








搭建神经网络的一些trick(持续更新)
以前都是在用别人现成搭建好的网络,所以对搭建网络的初始化操作就没有留意过,现在来总结一下。
权重初始化
先说一下不得不提的IID假设:就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。因为我们在基于mini-batch训练的时候不能保证每一个mini-batch都是符合IID假设的,所以就带来了权重初始化的问题。
一般我们书中学到的的权重初始化,将W初始化为0,将b初始化为0/1.但是这样是不可行的,或者说是不恰当的。如果所有的参数都是0,那么所有神经元的输出都将是相同的,那在back propagation的时候同一层内所有神经元的行为也是相同的 — gradient相同,weight update也相同。这显然是一个不可接受的结果。
在日常我们用到的最多的就是用别人的pre-training,早期的pretrain有以下两个步骤:(1)pre-training阶段,将神经网络中的每一层取出,构造一个auto-encoder做训练,使得输入层和输出层保持一致。在这一过程中,参数得以更新,形成初始值(2)fine-tuning阶段,将pre-train过的每一层放回神经网络,利用pre-train阶段得到的参数初始值和训练数据对模型进行整体调整。在这一过程中,参数进一步被更新,形成最终模型。现在阶段我们一般使用的是别人在coco或者是imagenet上训练好任务A的pre-trained model来进行我们的任务B的fine-tuning训练。
下面来讲一下两个比较常用的权重初始化:
1、Xavier initialization
Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0(梯度消失)。(随机初始化的弊端)Xavier初始化的推导过程是基于线性函数的,但是它在一些非线性神经元中也很有效。让我们试一下:(图片参考于这篇博文)
W = tf.Variable(np.random.randn(node_in, node_out)) / np.sqrt(node_in)

可以看到输出值在很多层以后还能保持良好的分布。
正如上面代码中所示,Xavier Initialization的权重初始化:bias初始化为0,为Normalize后的参数乘以一个rescale系数:1/\sqrt n,n是输入参数的个数。
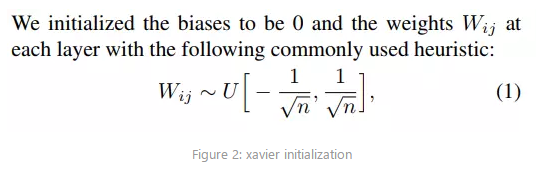
公式推导略显复杂,有兴趣的可以看一下。

由于Xavier Initialization是基于线性激活函数进行的推倒所以,当遇到relu等非线性激活函数以后,就还是会出现梯度消失的问题。
那该怎么解决呢接着就出现了Kaiming Initialization,其实就是将rescale系数:1/\sqrt n,改为2/\sqrt n即可。效果出乎意料的好,已经被pytorch用为默认的初始化方案。
下面是对整个网络的权重参数初始化操作:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('conv') != -1:
xavier_normal_(m.weight.data)
constant_(m.bias.data, 0.0)
elif classname.find('layer') != -1:
xavier_normal_(m.weight.data)
constant_(m.bias.data, 0.0)
elif classname.find('bn') != -1:
constant_(m.weight.data)
constant_(m.bias.data, 0.0)
BN/GN
Batch Normalization是一种巧妙而粗暴的方法来削弱bad initialization的影响,其基本思想是:If you want it, just make it!
“Internal Covariate Shift”问题:在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
然后提出了BatchNorm的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了,顺带解决反向传播中梯度消失问题。BN 其实就是在做 feature scaling,而且它的目的也是为了在训练的时候避免这种 Internal Covariate Shift 的问题,只是刚好也解决了 sigmoid 函数梯度消失的问题。
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
激活值的方差是逐层递减的,这导致反向传播中的梯度也逐层递减。要解决梯度消失,就要避免激活值方差的衰减,最理想的情况是,每层的输出值(激活值)保持高斯分布。
那么最简单粗暴的办法就是直接对每一层的输出值进行Gaussian Normalization和线性变换!!
看到这里你大概就知道了,BN其实就是把非线性激活函数作用后趋于极限饱和区的输入分布强行拉回到标准正态分布,使其线性化。但是这里就有一个疑问出现了?这样不就是一个relu可以解决的问题吗?
确实,那么BN使其线性化以后,为了还保留其非线性的特性,就有了最后一步的scale and shift。

Batch Normalization中所有的操作都是平滑可导,这使得back propagation可以有效运行并学到相应的参数\gamma,\beta。需要注意的一点是Batch Normalization在training和testing时行为有所差别。Training时\mu_\mathcal{B}和\sigma_\mathcal{B}由当前batch计算得出;在Testing时\mu_\mathcal{B}和\sigma_\mathcal{B}应使用Training时保存的均值或类似的经过处理的值,而不是由当前batch计算。
相似的还有LN/IN/GN/WN/CN等等,感兴趣的可以看看这个博主写的很好。下面是这几种方法的示意图。

通俗的讲:BN是在 batch这个维度上进行归一化,GN是计算channel方向每个group的均值方差.(划重点!!!面试要考)















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









