megatron-Turing NLG 530B(https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/)模型使用了超过4000个Nvidia A100 GPU。高效地利用这些资源需要一套复杂的优化系统,以将模型分割成可以放入单个设备内存的片段,并在这些设备上有效地并行计算。同时,为了让深度学习社区能够轻松地接触到大型模型训练,这些优化必须易于使用。
DeepSpeed的ZeRO优化系列为这些挑战提供了强大的解决方案,已经被广泛应用于训练大型和强大的深度学习模型,如TNLG-17B、Bloom-176B、MPT-7B、Jurrasic-1等。尽管它具有变革性的能力,但在关键的场景中,ZeRO会导致跨GPU的高数据传输开销,使得实现高训练效率变得具有挑战性。特别是当a) 相对于全局批处理大小,在数量很多的GPU上训练,这导致每个GPU的批处理大小较小,需要频繁的通信,或者b) 在低端集群上训练,其中跨节点网络带宽有限,导致通信延迟高。在这些情况下,ZeRO提供的高效训练的能力受到限制。
为了解决这些限制,我们推出了ZeRO++,这是一个基于ZeRO构建的通信优化策略系统,无论批处理大小限制或跨设备带宽约束如何,都能为大型模型训练提供无与伦比的效率。ZeRO++利用量化技术,结合数据和通信重映射,将与ZeRO相比的总通信量减少了4倍,而不影响模型质量。这有两个关键的含义:
- ZeRO++ 加速了大模型的预训练和微调
- 每张GPU小batch: 无论是在数千个 GPU 上预训练大型模型,还是在数百甚至数十个 GPU 上进行微调,当每个 GPU 的批量大小较小时,与 ZeRO 相比,ZeRO++ 可提供高达 2.2 倍的吞吐量,直接降低训练时间和成本。
- 低带宽集群:ZeRO++使得低带宽集群能够实现与带宽高4倍的集群相似的吞吐量。因此,ZeRO++使得更广泛种类的集群都能高效地进行大模型训练。
- ZeRO++加速了类似ChatGPT的模型训练,使用的是RLHF(Reinforcement Learning from Human Feedback)方法。
虽然ZeRO++主要是为训练而设计的,但是其优化也自动应用于ZeRO-Inference,因为通信开销对于使用ZeRO的训练和推理都是共同的。因此,ZeRO++提高了如在训练对话模型中使用的人类反馈强化学习(RLHF)这类工作负载的效率,它结合了训练和推理。
通过与DeepSpeed-Chat的集成,相比原始的ZeRO,ZeRO++可以将RLHF训练的生成阶段提升高达2倍,以及强化学习训练阶段提升高达1.3倍。
接下来,我们将深入探讨ZeRO及其通信开销,并讨论ZeRO++中用于解决这些问题的关键优化。然后,我们将展示ZeRO++对于不同模型大小、批量大小和带宽限制下的训练吞吐量的影响。我们还将讨论如何将ZeRO++应用于DeepSpeed-Chat以加速使用RLHF训练对话模型。
深入到ZeRO++
https://youtu.be/lQCG4zUCYao
这个链接对应的视频描述了zero的工作流,读者可以自己打开看一下。
ZeRO是数据并行性的一种内存高效变体,其中模型状态被分配到所有GPU上,而不是被复制,并在训练过程中使用基于all-gather/broadcast的通信集合即时重建。这允许ZeRO有效地利用所有设备的总GPU内存和计算能力,同时提供数据并行训练的简单性和易用性。
假设模型大小为M。在前向传递中,ZeRO在需要每个模型层的参数之前进行全体all-gather/broadcast操作(总共大小为M)。在反向传递中,ZeRO采用类似的通信模式来计算每一层参数的局部梯度(总共大小为M)。此外,ZeRO使用reduce或reduce-scatter通信集合立即对每个局部梯度进行平均和分区(总共大小为M)。总的来说,ZeRO的通信量为3M,均匀分布在两个all-gather/broadcast和一个reduce-scatter/reduce操作之间。
reduce-scatter + all-gather = all reduce。这里关于通信量为3M指的是zero-1 stage,这里关于通信量的描述比较模糊,建议大家查看 图解大模型训练之:数据并行下篇(ZeRO,零冗余优化) ,这里对Zero的通信量分析和显存分析以及通信原语的描述更直观和准确。
为了减少这些通信开销,ZeRO++有三套通信优化,分别针对上述三种通信集合:
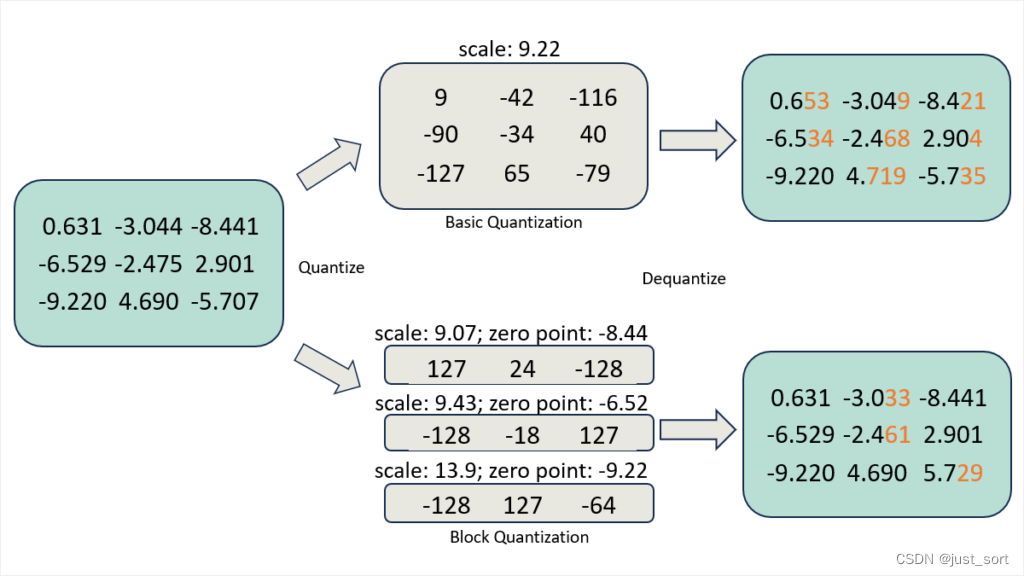
图3:DeepSpeed ZeRO++的Block量化图示。该图展示了相比基本量化,Block量化具有更好的数据精度。
量化ZeRO权重通信(qwZ)
首先,为了减少在all-gather期间的参数通信量,我们采用了对权重的量化,该方法在通信前将每个模型参数即时从FP16(两字节)压缩到INT8(一字节)的数据类型,并在通信后对权重进行反量化。然而,简单地对权重进行量化可能会降低模型训练的精度。为了保持良好的模型训练精度,我们采用了基于Block的量化,它对模型参数的每个子集进行独立的量化。目前还没有用于高性能,基于Block的量化的现有实现。因此,我们从零开始实现了高度优化的量化CUDA kernel,它比基本的量化更准确3倍,速度更快5倍。
用于 ZeRO (hpZ)的层次性权重划分(Hierarchical weight partition)
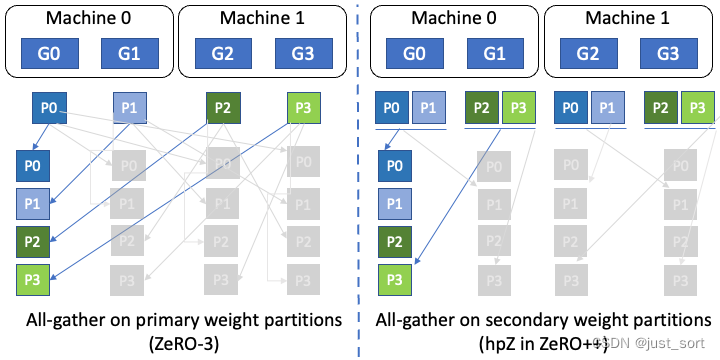
图 4:hpZ中的层次性权重划分。该图显示hpZ在每个GPU上持有次级模型划分,而zero-3仅持有主要模型划分。
其次,为了减少反向传播过程中权重上的 all-gather 通信开销,我们选择用 GPU 内存来换取通信。具体而言,我们并不是像在 ZeRO 中那样将整个模型权重分布在所有的机器中,而是在每台机器内维护一份完整的模型副本。尽管这会带来更高的内存开销,但它使我们能够用机器内的 all-gather/broadcast 替换昂贵的跨机器 all-gather/broadcast,由于机器内通信带宽更高,所以这个过程会快很多。
对于hpZ的理解还可以参考知乎的 https://zhuanlan.zhihu.com/p/641297077:
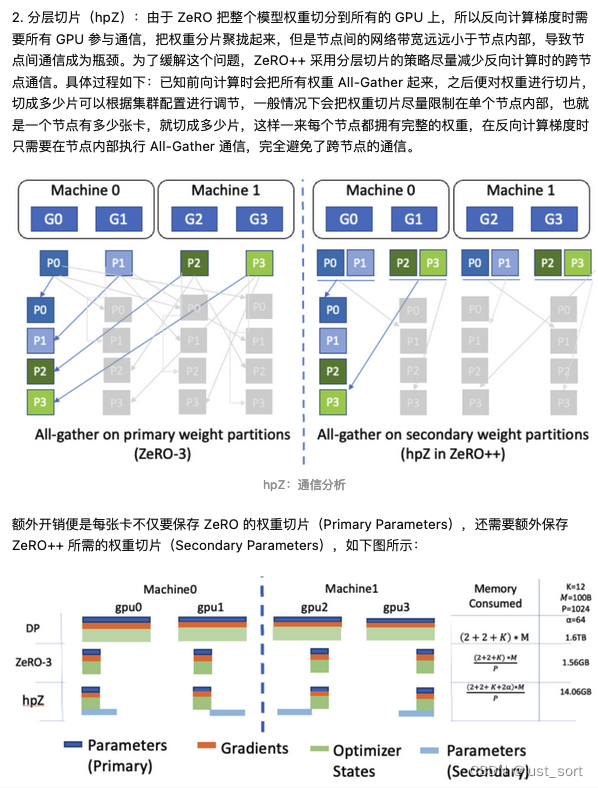
图中的M表示模型的参数量,K表示模型必存的内存系数,如下表所示:
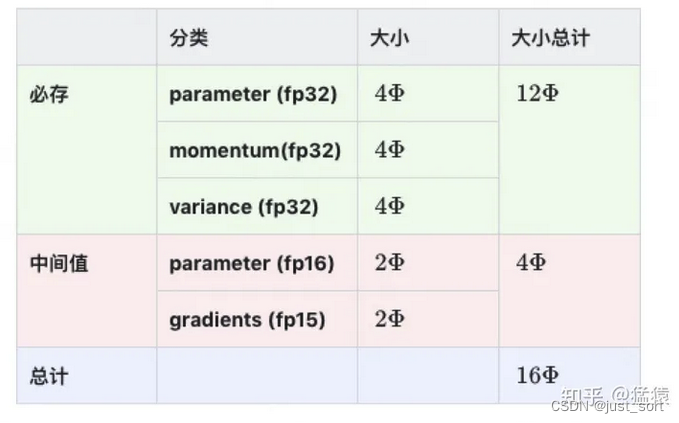
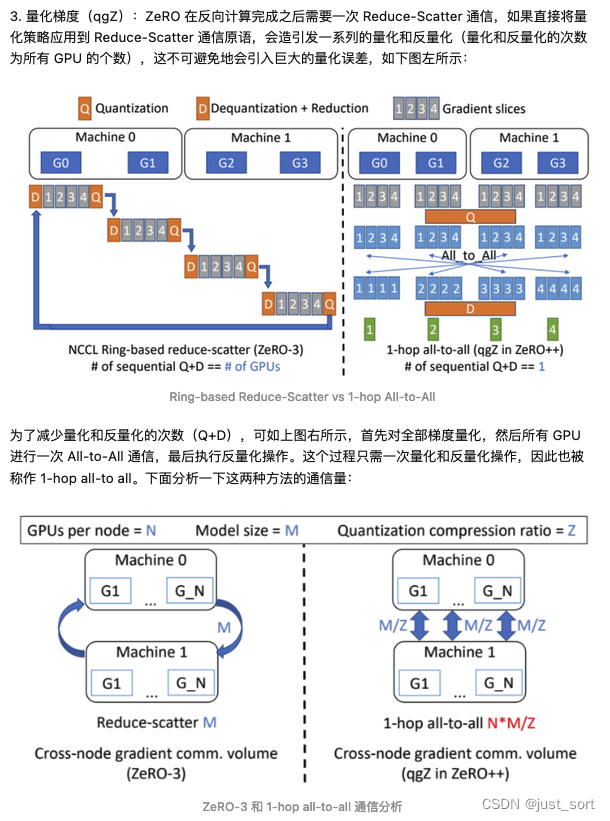
为 ZeRO 量化梯度通信(qgZ)
qgZ部分需要结合论文进行理解,也可以参考这篇博客的qgZ部分,讲诉得比较清楚:
https://zhuanlan.zhihu.com/p/641297077 。对博主这部分的解读截图一下:
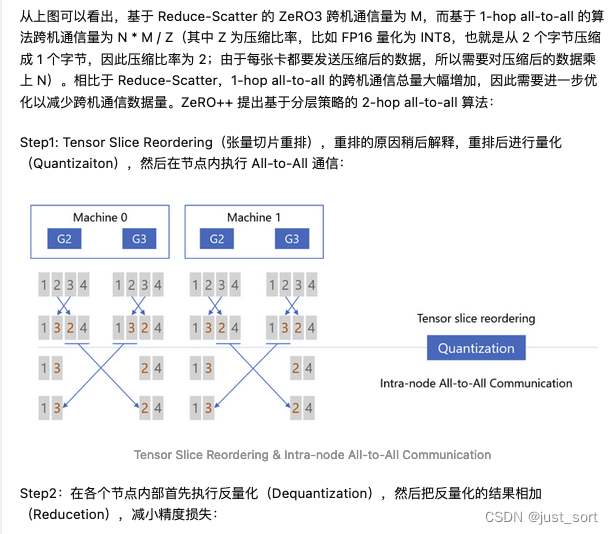



ZeRO++ 加速 LLM training
这里我们展示了使用384个Nvidia V100 GPU进行实际LLM训练场景的ZeRO++评估结果。
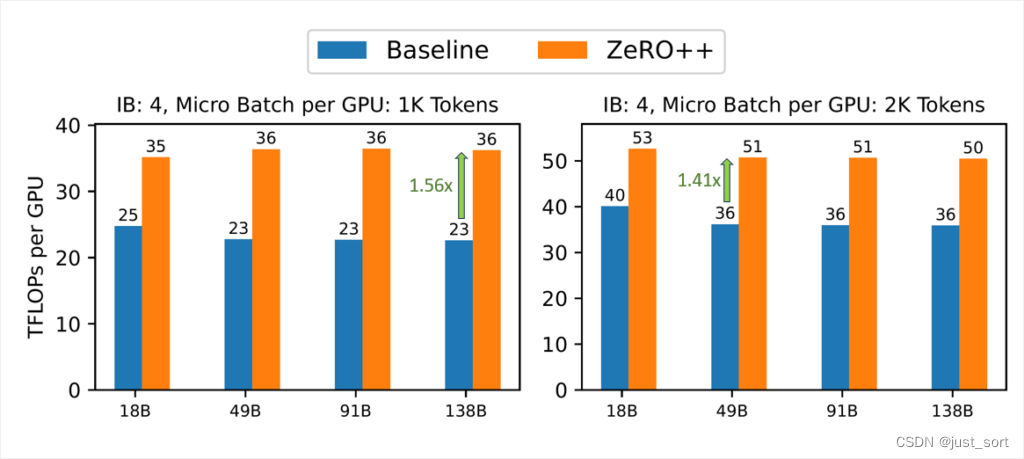
图6:400 Gbps互连的zero++与zero的吞吐量比较。图表显示,当每个GPU有1k个token时,zero++可以实现最高1.56倍的加速,而当每个GPU有2k个token时,可以实现1.41倍的加速。
在每个GPU batch很小时实现高效率
高带宽集群:如图6所示,我们首先展示了在使用4x Infiniband (IB) 的400Gbps跨节点互联(由4个带宽为100Gbps的Infiniband(IB)提供)下,ZeRO++相对于ZeRO在不同模型大小和微批次大小下的吞吐量提升。在每个GPU上1k个token的情况下,ZeRO++相对于ZeRO-3获得了28%到36%的吞吐量提升。在2k的微批次大小下,ZeRO++相对于ZeRO-3获得了24%到29%的吞吐量提升。

图 7:ZeRO++ 与 ZeRO 在100Gbps互联环境下的吞吐量比较。图表显示,在每个 GPU 1k token 的情况下,ZeRO++ 相比于 ZeRO 实现了2.21倍的加速,而在每个 GPU 2k token 的情况下实现了1.77倍的加速。
低带宽集群:在像100Gbps网络这样的低网络环境中,ZeRO++的表现显著优于ZeRO-3。如图7所示,与ZeRO-3相比,ZeRO++在端到端吞吐量上实现了最多2.2倍的加速。平均来看,ZeRO++比ZeRO-3基线实现了大约2倍的加速。
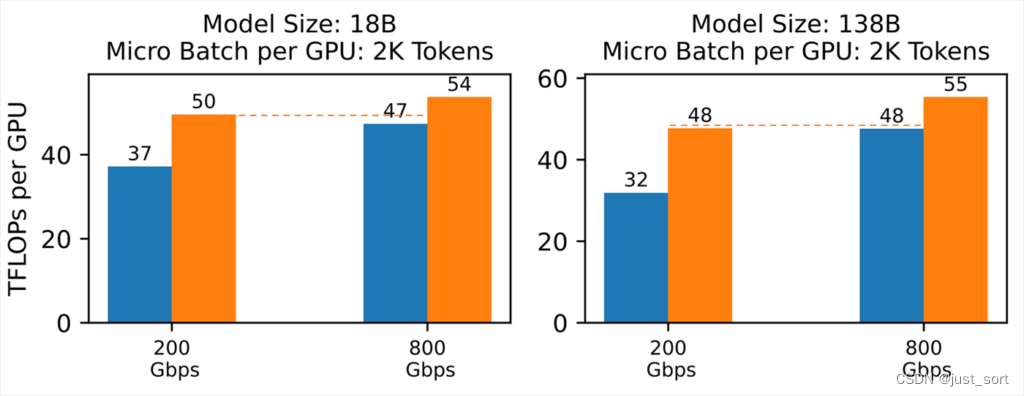
图8:低带宽连接的ZeRO++实现了与高带宽连接的ZeRO相似的吞吐量。图表显示,在18B和138B的模型大小中,与高带宽连接的ZeRO相比,低带宽网络的ZeRO++实现了相似的吞吐量。
实现高带宽和低带宽集群间的效率平衡
此外,与高带宽环境中的ZeRO相比,ZeRO++可以在低带宽集群中实现可比的系统吞吐量。如图8所示,对于18B和138B的模型,带有200Gbps跨节点链接的ZeRO++可以达到与800 Gbps跨节点链接设置中的ZeRO-3相似的TFLOPs。
鉴于ZeRO++的出色扩展性,我们设想ZeRO++将成为训练大型AI模型的下一代ZeRO。
利用ZeRO++进行DeepSpeed-Chat RLHF训练
RLHF训练简介
ChatGPT 类模型由 LLM 提供支持,并使用 RLHF 进行微调(https://openai.com/blog/chatgpt)。 RLHF 由生成(推理)阶段和训练阶段组成。 在生成阶段,演员(actor)模型将部分对话作为输入,并使用一系列前向传递生成响应。 然后在训练阶段,评论(critic)模型根据质量对生成的响应进行排名,为演员模型提供强化信号。 使用这些排名对参与者模型进行微调,使其能够在后续迭代中生成更准确和适当的响应。
RLHF 训练带来了巨大的内存压力,因为它使用了四种模型(演员、参考、评论、奖励)。 常见的解决方案是采用低秩自适应训练 (LoRA) 来解决 RLHF 的内存压力。 LoRA 冻结了预训练模型的权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,显着减少了可训练参数的数量。 LoRA 通过减少内存使用来加速 RLHF,允许更大的批处理(batch)大小,从而大大提高吞吐量。
DeepSpeed-Chat with ZeRO++ 用于 RLHF 训练
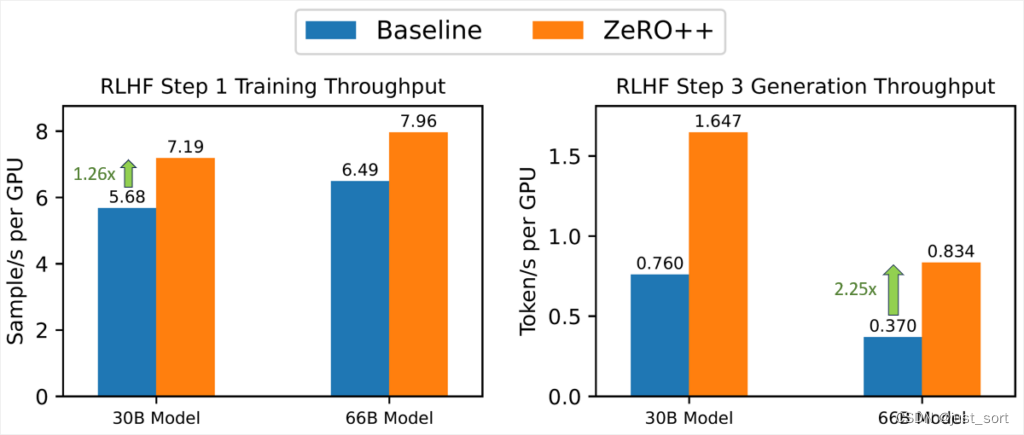
图9:ZeRO++在RLHF训练中的速度提升。左图显示ZeRO++在RLHF步骤1的训练中实现了1.26倍的速度提升。右图显示ZeRO++在RLHF步骤3的令牌生成中实现了最高2.25倍的速度提升。
ZeRO++在RLHF + LoRA的场景下有着独特的应用,因为大多数模型权重都被冻结了。 这意味着 ZeRO++ 可以将这些冻结的权重量化保存到INT4/8 中,而不是将它们存储在 fp16 中并在每次通信操作之前对其进行量化。 通信后的反量化仍然是为了让权重为计算做好准备,但反量化后的权重在计算后被简单地丢弃。
以这种方式使用 ZeRO++ 进行 RLHF 训练可以减少内存使用和通信量。 这意味着通过减少通信以及由于减少内存使用而启用更大的批处理大小来提高训练吞吐量。 在生成阶段,ZeRO++ 使用 hpZ 将所有权重通信保持在每个节点内,以利用更高的节点内通信带宽,减少通信量,进一步提高生成吞吐量。
ZeRO++ 已集成到 DeepSpeed-Chat 中,以支持 ChatGPT 类模型的 RLHF 训练。 在图 9 中,我们比较了不同大小的 actor 模型的 RLHF 生成吞吐量。测试配置为 32个V100 GPU ,actor 模型大小为30B 和 66B以测试 ZeRO 和 ZeRO++性能。 结果表明,ZeRO++ 的 RLHF 生成吞吐量比 ZeRO 高出 2.25 倍。 我们还展示了在 16 个 V100 GPU 上训练阶段的加速,其中 ZeRO++ 实现了比 ZeRO 高 1.26 倍的吞吐量,这是由于 ZeRO++ 支持的更低通信量和更大批量大小。
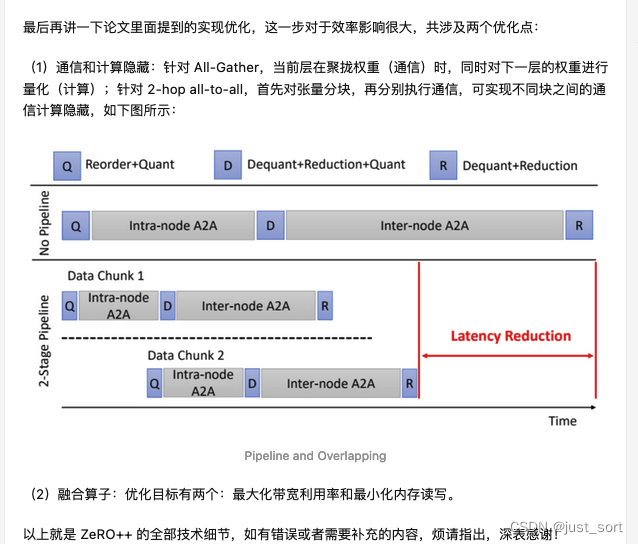
0x2. 代码解读
DeepSpeed 在 https://github.com/microsoft/DeepSpeed/pull/3784 引入了 zero++的支持,下面对代码做一个解读。
csrc kernel实现
首先在 csrc/includes/quantization.h 定义了launch_swizzled_quant和launch_dequant_reduce函数:
// 在GPU上进行并行化量化操作
void launch_swizzled_quant(int8_t* q_data,// 量化后的数据的存储位置。
float* q_scales, //量化比例因子的存储位置。
const __half* input_data, //输入数据,这些数据将被量化。
int num_bits, //量化的位数。
quantize::Type q_type, //量化的类型,可能包含不同的量化策略。
int groups, //数据将被分割成的组数。
int elems_per_group, //每组元素的数量。
int pipelining, //是否使用流水线并行化。
int nodes, //计算节点数量。
int devices_per_node, //每个节点上设备的数量。
cudaStream_t stream); //CUDA流,用于在GPU上异步并行执行操作。
// GPU上进行并行化的反量化并执行reduce操作
void launch_dequant_reduce(int8_t* reduced_data, //reduce后的数据的存储位置。
float* reduced_scales, //reduce后的量化比例因子的存储位置。
const int8_t* input_data, // 输入的量化数据。
const float* input_scales, // 输入的量化比例因子。
int num_gpus, // 用于计算的GPU数量。
int num_bits, // 量化的位数。
quantize::Type quant_type, // 量化的类型,可能包含不同的量化策略。
int out_groups, // 输出数据将被分割成的组数。
int elems_per_out_group, // 每组输出元素的数量。
int elems_per_in_tensor, // 每个输入张量的元素数量。
int groups_per_in_tensor, // 每个输入张量被分割成的组数。
int elems_per_in_group, // 每个输入组的元素数量。
cudaStream_t stream);//CUDA流,用于在GPU上异步并行执行操作。
接着我们解读一下csrc/quantization/pt_binding.cpp这个文件的实现:
// 这个函数用于将输入数据集进行分组并进行量化处理。
std::vector<at::Tensor> ds_swizzle_quant(at::Tensor& input_vals,
int groups,
int num_bits,
quantize::Type quant_type,
int pipeline_size,
int nodes,
int devices_per_node)
{
// 定义了一个at::TensorOptions对象,它描述了接下来要创建的张量的属性。
// 这个张量的数据类型是float,布局是strided,设备是CUDA设备,且不需要计算梯度。
auto scales_options = at::TensorOptions()
.dtype(at::kFloat)
.layout(at::kStrided)
.device(at::kCUDA)
.requires_grad(false);
// 通过检查量化类型是否需要偏移,来确定比例因子的数量。
const int scales_elems = (quantize::requires_offset(quant_type)) ? 2 : 1;
// 创建一个未初始化的张量,其大小为{groups, scales_elems},并使用之前定义的张量属性。
auto scales = torch::empty({groups, scales_elems}, scales_options);
// 同样地,创建了一个未初始化的张量用于存储输出结果。其数据类型是char,
// 布局是strided,设备是CUDA设备,且不需要计算梯度。
auto output_options = at::TensorOptions()
.dtype(at::kChar)
.layout(at::kStrided)
.device(at::kCUDA)
.requires_grad(false);
// 计算量化因子,它由8位除以量化位数得出。
const int quantization_scalar = 8 / num_bits;
// 计算量化后的值的数量,通过输入值的元素总数除以量化因子得出。
const int compressed_vals = at::numel(input_vals) / quantization_scalar;
// 创建一个未初始化的张量,用于存储量化后的值。
auto output = torch::empty({compressed_vals}, output_options);
// 计算每组的元素数量,通过输入值的元素总数除以组数得出。
const int elems_per_group = at::numel(input_vals) / groups;
// 调用之前定义的函数launch_swizzled_quant,对输入的张量进行量化操作。
// 参数包括输入的数据、量化位数、量化类型、组数、每组的元素数量等等。
launch_swizzled_quant((int8_t*)output.data_ptr(),
(float*)scales.data_ptr(),
(__half*)input_vals.data_ptr(),
num_bits,
quant_type,
groups,
elems_per_group,
pipeline_size,
nodes,
devices_per_node,
at::cuda::getCurrentCUDAStream());
// 返回一个包含两个元素的向量,第一个元素是量化后的值,第二个元素是量化的缩放因子。
return {output, scales};
}
// 这是一个将输入的量化数据进行降维和反量化的操作
std::vector<at::Tensor> quantized_reduction(at::Tensor& input_vals,
at::Tensor& input_scales,
int in_groups,
int out_groups,
int num_bits,
quantize::Type quant_type)
{
// 定义一个TensorOptions对象scales_options,表示接下来要创建的张量的属性,
// 这个张量的数据类型是float,布局是strided,设备是CUDA设备,并且不需要计算梯度。
auto scales_options = at::TensorOptions()
.dtype(at::kFloat)
.layout(at::kStrided)
.device(at::kCUDA)
.requires_grad(false);
// 根据量化类型是否需要偏移量,确定量化缩放因子的数量。
const int scales_elems = (quantize::requires_offset(quant_type)) ? 2 : 1;
// 使用scales_options定义一个空的张量scales,大小为{out_groups, scales_elems},用来存储量化缩放因子。
auto scales = torch::empty({out_groups, scales_elems}, scales_options);
// 定义一个新的TensorOptions对象output_options,表示接下来要创建的输出张量的属性,
// 这个张量的数据类型是char,布局是strided,设备是CUDA设备,并且不需要计算梯度。
auto output_options = at::TensorOptions()
.dtype(at::kChar)
.layout(at::kStrided)
.device(at::kCUDA)
.requires_grad(false);
// 将input_vals的大小转化为一个std::vector<long int>对象。
std::vector<long int> sz(input_vals.sizes().begin(), input_vals.sizes().end());
// 这里假设每个节点上有16个GPU。这个值可能会根据实际的机器配置有所不同。
const int gpu_per_node = 16; // depend on machine in_groups/out_groups;
// 修改最后一个维度的大小,使其等于原来的大小除以节点上的GPU数量。这可能是为了将数据在节点的各个GPU之间进行分割。
sz[sz.size() - 1] = sz.back() / gpu_per_node; // num of GPU per nodes
// 计算每个GPU处理的输入元素数量。
const int elems_per_in_tensor = at::numel(input_vals) / gpu_per_node;
// 创建一个空的张量output,其大小为sz,用于存储输出结果。
auto output = torch::empty(sz, output_options);
// 计算每个输入组和每个输出组的元素数量。
const int elems_per_in_group = elems_per_in_tensor / (in_groups / gpu_per_node);
const int elems_per_out_group = elems_per_in_tensor / out_groups;
// 调用之前定义的launch_dequant_reduce函数,对输入的张量进行降维和反量化操作。
// 参数包括输出张量、输入张量、量化比例、GPU数量、量化位数、量化类型、输出组数、
// 每个输出组的元素数量、每个输入张量的元素数量、每个GPU处理的输入组数、每个输入组的元素数量等。
launch_dequant_reduce((int8_t*)output.data_ptr(),
(float*)scales.data_ptr(),
(const int8_t*)input_vals.data_ptr(),
(const float*)input_scales.data_ptr(),
gpu_per_node,
num_bits,
quant_type,
out_groups,
elems_per_out_group,
elems_per_in_tensor,
in_groups / gpu_per_node,
elems_per_in_group,
at::cuda::getCurrentCUDAStream());
// 返回一个包含两个元素的向量,第一个元素是输出结果,第二个元素是量化缩放因子。
return {output, scales};
}
接下来对csrc/quantization/swizzled_quantize.cu进行解析:
// Copyright (c) Microsoft Corporation.
// SPDX-License-Identifier: Apache-2.0
// DeepSpeed Team
#include "memory_access_utils.h"
#include "quantization_utils.h"
#include "reduction_utils.h"
using rop = reduce::ROpType;
namespace swiz_quant {
// swiz_quant命名空间内定义了一些常量,包括最大线程数、最小线程数、
// 步长粒度以及每步处理的元素数量。这些值都是在量化过程中使用的。
constexpr int max_threads = 512;
constexpr int min_threads = 32;
constexpr int step_granularity = 2;
constexpr int h_per_step = step_granularity * quantize::h_per_load;
} // namespace swiz_quant
// swizzled_quant_kernel是一个模板函数,它的模板参数包括:量化位数numBits、
// 总块数totalChunks、线程数threads、以及量化类型quantType。
//它接受的参数包括量化后的数据、量化比例尺、未压缩的数据、每个分组的元素数、节点数、每个节点的设备数。
template <int numBits, int totalChunks, int threads, quantize::Type quantType>
__global__ void swizzled_quant_kernel(int8_t* quantized_data,
float* quantized_scales,
const __half* uncompressed_data,
int elems_per_group,
int nodes,
int devices_per_node)
{
// 获取当前的线程块对象(thread block)。hw_warp_size是一个常量32
cg::thread_block tb = cg::this_thread_block();
// 从线程块中划分一个大小为硬件warp大小的分区(warp)。
cg::thread_block_tile<hw_warp_size> warp = cg::tiled_partition<hw_warp_size>(tb);
// 计算线程块在网格中的全局排序(rank)。这里网格是3维的,每个维度可能包含多个线程块。
const int block_rank = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
// 根据线程块的全局排序和每组的元素数量来计算偏移量。
const int block_offset = block_rank * elems_per_group;
// quantize::h_per_load 的定义在 `DeepSpeed/csrc/includes/quantization_utils.h` 中的:
// constexpr int granularity = 16;
// constexpr int h_per_load = granularity / sizeof(__half);
// 计算在一个线程块中的线程的偏移量。这里假设一个线程将加载quantize::h_per_load个元素。
const int elem_offset = tb.thread_index().x * quantize::h_per_load;
// 计算基础偏移量,即线程块偏移量和线程偏移量的和。
const int base_offset = block_offset + elem_offset;
// 计算步长。步长是一个线程块的大小乘以每个线程加载的元素数量。
const int stride = tb.size() * quantize::h_per_load;
// 根据基础偏移量获取未压缩数据的指针。
const __half* input_base = uncompressed_data + base_offset;
// 在本地声明一个缓冲区,用来存储加载的数据。这里__half2是CUDA中用于表示半精度浮点数的类型。
__half2 local_buffer[totalChunks * quantize::h2_per_load];
quantize::GroupStats<quantType> stats; // 声明一个GroupStats对象,用来存储统计信息。
#pragma unroll // 是一个编译指令,它告诉编译器展开接下来的循环,可以提高代码的执行效率。
// 然后是一个循环,读取全局内存的数据并存储到本地缓冲区,然后更新统计信息。
for (int i = 0; i < totalChunks; i++) {
__half2* iteration_buffer = local_buffer + i * quantize::h2_per_load;
mem_access::load_global<quantize::granularity>(
iteration_buffer, input_base + i * stride, elem_offset + i * stride < elems_per_group);
#pragma unroll
for (int j = 0; j < quantize::h2_per_load; j++) { stats.update(iteration_buffer[j]); }
}
// 调用get_params函数从统计对象(stats)中获取量化参数。这些参数包括每个矢量的缩放因子和零点。
// 此行中numBits和threads是模板参数,分别表示量化的位数和线程数量。同时,tb和warp分别表示线程块和线程束的对象。
auto params = stats.template get_params<numBits, threads>(tb, warp);
// 设置partition_id为z方向的block索引。
const int partition_id = blockIdx.z;
// 计算每个节点的设备偏移,即当前分区ID除以每个节点的设备数。
const int partition_offset = partition_id / devices_per_node;
// 计算分区基数,即当前分区ID除以每个节点的设备数的余数乘以节点数。
const int partition_base = (partition_id % devices_per_node) * nodes;
// 计算流水线偏移,即y方向的block索引乘以设备总数。
const int pipelining_offset = blockIdx.y * (devices_per_node * nodes);
// 计算输出分区,即流水线偏移加上分区基数和设备偏移。
const int output_partition = (pipelining_offset + partition_base + partition_offset);
// 计算输出标量效应,即每个字节可以包含的元素数量。
constexpr int out_scalar_effect = 8 / numBits;
// 计算输出block的排名,即输出分区乘以x方向的grid大小加上x方向的block索引。
const int out_block_rank = output_partition * gridDim.x + blockIdx.x;
// 计算输出block的偏移,即输出block的排名乘以每个组的元素数除以输出标量效应。
const int out_block_offset = out_block_rank * elems_per_group / out_scalar_effect;
// 计算输出基础偏移,即输出block的偏移加上元素偏移除以输出标量效应。
const int out_base_offset = out_block_offset + elem_offset / out_scalar_effect;
// 计算输出基地址,即量化数据加上输出基础偏移。
int8_t* out_base = quantized_data + out_base_offset;
// 计算输出步长,即步长除以输出标量效应。
const int out_stride = stride / out_scalar_effect;
// 计算每次输出的int8数目,即每次加载的半精度浮点数数量除以输出标量效应。
constexpr int num_int8_out = quantize::h_per_load / out_scalar_effect;
// 如果当前线程是线程块中的第一个线程,那么将参数存储到指定的位置。
if (tb.thread_index().x == 0) { params.store(quantized_scales, out_block_rank); }
#pragma unroll
// 对每个块进行循环。
for (int i = 0; i < totalChunks; i++) {
// 如果当前元素在有效范围内,则执行以下操作:
if (i * stride + elem_offset < elems_per_group) {
// 定义一个本地输出数组,用于临时存储量化的结果。
int8_t local_output[quantize::h_per_load / out_scalar_effect];
// 进行量化操作,结果存储在local_output中。
quantize::_chunk<numBits, quantType>(
local_output, local_buffer + i * quantize::h2_per_load, params);
// 将本地的量化结果存储到全局内存中。
mem_access::store_global<num_int8_out>(out_base + i * out_stride, local_output);
}
}
}
#define LAUNCH_SWIZZLE_QUANT(total_chunks, threads) \
swizzled_quant_kernel<numBits, total_chunks, threads, qType><<<grid, block, 0, stream>>>( \
q_data, q_scales, input_data, elems_per_group, nodes, devices_per_node);
// 这里解释了 "Swizzled quantization"(交错量化)是如何工作的。
// 这种方法主要是为了优化多节点多设备的并行计算中的通信效率。
// 这里给出了一个在两个节点,每个节点上有四个设备的情况下的划分示例。
// 原始的数据划分可能是线性的,比如0-7每个数代表一组数据,且数据在设备上的存储是连续的:
// --- --- --- --- --- --- --- ---
// | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
// --- --- --- --- --- --- --- ---
// 在交错量化中,数据会被重新组织,变成如下形式:
// --- --- --- --- --- --- --- ---
// | 0 | 4 | 1 | 5 | 2 | 6 | 3 | 7 |
// --- --- --- --- --- --- --- ---
// 此处,每个数字代表一组数据,你可以看到原本连续存储的数据被"交错"了。
// 在这个例子中,0和4可能在同一个节点的不同设备上,1和5在另一个节点的不同设备上。
// 通过这种方式,我们可以在进行节点间的通信时,同时从每个节点的多个设备中获取数据,这样可以提高通信效率。
// 还提到了一个"分片"的概念,比如说二分分片。在这种情况下,每个分区的前半部分数据会被连接在一起,
// 这样可以为后续的流水线操作提供更好的支持。
// 这段代码是一个模板函数,实现了"Swizzled quantization"的过程。
// 主要参数包括量化数据q_data,量化比例尺q_scales,输入数据input_data,分组数量groups,
// 每组元素数量elems_per_group,流水线大小pipelining,节点数nodes
// 和每个节点上的设备数devices_per_node。最后一个参数stream是用于CUDA的异步并行执行的流。
template <int numBits, quantize::Type qType>
void launch_swizzled_quant_impl(int8_t* q_data,
float* q_scales,
const __half* input_data,
int groups,
int elems_per_group,
int pipelining,
int nodes,
int devices_per_node,
cudaStream_t stream)
{
// 函数首先计算一步操作中需要的线程数one_step_threads。
// 这是基于elems_per_group和固定步长swiz_quant::h_per_step计算得出的。
// next_pow2函数将输入值向上取到最近的2的幂。这是为了优化线程分配,因为GPU在处理2的幂次数的线程块时,效率最高。
const int one_step_threads =
next_pow2((elems_per_group + swiz_quant::h_per_step - 1) / swiz_quant::h_per_step);
// 之后,它计算最大线程数max_threads,
// 这个值是one_step_threads和预设的最大线程数swiz_quant::max_threads中的较小值。
const int max_threads = (one_step_threads < swiz_quant::max_threads) ? one_step_threads
: swiz_quant::max_threads;
// 然后,它计算实际线程数threads,这个值是max_threads和预设的最小线程数swiz_quant::min_threads中的较大值。
const int threads = (max_threads < swiz_quant::min_threads) ? swiz_quant::min_threads
: max_threads;
// 下一步是设置CUDA的block和grid维度。block的维度是threads,
// grid的维度则是基于分组数量,节点数和设备数计算出的。
// 这里,每个分区的分组数groups_per_partition是总分组数groups除以总设备数
// (节点数nodes乘以每节点设备数devices_per_node)。
// 接着,它断言分区中的分组数可以被流水线大小pipelining整除,得到连续分组数contiguous_groups。
// 最后,设定grid的维度,每个维度代表一个不同的并行度。
dim3 block(threads);
const int groups_per_partition = groups / (nodes * devices_per_node);
assert(groups_per_partition % pipelining == 0);
const int contiguous_groups = groups_per_partition / pipelining;
const int partitions = nodes * devices_per_node;
dim3 grid(contiguous_groups, pipelining, partitions);
// elems_per_step和total_unroll是关于处理步长和展开程度的参数,它们影响kernel的并行性和计算复杂度。
const int elems_per_step = threads * swiz_quant::h_per_step;
const int external_unroll = ((elems_per_group + elems_per_step - 1) / elems_per_step);
const int total_unroll = external_unroll * swiz_quant::step_granularity;
// 接下来的一系列判断和宏调用LAUNCH_SWIZZLE_QUANT,就是基于不同的线程数和展开程度,
// 选择并启动相应的量化kernel。不同的量化kernel在执行效率和处理数据规模方面有各自的优化。
assert(total_unroll % 2 == 0);
if (threads == 32) {
LAUNCH_SWIZZLE_QUANT(2, 32);
} else if (threads == 64) {
LAUNCH_SWIZZLE_QUANT(2, 64);
} else if (threads == 128) {
LAUNCH_SWIZZLE_QUANT(2, 128);
} else if (threads == 256) {
LAUNCH_SWIZZLE_QUANT(2, 256);
} else if (threads == 512) {
if (total_unroll == 2) {
LAUNCH_SWIZZLE_QUANT(2, 512);
} else if (total_unroll == 4) {
LAUNCH_SWIZZLE_QUANT(4, 512);
} else if (total_unroll == 6) {
LAUNCH_SWIZZLE_QUANT(6, 512);
} else if (total_unroll == 8) {
LAUNCH_SWIZZLE_QUANT(8, 512);
} else if (total_unroll == 10) {
LAUNCH_SWIZZLE_QUANT(10, 512);
}
}
}
// DISPATCH_SWIZZLE_QUANT宏接收两个参数num_bits和qtype,并调用了一个模板函数launch_swizzled_quant_impl,
// 这个模板函数的模板参数为num_bits和qtype,函数参数为一系列传入的值。
#define DISPATCH_SWIZZLE_QUANT(num_bits, qtype) \
launch_swizzled_quant_impl<num_bits, qtype>(q_data, \
q_scales, \
input_data, \
groups, \
elems_per_group, \
pipelining, \
nodes, \
devices_per_node, \
stream);
// 这个函数主要是用来根据量化的位数num_bits和量化类型q_type来调用相应的模板函数。
// 函数的参数列表包含了数据指针q_data, q_scales和input_data,这些都是在GPU内存上的数据。
// 其它的参数如groups, elems_per_group, pipelining, nodes,
// devices_per_node, stream都是用来控制量化操作的参数。
void launch_swizzled_quant(int8_t* q_data,
float* q_scales,
const __half* input_data,
int num_bits,
quantize::Type q_type,
int groups,
int elems_per_group,
int pipelining,
int nodes,
int devices_per_node,
cudaStream_t stream)
{
// 如果num_bits等于4,那么就会进入第一个if分支;如果num_bits等于8,就会进入第二个if分支。
// 在每个if分支中,都会再根据q_type的值来调用不同的模板函数。
if (num_bits == 4) {
// 如果q_type等于quantize::Type::Asymmetric,那么就会调用launch_swizzled_quant_impl
// 模板函数并将模板参数设置为4和quantize::Type::Asymmetric
if (q_type == quantize::Type::Asymmetric) {
DISPATCH_SWIZZLE_QUANT(4, quantize::Type::Asymmetric);
}
// 如果q_type等于quantize::Type::Symmetric,那么就会调用launch_swizzled_quant_impl
// 模板函数并将模板参数设置为4和quantize::Type::Symmetric。
else if (q_type == quantize::Type::Symmetric) {
DISPATCH_SWIZZLE_QUANT(4, quantize::Type::Symmetric);
}
} else if (num_bits == 8) {
if (q_type == quantize::Type::Asymmetric) {
DISPATCH_SWIZZLE_QUANT(8, quantize::Type::Asymmetric);
} else if (q_type == quantize::Type::Symmetric) {
DISPATCH_SWIZZLE_QUANT(8, quantize::Type::Symmetric);
}
}
}
然后对 csrc/quantization/quant_reduce.cu 进行解析:
// Copyright (c) Microsoft Corporation.
// SPDX-License-Identifier: Apache-2.0
// DeepSpeed Team
#include <cstdio>
#include "dequantization_utils.h"
#include "ds_kernel_utils.h"
#include "memory_access_utils.h"
#include "quantization_utils.h"
#include "reduction_utils.h"
using rop = reduce::ROpType;
/*
TODO(cmikeh2): Add implementation that better handles larger nodes. It would like make sense
to leverage some parallel reductions here to improve performance.
*/
// 这段 CUDA kernel 是用于将一些输入数据进行反量化和归约操作的。它的功能是将输入的量化数据(int8类型)
// 转换回浮点数据(__half2类型,也就是半精度浮点数),然后进行一些归约操作,并再次量化数据并输出。
// 这是一个模板函数,可以通过模板参数调整数据位宽(numBits)、张量数量(numTensors)
// 、需要处理的数据块的数量(totalChunks)、以及量化类型(quantType):
template <int numBits, int numTensors, int totalChunks, quantize::Type quantType>
// 该 CUDA kernel 配置了一些输入和输出参数,包括输入和输出的数据和缩放因子、每个输出组的元素数量、
// 每个输入张量的元素数量、每个输入张量的组数量、每个输入组的元素数量,以及张量的总数:
__global__ void __launch_bounds__(1024) dequant_reduce(int8_t* reduced_data,
float* reduced_scales,
const int8_t* input_data,
const float* input_scales,
int elems_per_out_group,
int elems_per_in_tensor,
int groups_per_in_tensor,
int elems_per_in_group,
int num_tensors)
{
// 这段代码首先获取了当前的线程块(tb)和线程块内的一个 warp(warp):
cg::thread_block tb = cg::this_thread_block();
cg::thread_block_tile<hw_warp_size> warp = cg::tiled_partition<hw_warp_size>(tb);
// NOTE(cmikeh2): This probably could be hardcoded to a larger number,
// but that means even stronger restrictions on the number of elements per group
// A performance analysis here might be beneficial
// 根据模板参数 numBits,这段代码确定了每次内存加载的元素数量(elems_per_load)和用于存储的值的数量(storage_values):
constexpr int mem_granularity = (numBits == 8) ? 8 : 4;
constexpr int elems_per_load = mem_granularity / sizeof(int8_t); // div by 1
constexpr int storage_values = 16 / sizeof(__half2);
// 然后,这段代码计算了每个线程块和每个线程的偏移量,以及每次迭代的步长
const int block_offset = tb.group_index().x * elems_per_out_group;
const int elem_offset = tb.thread_index().x * elems_per_load;
const int base_offset = block_offset + elem_offset;
const int stride = tb.group_dim().x * elems_per_load;
// 接下来,这段代码为每个线程分配了一个本地缓冲区,并初始化了一个统计对象:
__half2 local_buffer[totalChunks * storage_values];
quantize::GroupStats<quantType> stats;
// 这段代码是在一个更大的循环中,其中 i 是从 0 到 totalChunks 的索引。
// 这个循环处理的每一个“块”都包含了 storage_values 的元素。
// #pragma unroll 是一个编译器指令,意思是编译器应该将循环展开,以减少循环的开销。
#pragma unroll
for (int i = 0; i < totalChunks; i++) {
// 在每个块中,首先获取一个指向当前块在 local_buffer 中开始位置的指针 iteration_buffer
__half2* iteration_buffer = local_buffer + i * storage_values;
// 然后,初始化 iteration_buffer 的每一个元素。reduce::init<rop::Add, __half2>()
// 是一个模板函数,根据给定的类型和运算,返回相应的初始值。这里,初始值是加法操作的中性元素,对于加法来说,就是0。
#pragma unroll
for (int j = 0; j < storage_values; j++) {
iteration_buffer[j] = reduce::init<rop::Add, __half2>();
}
// 接着,计算了一些用于后续操作的参数:
const int iter_offset = i * stride + base_offset;
const int iter_scale_idx = iter_offset / elems_per_in_group;
bool do_loads = i * stride + elem_offset < elems_per_out_group;
// 根据 numTensors 是否大于 0,执行不同的操作。如果 numTensors 大于 0,那么对每个张量执行以下操作:
if (numTensors > 0) {
#pragma unroll
for (int j = 0; j < numTensors; j++) {
// 如果 do_loads 为真,从全局内存加载数据到 load_buffer;
if (do_loads) {
int8_t load_buffer[elems_per_load];
mem_access::load_global<mem_granularity>(
load_buffer, input_data + j * elems_per_in_tensor + iter_offset);
// 创建一个参数对象 params,用于后续的反量化操作;
quantize::Params<quantType, numBits> params(
input_scales + j * groups_per_in_tensor, iter_scale_idx);
__half2 dequant_buffer[storage_values];
// 将 load_buffer 中的数据反量化,并将结果存储到 dequant_buffer;
dequantize::chunk<numBits, quantType>(dequant_buffer, load_buffer, params);
#pragma unroll
// 将 dequant_buffer 中的每个元素添加到 iteration_buffer 对应的元素。
// 这里的 #pragma unroll 指令又告诉编译器将内部的循环展开。
for (int k = 0; k < storage_values; k++) {
iteration_buffer[k] =
reduce::element<rop::Add>(iteration_buffer[k], dequant_buffer[k]);
}
}
}
} else {
// 如果 numTensors 不大于 0,那么对 num_tensors 个张量执行类似的操作。这里的 #pragma unroll 4 指令告诉编译器将内部的循环展开4次。
#pragma unroll 4
for (int j = 0; j < num_tensors; j++) {
if (do_loads) {
int8_t load_buffer[elems_per_load];
mem_access::load_global<mem_granularity>(
load_buffer, input_data + j * elems_per_in_tensor + iter_offset);
quantize::Params<quantType, numBits> params(
input_scales + j * groups_per_in_tensor, iter_scale_idx);
__half2 dequant_buffer[storage_values];
dequantize::chunk<numBits, quantType>(dequant_buffer, load_buffer, params);
#pragma unroll
for (int k = 0; k < storage_values; k++) {
iteration_buffer[k] =
reduce::element<rop::Add>(iteration_buffer[k], dequant_buffer[k]);
}
}
}
}
// 最后,将 iteration_buffer 中的每个元素更新到 stats 对象。
#pragma unroll
for (int j = 0; j < storage_values; j++) { stats.update(iteration_buffer[j]); }
}
// stats 是一个 quantize::GroupStats<quantType> 类型的对象,其中 quantType 是模板参数。
// get_params 是这个类的成员函数,接收两个参数,分别是当前线程块 tb 和 warp warp,
// 并且有两个模板参数 numBits 和 threads_per_group(1024)。
// 这个函数的返回值是一种参数类型的对象,具体的类型取决于 quantize::GroupStats<quantType> 的定义。
auto params = stats.template get_params<numBits, 1024>(tb, warp);
// 然后,如果当前线程是线程块的第一个线程,那么将参数存储到 reduced_scales 中,索引是线程块的索引:
if (tb.thread_index().x == 0) { params.store(reduced_scales, tb.group_index().x); }
// 接下来,这段代码再次进行多次循环,每次处理一个数据块。在每个数据块内,如果条件满足,
// 那么将本地缓冲区的数据进行量化操作,并将结果存储到输出数据:
#pragma unroll
for (int i = 0; i < totalChunks; i++) {
const int iter_offset = i * stride + base_offset;
if (i * stride + elem_offset < elems_per_out_group) {
int8_t local_output[elems_per_load];
// 这里的 quantize::_chunk 是一个模板函数,接收三个参数,分别是存储位置 local_output、
// 输入数据 local_buffer + i * storage_values 和参数 params,
// 并且有两个模板参数 numBits 和 quantType。这个函数的功能是将输入数据进行量化操作,并将结果存储到
// local_output。之后,mem_access::store_global 将 local_output 中的数据存储到 reduced_data + iter_offset。
quantize::_chunk<numBits, quantType>(
local_output, local_buffer + i * storage_values, params);
mem_access::store_global<mem_granularity>(reduced_data + iter_offset, local_output);
}
}
}
// 这是一个C++模板函数,名称为pow2_round,它接受一个模板参数Power,并有一个整型参数raw_value。
// 这个函数的功能是将输入的raw_value向上取到最接近的2的Power次方的倍数。
// 如果Power为2(即,我们希望结果是4的倍数),且raw_value为6,那么这个函数会返回8,因为8是最接近6的4的倍数。
template <int Power>
// int32_t pow2_round(int32_t raw_value):这是函数的定义,函数名为pow2_round,
// 返回类型为int32_t,并接受一个类型为int32_t的参数raw_value。
int32_t pow2_round(int32_t raw_value)
{
// 首先,raw_value - 1是将raw_value减1,然后>> Power是将结果右移Power位,
// 这相当于除以2^Power。之后,+ 1是将结果加1,这实现了向上取整。
// 最后,<< Power是将结果左移Power位,这相当于乘以2^Power,这样就得到了最接近的2的Power次方的倍数。
return (((raw_value - 1) >> Power) + 1) << Power;
}
#define LAUNCH_DEQUANT_REDUCE(num_chunks) \
dequant_reduce<numBits, numTensors, num_chunks, quantType> \
<<<grid, block, 0, stream>>>(reduced_data, \
reduced_scales, \
input_data, \
input_scales, \
elems_per_out_group, \
elems_per_in_tensor, \
groups_per_in_tensor, \
elems_per_in_group, \
num_tensors);
// 这个C++模板函数 launch_dequant_reduce_impl 是用于启动反量化和数据规约的CUDA kernel。
// 该函数包含三个模板参数,numBits,numTensors和quantType,这些参数在编译时必须被确定。
template <int numBits, int numTensors, quantize::Type quantType>
void launch_dequant_reduce_impl(int8_t* reduced_data,
float* reduced_scales,
const int8_t* input_data,
const float* input_scales,
int out_groups,
int elems_per_out_group,
int elems_per_in_tensor,
int groups_per_in_tensor,
int elems_per_in_group,
int num_tensors,
cudaStream_t stream)
{
// This is a coincidence. This is derived by 8 halves per 16 bytes with 2-way packing for int4
// 定义了每个线程需要处理的元素数量,这个值与numBits(模板参数)相同。
constexpr int elems_per_thread = numBits;
// 计算处理一组输出元素需要的线程数,这个值取决于每个线程处理的元素数量和每个输出组的元素数量。
// next_pow2函数计算最接近且大于等于其参数的2的幂。
const int one_step_threads =
next_pow2((elems_per_out_group + elems_per_thread - 1) / (elems_per_thread));
// TODO(cmikeh2): Tune this
// 确定线程数,如果一步所需的线程数小于1024,则使用这个值,否则使用1024。
const int threads = (one_step_threads < 1024) ? one_step_threads : 1024;
// 设置CUDA网格和块的维度。每个块中有threads个线程,而网格中有out_groups个块。
dim3 block(threads);
dim3 grid(out_groups);
// 计算每步要处理的元素数量,这取决于线程数和每个线程处理的元素数。
const int elems_per_step = threads * elems_per_thread;
// 计算unroll需要多少步,取决于每个输出组中的元素数量和每一步要处理的元素数量
const int unroll_raw = (elems_per_out_group + elems_per_step - 1) / elems_per_step;
// 如果原始值大于等于4,那么就用2的幂进行近似,否则保持不变。
const int unroll = (unroll_raw >= 4) ? pow2_round<1>(unroll_raw) : unroll_raw;
// 根据优化后的unroll,调用不同的反量化和数据规约kernel。
if (unroll == 1) {
// 0-4096 elems
LAUNCH_DEQUANT_REDUCE(1);
} else if (unroll == 2) {
// 4097-8192 etc...
LAUNCH_DEQUANT_REDUCE(2);
} else if (unroll == 3) {
LAUNCH_DEQUANT_REDUCE(3);
} else if (unroll == 4) {
LAUNCH_DEQUANT_REDUCE(4);
} else if (unroll == 6) {
LAUNCH_DEQUANT_REDUCE(6);
} else if (unroll == 8) {
LAUNCH_DEQUANT_REDUCE(8);
} else if (unroll == 10) {
LAUNCH_DEQUANT_REDUCE(10);
} else if (unroll == 12) {
// 48k limit
LAUNCH_DEQUANT_REDUCE(12);
} else {
assert(false);
}
}
// 这是一个C++预处理器宏定义。预处理器宏是在编译时,即在源代码被转换为机器语言之前进行替换的一种机制。
// 在这个宏定义中,LAUNCH_DEQUANT_REDUCE_IMPL是宏名称,而NUM_BITS,NUM_GPUS和QUANT_TYPE是宏参数。
// 宏定义的主体是一个函数调用 launch_dequant_reduce_impl<NUM_BITS, NUM_GPUS, QUANT_TYPE>。
// 该函数是模板函数,NUM_BITS,NUM_GPUS和QUANT_TYPE是模板参数。
// 当这个宏在源代码中被使用时,例如LAUNCH_DEQUANT_REDUCE_IMPL(4, 8, quantize::Type::Symmetric),
// 预处理器会将这个宏调用替换为launch_dequant_reduce_impl<4, 8, quantize::Type::Symmetric>
// 的函数调用,并将后面的参数列表插入到这个函数调用中。
#define LAUNCH_DEQUANT_REDUCE_IMPL(NUM_BITS, NUM_GPUS, QUANT_TYPE) \
launch_dequant_reduce_impl<NUM_BITS, NUM_GPUS, QUANT_TYPE>(reduced_data, \
reduced_scales, \
input_data, \
input_scales, \
out_groups, \
elems_per_out_group, \
elems_per_in_tensor, \
groups_per_in_tensor, \
elems_per_in_group, \
num_gpus, \
stream);
// 这个函数的作用是处理量化后的数据,将它们"反量化"并进行规约。
void launch_dequant_reduce(int8_t* reduced_data, //这是一个指针,指向存储反量化和reduce操作后的结果的内存位置。
float* reduced_scales, //这是一个指针,指向存储缩放因子的内存位置,这些缩放因子应用于反量化操作。
const int8_t* input_data, // 这是一个指向输入数据(已经量化)的常量指针。
const float* input_scales, // 这是一个指向输入数据量化时使用的缩放因子的常量指针。
int num_gpus, // 指示执行此操作的GPU数量。
int num_bits, // 指示用于量化操作的位数(4或8位)。
quantize::Type quant_type, // 指定了量化操作的类型(对称或非对称)。
int out_groups, // 这些是与输入数据和输出数据的维度或组相关的参数。
int elems_per_out_group,
int elems_per_in_tensor,
int groups_per_in_tensor,
int elems_per_in_group,
cudaStream_t stream)
{
// 根据量化类型(对称或非对称)和位数(4或8),对应的反量化和reduce的实现(LAUNCH_DEQUANT_REDUCE_IMPL)被调用。
// 这个实现可能会根据不同的配置优化计算过程,例如对于8个GPU和16个GPU的情况。
if (quant_type == quantize::Type::Symmetric) {
if (num_bits == 4) {
if (num_gpus == 8) {
LAUNCH_DEQUANT_REDUCE_IMPL(4, 8, quantize::Type::Symmetric);
} else if (num_gpus == 16) {
LAUNCH_DEQUANT_REDUCE_IMPL(4, 16, quantize::Type::Symmetric);
} else {
LAUNCH_DEQUANT_REDUCE_IMPL(4, -1, quantize::Type::Symmetric);
}
} else if (num_bits == 8) {
if (num_gpus == 8) {
LAUNCH_DEQUANT_REDUCE_IMPL(8, 8, quantize::Type::Symmetric);
} else if (num_gpus == 16) {
LAUNCH_DEQUANT_REDUCE_IMPL(8, 16, quantize::Type::Symmetric);
} else {
LAUNCH_DEQUANT_REDUCE_IMPL(8, -1, quantize::Type::Symmetric);
}
}
} else if (quant_type == quantize::Type::Asymmetric) {
if (num_bits == 4) {
if (num_gpus == 8) {
LAUNCH_DEQUANT_REDUCE_IMPL(4, 8, quantize::Type::Asymmetric);
} else if (num_gpus == 16) {
LAUNCH_DEQUANT_REDUCE_IMPL(4, 16, quantize::Type::Asymmetric);
} else {
LAUNCH_DEQUANT_REDUCE_IMPL(4, -1, quantize::Type::Asymmetric);
}
} else if (num_bits == 8) {
if (num_gpus == 8) {
LAUNCH_DEQUANT_REDUCE_IMPL(8, 8, quantize::Type::Asymmetric);
} else if (num_gpus == 16) {
LAUNCH_DEQUANT_REDUCE_IMPL(8, 16, quantize::Type::Asymmetric);
} else {
LAUNCH_DEQUANT_REDUCE_IMPL(8, -1, quantize::Type::Asymmetric);
}
}
}
}
qwZ,hpZ,qgZ 调用链解析
上面2个cuda kernel在all_to_all_quant_reduce这个函数中被调用,以实现qgZ功能。函数解析如下:
# 这行代码从PyTorch的torch.distributed模块中引入了ProcessGroup和all_to_all_single。
# ProcessGroup是PyTorch分布式计算的一个基础抽象,表示一个可以进行集合操作(如集合同步、集合计算等)的进程组。
# all_to_all_single函数用于在多个进程之间执行“all-to-all”操作,即每个进程可以发送和接收来自所有其他进程的不同数据。
from torch.distributed import ProcessGroup, all_to_all_single
# get_accelerator函数的功能是获取当前DeepSpeed运行的硬件加速器(通常是GPU)。
from deepspeed.accelerator import get_accelerator
from deepspeed.ops import op_builder
# 这行代码定义了一个名为quantizer_module的变量,并将其初始化为None
quantizer_module = None
# 这是一个通过量化操作来减少网络通信量的函数,主要用于分布式训练环境中。
# 函数的名字all_to_all_quant_reduce是指所有节点之间进行量化的通信和信息聚合。
# 函数的输入参数是一个tensor列表,每个tensor表示不同节点上的数据,还有一个groups字典,表示不同的通信组。
@instrument_w_nvtx
@torch.no_grad()
def `(tensors: List[Tensor], groups: {}) -> List[Tensor]:
# quantizer_module是一个全局的量化模块对象,主要用于执行量化和反量化的操作。
global quantizer_module
# 如果量化模块未初始化,则使用QuantizerBuilder对象加载一个量化模块。
if quantizer_module is None:
quantizer_module = op_builder.QuantizerBuilder().load()
# 获取当前节点(服务器)的设备数量。
local_world_size = get_accelerator().device_count()
# 获取全局的设备数量,这个数量是所有节点的设备数量之和。
global_world_size = dist.get_world_size()
# 计算节点数量,即全局设备数量除以每个节点的设备数量。
num_nodes = global_world_size // local_world_size
# 获取当前设备在全局设备中的排名。
this_rank = dist.get_rank()
# 计算节点内部的索引,即当前设备在本地节点中的排名。
intra_idx = int(this_rank / local_world_size)
# 计算节点间的索引,即当前节点在所有节点中的排名。
inter_idx = this_rank % local_world_size
# 初始化输出tensor列表,列表的长度等于输入tensor列表的长度,初始值设为None。
output_lst: List[Tensor] = [None] * len(tensors)
# 对于输入的每个tensor,进行以下操作:
for idx, tensor in enumerate(tensors):
# 如果tensor的维度是1,进行以下操作:
if tensor.dim() == 1:
# 设置量化组的大小为全局设备数量。
intra_quant_group = global_world_size
# 执行reduce和scatter操作,并将结果存储在输出列表对应的位置上。
output_lst[idx] = reduce_scatter_coalesced([tensor])[0]
continue
# 如果tensor的维度不是1,进行以下操作:
else:
# 设置量化组的大小为tensor的第0维,第1维和全局设备数量中的最大值。
intra_quant_group = max(tensor.shape[0], tensor.shape[1], global_world_size)
# 计算节点间的量化组的大小。
inter_quant_group = intra_quant_group // local_world_size
# 对tensor执行量化操作,得到量化的结果和比例因子。
intra_quant_int4, intra_q_scales = quantizer_module.swizzle_quant(tensor, intra_quant_group, 4,
quantizer_module.Symmetric, 1, num_nodes,
local_world_size)
# 创建两个与量化结果和比例因子形状相同的tensor,用于存储后续操作的结果。
local_output = torch.empty_like(intra_quant_int4)
scale_output = torch.empty_like(intra_q_scales)
# 执行all-to-all操作,将所有设备的数据聚合到每个设备上。
all_to_all_single(local_output, intra_quant_int4, group=groups[f'local_{intra_idx}'])
all_to_all_single(scale_output, intra_q_scales, group=groups[f'local_{intra_idx}'])
# 对所有设备上的数据执行量化的归约操作,得到全局的输入tensor和全局的比例因子。
global_input_tensor, global_scales = quantizer_module.quantized_reduction(
local_output, scale_output, intra_quant_group, inter_quant_group, 4, quantizer_module.Symmetric)
# 创建两个与全局输入tensor和全局比例因子形状相同的tensor,用于存储后续操作的结果
global_output = torch.empty_like(global_input_tensor)
global_scale_output = torch.empty_like(global_scales)
# 执行all-to-all操作,将所有节点的数据聚合到每个节点上。
all_to_all_single(global_output, global_input_tensor, group=groups[f'global_{inter_idx}'])
all_to_all_single(global_scale_output, global_scales, group=groups[f'global_{inter_idx}'])
# 对聚合后的数据执行反量化操作,得到最终的输出。
final_output = quantizer_module.dequantize(global_output, global_scale_output, global_scale_output.numel(),
4, quantizer_module.Symmetric)
# 将最终的输出按节点数量切分,计算每个部分的和,然后取平均值,得到最终的结果,结果的形状是一维的。
output_lst[idx] = (sum(list(final_output.chunk(num_nodes))) / num_nodes).view(-1)
return output_lst
然后在https://github.com/microsoft/DeepSpeed/pull/3784/files#diff-1ad5daa1b31aa5573616024068d646f0c38e88d4d3a71d3d0e4bc352ea232178R1188-R1194 调用了这个all_to_all_quant_reduce实现。
对于qwZ 和 hpZ 的实现则在:https://github.com/microsoft/DeepSpeed/pull/3784/files#diff-bc45426db58250294594100cfdf3d73ecb653d879cabee404e38edc4eb4c9ecbR1051-R1164 。从源码来看qwZ和hpZ的实现并没有使用基于Block的quantization,而是普通的量化方法。调用的CUDAQuantizer解析如下:
# 这段代码定义了一个叫做 CUDAQuantizer 的类,主要用于实现对参数的量化和反量化操作。
class CUDAQuantizer:
async_flag = True # 这个没用到
target_group_size = 8000 # 定义了一个类变量,表示目标分组大小,可能是用于进行参数分组操作的。
group_size_cache = dict() # 定义了一个类变量,用作缓存各种参数数目(numel)对应的组大小。
def __init__(self):
# 调用deepspeed.ops.op_builder.QuantizerBuilder().load()来加载一个量化器模块,
# 赋值给self.quantizer_cuda_module。
self.quantizer_cuda_module = deepspeed.ops.op_builder.QuantizerBuilder().load()
# 定义量化方法,接受一个参数param,以及可选的参数groups,
# 如果没有提供groups,则通过计算和缓存来确定。
def quantize(self, param, groups=None):
if groups is None:
try:
# 尝试从缓存中获取param的元素数量对应的组大小。
groups = self.group_size_cache[param.numel()]
except KeyError:
# 如果缓存中没有,则计算一个初步的组大小,即param元素数量除以目标组大小向上取整。
groups = math.ceil(param.numel() / self.target_group_size)
# 两个循环,用于调整groups大小,使得它满足:能被param元素数量整除,
# 并且使得每个组的大小接近但不超过目标组大小。
while groups < param.numel():
if param.numel() % (8 * groups) == 0:
break
groups += 1
while True:
if param.numel() % (8 * groups * 2) == 0 and param.numel(
) / groups > self.target_group_size: #hard limit of 16k group_size
groups *= 2
else:
break
assert (
param.numel() % (8 * groups) == 0
), f"Qantized weight requires the number of weights be a multiple of 8. Yet {param.numel()} cannot be divided by 8*{groups}"
assert (param.numel() / groups < 16000), f"{param.numel()} / {groups} is larger than 16k"
assert param.numel(
) > groups, f"Adaptive grouping algorithm cannot find a group size for input tensor of size {param.numel()}"
self.group_size_cache[param.numel()] = groups # 将计算得到的groups大小缓存起来。
# 最后调用quantizer_cuda_module的quantize方法进行量化。
return self.quantizer_cuda_module.quantize(param.to(get_accelerator().device_name()), groups, 8,
self.quantizer_cuda_module.Symmetric)
# 定义反量化方法,接受已经被量化的参数和一个比例因子。
def dequantize(self, quantized_param, scale):
return self.quantizer_cuda_module.dequantize(quantized_param, scale, scale.numel(), 8,
self.quantizer_cuda_module.Symmetric)
这里再解析一下对这个量化类调用的部分,也就是https://github.com/microsoft/DeepSpeed/pull/3784/files#diff-bc45426db58250294594100cfdf3d73ecb653d879cabee404e38edc4eb4c9ecbR1051-R1164:
# 这段代码的主要目的是执行AllGather操作,将所有设备上的参数值收集到每个设备上,并且这个过程可能会对参数值进行量化,以减小通信带宽的需求。
# 检查 params(应该是一个包含模型参数的列表)的长度是否为 1。如果是,那么可以避免一些额外的内存分配。
if len(params) == 1:
# have an opportunity to avoid some intermediate memory allocations
param, = params
# 计算缓冲区的大小。这个大小是参数的元素数量(param.ds_numel)除以设备的数量(world_size)然后向上取整,
# 再乘以设备的数量。这样做是为了确保缓冲区的大小是设备数量的整数倍。
buffer_size = math.ceil(param.ds_numel / world_size) * world_size
# 如果当前是在进行反向传播,并且参数有第二存储(param.ds_secondary_tensor),
# 那么更新缓冲区的大小,使其等于第二存储的大小乘以设备的数量。
if not forward and param.ds_secondary_tensor is not None:
buffer_size = param.ds_secondary_tensor.shape[0] * world_size #make sure out is appropriately sized
# 创建一个空的 PyTorch 张量 param_buffer,用于存储全局收集的结果。
# 这个张量的大小是 buffer_size,数据类型根据是否进行量化而变化,设备是当前设备,不需要计算梯度。
param_buffer = torch.empty(
buffer_size,
dtype=param.dtype if not quant else torch.int8,
device=get_accelerator().current_device(),
requires_grad=False,
)
# 根据当前是否在进行反向传播和参数是否有第二存储,从 param.ds_tensor 或 param.ds_secondary_tensor 中获取数据。
param_ds_tensor = param.ds_secondary_tensor if not forward and param.ds_secondary_tensor is not None else param.ds_tensor
if not quant:
# 如果不进行量化,那么直接执行AllGather操作,并将结果存储到 param.data 中。
# 返回一个 AllGatherHandle 对象,包含了AllGather的句柄和参数对象。
handles = _dist_allgather_fn(
param_ds_tensor.to(get_accelerator().current_device()),
param_buffer,
ds_process_group,
)
param.data = param_buffer.narrow(0, 0, param.ds_numel).view(param.ds_shape).to(param.device)
return AllGatherHandle(handles, param)
else:
# 这段代码主要完成了对参数的量化处理以及AllGather操作,并对量化信息进行了保存。
# 使用 self.quantizer_module 的 quantize 方法对参数 param_ds_tensor 进行量化。
# 这个方法返回两个值:量化后的参数 quantized_param 和量化所使用的尺度 scales。
quantized_param, scales = self.quantizer_module.quantize(param_ds_tensor)
# 调用 _dist_allgather_fn 函数执行AllGather操作,将 quantized_param Gather
# 到 param_buffer 中。这个函数返回一个句柄 handle,用于表示这个AllGather操作。
handle = _dist_allgather_fn(quantized_param.to(get_accelerator().current_device()), param_buffer,
ds_process_group)
# 创建一个空的 PyTorch 张量 quant_scale_buffer,用于存储AllGather的尺度。
# 这个张量的大小是尺度元素数量乘以设备数量,数据类型是 torch.float32,设备是当前设备,不需要计算梯度。
quant_scale_buffer = torch.empty(
scales.numel() * world_size,
dtype=torch.float32,
device=get_accelerator().current_device(),
requires_grad=False,
)
# 调用 _dist_allgather_fn 函数执行AllGather操作,将 scales 收集到 quant_scale_buffer 中。
# 这个函数返回一个句柄 quant_handle,用于表示这个AllGather操作。
quant_handle = _dist_allgather_fn(scales.to(get_accelerator().current_device()),
quant_scale_buffer, ds_process_group)
# 创建一个 QuantizationInfo 对象 quant_info,用于存储量化的信息。
quant_info = QuantizationInfo()
# 将 param_buffer 中的量化参数拷贝到 quant_info.quantized_param 中。
quant_info.quantized_param = param_buffer.narrow(0, 0, param.ds_numel).view(param.ds_shape).to(
param.device)
# 将量化模块 self.quantizer_module 保存到 quant_info.backend 中。
quant_info.backend = self.quantizer_module
# 将量化的AllGather句柄 quant_handle 保存到 quant_info.quant_handle 中。
quant_info.quant_handle = quant_handle
# 将量化的尺度缓冲区 quant_scale_buffer 保存到 quant_info.scale_buffer 中。
quant_info.scale_buffer = quant_scale_buffer
# 返回一个 AllGatherHandle 对象,包含了AllGather的句柄 handle、参数对象 param 和量化的信息 quant_info。
return AllGatherHandle(handle, param, quantization=quant_info)
else:
# 下面的代码比较类似,就不做解释了
partition_sz = sum(p.ds_tensor.ds_numel for p in params)
if params[0].ds_secondary_tensor is not None and not forward:
partition_sz = sum(p.ds_tensor.ds_numel * p.ds_secondary_tensor_num_of_groups for p in params)
flat_tensor = torch.empty(partition_sz * world_size,
dtype=get_only_unique_item(p.dtype
for p in params) if not quant else torch.int8,
device=get_accelerator().current_device(),
requires_grad=False)
if not quant:
partitions: List[Parameter] = []
for i in range(world_size):
partitions.append(flat_tensor.narrow(0, partition_sz * i, partition_sz))
if params[0].ds_secondary_tensor is not None and not forward:
use_secondary_tensor = True
instrument_w_nvtx(torch.cat)(
[p.ds_secondary_tensor.to(get_accelerator().current_device_name()) for p in params],
out=partitions[rank_in_group])
else:
instrument_w_nvtx(
torch.cat)([p.ds_tensor.to(get_accelerator().current_device_name()) for p in params],
out=partitions[rank_in_group])
handle = _dist_allgather_fn(partitions[rank_in_group], flat_tensor, ds_process_group)
#Fix get_partition_dp_group(params[0]))
return AllGatherCoalescedHandle(
allgather_handle=handle,
params=params,
partitions=partitions,
world_size=world_size,
use_secondary_tensor=use_secondary_tensor,
forward=forward,
)
else:
if params[0].ds_secondary_tensor is not None and not forward:
use_secondary_tensor = True
quantized_param, scales = self.quantizer_module.quantize(
instrument_w_nvtx(torch.cat)(
[p.ds_secondary_tensor.to(get_accelerator().current_device()) for p in params]))
else:
quantized_param, scales = self.quantizer_module.quantize(
instrument_w_nvtx(
torch.cat)([p.ds_tensor.to(get_accelerator().current_device()) for p in params]))
handle = _dist_allgather_fn(quantized_param, flat_tensor, ds_process_group)
quant_info = QuantizationInfo()
quant_scale_buffer = torch.empty(
scales.numel() * world_size,
dtype=torch.float32,
device=get_accelerator().current_device(),
requires_grad=False,
)
quant_handle = _dist_allgather_fn(scales, quant_scale_buffer, ds_process_group)
quant_info.quantized_param = flat_tensor
quant_info.backend = self.quantizer_module
quant_info.quant_handle = quant_handle
quant_info.scale_buffer = quant_scale_buffer
quant_info.partition_sz = partition_sz
quant_info.world_size = world_size
return AllGatherCoalescedHandle(
allgather_handle=handle,
params=params,
partitions=None,
world_size=world_size,
use_secondary_tensor=use_secondary_tensor,
forward=forward,
quantization=quant_info,
)
这里再额外对param.ds_secondary_tensor做一个解释:
ds_secondary_tensor 是 DeepSpeed ZeRO 阶段 3(ZeRO-3)中用于存储模型参数的第二存储。在 ZeRO-3 中,模型的每个参数都被划分成多个部分,并在多个设备(例如,多个 GPU)之间进行分布存储。每个设备都存储一部分参数,这部分参数存储在 ds_tensor 属性中。同时,每个设备还有一个 ds_secondary_tensor,用于存储该设备需要的其他设备上的参数部分。这种设计可以减小每个设备的内存占用,从而允许在有限的内存中训练更大的模型。
具体来说,上面代码中的 param.ds_secondary_tensor 是指向当前参数在当前设备上的第二存储的引用。如果 param.ds_secondary_tensor 为 None,说明当前参数没有第二存储,即所有的参数都存储在 ds_tensor 中。
0x3. zero++的测试解析
# DeepSpeed Team
import pytest
import deepspeed.comm as dist
from torch.nn import Module
from unit.common import DistributedTest
from unit.simple_model import random_dataloader
import deepspeed
from deepspeed.runtime.zero.config import DeepSpeedZeroConfig
import torch.nn as nn
# 首先,定义一个神经网络模型 NNModel,它是由多个全连接层和一个交叉熵损失函数组成。
class NNModel(nn.Module):
def __init__(self, h_dim=1024, n_layers=2):
super(NNModel, self).__init__()
self.layers = nn.ModuleList([nn.Linear(h_dim, h_dim) for i in range(n_layers)])
self.cross_entropy_loss = nn.CrossEntropyLoss()
def forward(self, x, y):
for layer in self.layers:
x = layer(x)
return self.cross_entropy_loss(x, y)
# 在函数中,首先创建一个 DeepSpeedZeroConfig 实例 config。
# 创建实例时,使用了 Python 的解包运算符 ** 将一个字典作为参数传入。
# 字典中有一个键值对 "zero_hpz_partition_size": 4,
# 这表示设置 ZeRO++ 的hpz划分大小为 4。
# 这个测试函数的目的是验证 DeepSpeedZeroConfig 的 zero_hpz_partition_size 属性是否能正确设置和获取。
def test_zero_hpz_partition_size_config():
config = DeepSpeedZeroConfig(**{"zero_hpz_partition_size": 4})
assert config.zero_hpz_partition_size == 4
# 函数内部,遍历了 model 的所有命名参数。model.named_parameters() 返回一个迭代器,
# 每次迭代返回一个元组,包含参数的名字和参数对象。
# 然后,对于每个参数对象 param,使用 assert 关键字进行断言。
# 断言 param.ds_secondary_tensor is None 检查 param 的 ds_secondary_tensor 属性是否为 None。
# ds_secondary_tensor 是 DeepSpeed ZeRO-3 中的一个属性,表示这个参数的第二存储。
# 如果这个属性为 None,说明没有为这个参数分配第二存储,这可能意味着 ZeRO-3 没有正确应用到这个参数。
def _assert_no_secondary_tensor_group(model: Module) -> None:
for _, param in model.named_parameters():
assert param.ds_secondary_tensor is None
assert param.ds_zero_param_process_group is None
# 函数内部,遍历了 model 的所有命名参数。model.named_parameters() 返回一个迭代器,
# 每次迭代返回一个元组,包含参数的名字和参数对象。
# 然后,对于每个参数对象 param,使用 assert 关键字进行断言。
# 断言 param.ds_secondary_tensor is not None 检查 param 的 ds_secondary_tensor 属性是否为 None。
# ds_secondary_tensor 是 DeepSpeed ZeRO-3 中的一个属性,表示这个参数的第二存储。如果这个属性为 None,
# 说明没有为这个参数分配第二存储,即所有的参数都存储在 ds_tensor 中。
def _assert_secondary_tensor_size(model: Module) -> None:
for _, param in model.named_parameters():
assert param.ds_secondary_tensor is not None
assert param.ds_secondary_tensor.size()[0] % param.ds_tensor.size()[0] == 0
# 这段代码定义了一个使用 PyTest 框架的单元测试类 TestZeroPPConfigSweep,
# 用于测试 DeepSpeed 的 zero3++ 优化的配置。特别地,它测试了不同的隐藏维度 h_dim、
# 层数 n_layers 和 ZeRO-3++ zero_hpz_partition_size(zpg) 大小对模型的影响。
#Large sweep along hidden dim, num_layers, and zpg of different sizes
#Assert when zpg=1 that secondary group and tensors are invalid
@pytest.mark.sequential
@pytest.mark.parametrize("h_dim", [1024])
@pytest.mark.parametrize("n_layers", [4, 9])
@pytest.mark.parametrize("zpg", [1, 2, 4])
class TestZeroPPConfigSweep(DistributedTest):
world_size = 4
def test(self, h_dim: int, n_layers: int, zpg: int) -> None:
config_dict = {
"train_micro_batch_size_per_gpu": 1,
"zero_optimization": {
"stage": 3,
"stage3_max_reuse_distance": 0,
"zero_hpz_partition_size": zpg,
"zero_quantized_weights": True,
"zero_quantized_gradients": True,
"contiguous_gradients": True,
"overlap_comm": True,
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 1.
}
},
"fp16": {
"enabled": True,
"loss_scale": 1.,
}
}
model = NNModel(h_dim, n_layers)
model, _, _, _ = deepspeed.initialize(model=model, model_parameters=model.parameters(), config=config_dict)
data_loader = random_dataloader(model=model, total_samples=20, hidden_dim=h_dim, device=model.device)
dist.barrier()
if zpg == 1:
_assert_no_secondary_tensor_group(model)
for n, batch in enumerate(data_loader):
if n == 0 and zpg != 1:
_assert_secondary_tensor_size(model)
loss = model(batch[0], batch[1])
model.backward(loss)
model.step()
这个不仅是zero++的测试脚本,也给我们指出了如何使用zero++提供的qgZ,qwZ,hpZ的feature。
0x4. 总结
这篇文章从DeepSpeed Zero++的博客出发,做了zero++博客的翻译和原理理解。然后深入到zero++的代码实现,将核心的2个cuda kerne:swizzled_quant_kernel和dequant_reduce进行了解析。接着,基于这两个kernel导出的pybind接口对上层的qgZ,qwZ,hpZ的python实现调用链进行了跟踪和代码解析。在解析qwZ 和 hpZ的时候明白了对zero3切分权重的核心实现是ds_secondary_tensor和ds_tensor。最后对qgZ,qwZ,hpZ的测试脚本进行了解析且这个脚本也指出了要启用qgZ,qwZ,hpZ的使用方法。大家也可以参考zero++的paper和deepspeed源码来获得更多细节。
0x5. 参考文献
- https://zhuanlan.zhihu.com/p/641297077
- https://zhuanlan.zhihu.com/p/639002087
- deepspeed论文:https://www.microsoft.com/en-us/research/publication/zero-extremely-efficient-collective-communication-for-giant-model-training/














 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









