







1. Capsule介绍
Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. “Dynamic routing between capsules.” Advances in neural information processing systems. 2017.
Capsule特色是“vector in vector out”,取代了以往的“scaler in scaler out”,也就是神经元的输入输出都变成了向量,从而算是对神经网络理论的一次革命。
然而在目前的深度学习中,从来不缺乏“vector in vector out”的案例,因此显然这不能算是Capsule的革命。比如在NLP中,一个词向量序列的输入模型,这个词向量序列再经过RNN/CNN/Attention的编码,输出一个新序列,不也是“vector in vector out”吗?
Capsule的革命在于:它提出了一种新的“vector in vector out”的传递方案,并且这种方案在很大程度上是可解释的。
深度学习(神经网络)为什么有效:神经网络通过层层叠加完成了对输入的层层抽象,这个过程某种程度上模拟了人的层次分类做法,从而完成对最终目标的输出,并且具有比较好的泛化能力。的确,神经网络应该是这样做的,然而它并不能告诉我们它确确实实是这样做的,这就是神经网络的难解释性,也就是很多人会将深度学习视为黑箱的原因之一。
下面介绍Capsule是怎么突破这一点的。
2. CapsNet模型
CapsNet: 两个卷积层(Conv 1, PrimaryCaps),一个全连接层(DigitCaps)
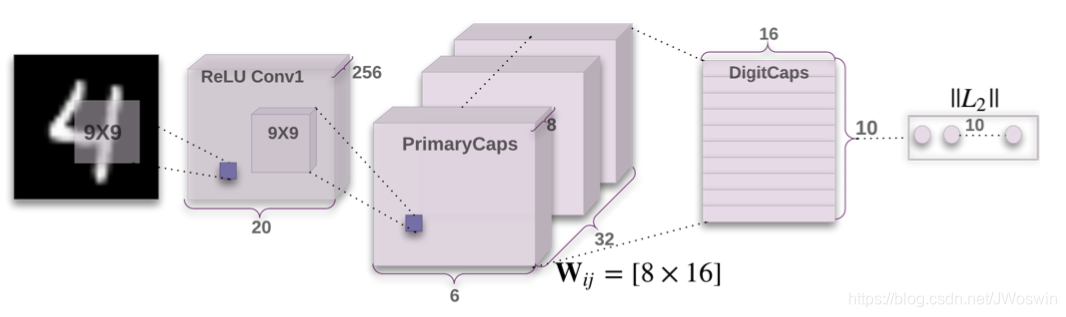
2.1 Conv1层
常规的卷积层, 起像素级局部特征检测作用

s
h
a
p
e
:
[
N
o
n
e
,
28
,
28
,
1
]
→
[
N
o
n
e
,
20
,
20
,
256
]
shape: [None,28,28,1] \rightarrow [None,20,20,256]
shape:[None,28,28,1]→[None,20,20,256]
2.2 PrimaryCaps层
生成最低级卷积8D胶囊层(无路由)
胶囊:其实,只要把一个向量当作一个整体来看,它就是一个“胶囊”。可以这样理解:神经元就是标量,胶囊就是向量。Hinton的理解是:每一个胶囊表示一个属性,而胶囊的向量则表示这个属性的“标架”。也就是说,我们以前只是用一个标量表示有没有这个特征(比如有没有羽毛),现在我们用一个向量来表示,不仅仅表示有没有,还表示“有什么样的”(比如有什么颜色、什么纹理的羽毛),如果这样理解,就是说在对单个特征的表达上更丰富了。
简单的讲,PrimaryCaps层要输出一些8D的向量,每个向量代表一些比较低级的特征,向量的各个位置的值代表该特征的属性
PrimaryCaps层: 计算过程具有多种理解方式,其中之一为,8个并行的常规卷积层的叠堆
PrimaryCaps层的第一种理解方式
8个并行的常规卷积层:
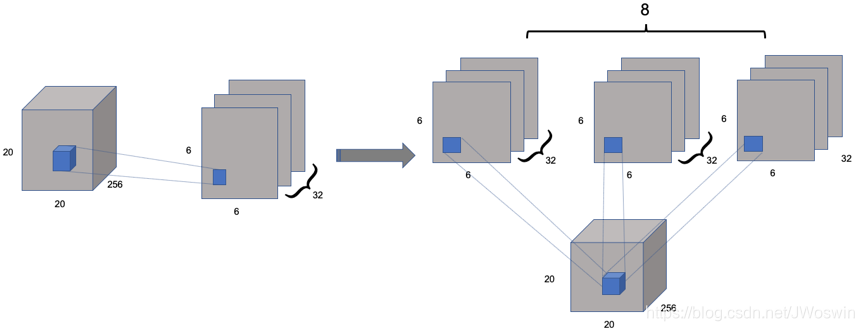
卷积操作2参数:

对Conv1层的输出进行8次卷积操作2所示的卷积操作:
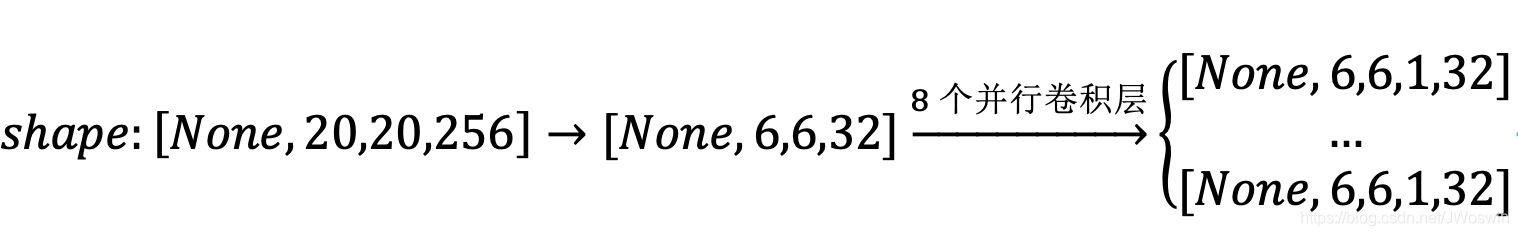
然后对8个并行常规卷积层叠堆(对每个卷积层的各个通道在第四个维度上进行合并):
8个[6,6,1,32]卷积层合并示意图如下:
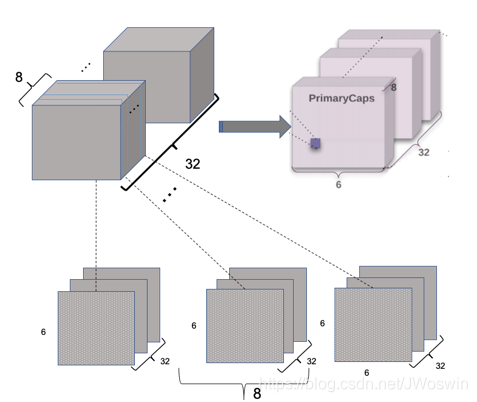
得到叠堆后的结果:[None,6,6,8,32]
然后展开为[None,6x6x32,8,1]=[None,1152,8,1],这样我们就得到了1152个初始胶囊,每个胶囊是一个纬度为[8,1]的向量,并代表某一特征
PrimaryCaps层的第二种理解方式
- 32个通道之间的卷积核是独立的(9x9大小)
- 8个并行卷积层之间的参数也是独立的
R
i
g
h
t
a
r
r
o
w
Rightarrow
Rightarrow 即共有8x32个大小为9x9的相互独立的卷积核,可看作8x32个通道的常规卷积和
则可以用下面的操作得到和第一种理解方式相同的结果

输出:
[
N
o
n
e
,
6
,
6
,
32
∗
8
]
→
r
e
s
h
a
p
e
[
N
o
n
e
,
1152
,
8
,
1
]
)
[None,6,6,32*8] \overset{reshape}{\rightarrow} [None,1152,8,1])
[None,6,6,32∗8]→reshape[None,1152,8,1])
注意:虽然计算方式上与常规卷积层无差异,但意义上却已经大不相同!将达到8x1capsule的特征封装的效果
PrimaryCaps输出输出1152个8D的胶囊后,使用了一个Squash函数做非线性变换,那么,为什么要设计这个函数呢?这个函数的原理是啥
2.3 Squash函数
为什么要设计squash函数:
因为论文希望Capsule能有一个性质:胶囊的模长能够代表这个特征的概率,即特征的“显著程度”, 模长越大,这个特征越显著,而我们又希望有一个有界的指标来对这个“显著程度”进行衡量,所以就只能对这个模长进行压缩了
squash函数的原理:
s q u a s h ( x ) = ∣ ∣ x ∣ ∣ 2 1 + ∣ ∣ x ∣ ∣ 2 x ∣ ∣ x ∣ ∣ squash(x) = \frac{||x||^2}{1+||x||^2} \frac{x}{||x||} squash(x)=1+∣∣x∣∣2∣∣x∣∣2∣∣x∣∣x
- x ∣ ∣ x ∣ ∣ \frac{x}{||x||} ∣∣x∣∣x: 将x的模长变为1
- ∣ ∣ x ∣ ∣ 2 1 + ∣ ∣ x ∣ ∣ 2 \frac{||x||^2}{1+||x||^2} 1+∣∣x∣∣2∣∣x∣∣2: 起缩放x的模长的作用,x模长越大, ∣ ∣ x ∣ ∣ 2 1 + ∣ ∣ x ∣ ∣ 2 \frac{||x||^2}{1+||x||^2} 1+∣∣x∣∣2∣∣x∣∣2越趋近于1,||x||=0时, ∣ ∣ x ∣ ∣ 2 1 + ∣ ∣ x ∣ ∣ 2 = 0 \frac{||x||^2}{1+||x||^2}=0 1+∣∣x∣∣2∣∣x∣∣2=0
则 y = s q u a s h ( x ) y=squash(x) y=squash(x)的效果为:x的模长越大,y的模长越趋近于1
PrimaryCaps输出的1152个8D的胶囊经过squash函数后非线性变换后,都具有了胶囊的模长能够代表这个特征的概率的特性,这些新的胶囊接着作为DigitCaps层的输入。
2.4 DigitCaps层
由于该层解释起来比较复杂,所以先从简单例子开始,慢慢推出该层的流程及原理。
capsule示意
capsule示意图:
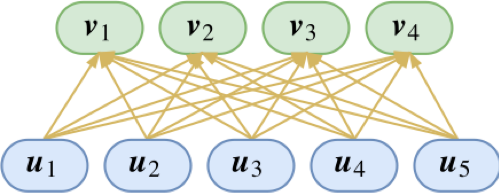
如上图所示,底层的胶囊和高层的胶囊构成一些连接关系那么,这些胶囊要怎么运算,才能体现出“层层抽象”、“层层分类”的特性呢?让我们先看其中一部分连接:
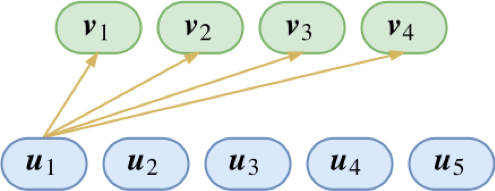
u,v都是胶囊,图上只展示了
u
1
u_1
u1的连接。这也就是说,目前已经有了
u
1
u_1
u1这个特征(假设是羽毛),那么我想知道它属于上层特征
v
1
,
v
2
,
v
3
,
v
4
v_1,v_2 ,v_3,v_4
v1,v2,v3,v4(假设分别代表了鸡、鸭、鱼、狗)中的哪一个。分类问题我们显然已经是很熟悉了,不就是内积后softmax吗?于是单靠
u
1
u_1
u1这个特征,我们推导出它是属于鸡、鸭、鱼、狗的概率分别是:
( p 1 ∣ 1 , p 2 ∣ 1 , p 3 ∣ 1 , p 4 ∣ 1 ) = 1 Z 1 ( e < u 1 , v 1 > , e < u 1 , v 2 > , e < u 1 , v 3 > , e < u 1 , v 4 > ) (p_{1|1},p_{2|1},p_{3|1},p_{4|1})=\frac{1}{Z_1} (e^{<u_1,v_1>},e^{<u_1,v_2>},e^{<u_1,v_3>},e^{<u_1,v_4>}) (p1∣1,p2∣1,p3∣1,p4∣1)=Z11(e<u1,v1>,e<u1,v2>,e<u1,v3>,e<u1,v4>)
我们期望
p
1
∣
1
,
p
2
∣
1
p_{1|1},p_{2|1}
p1∣1,p2∣1会明显大于
p
3
∣
1
,
p
4
∣
1
p_{3|1},p_{4|1}
p3∣1,p4∣1(鸡鸭有羽毛,鱼狗没羽毛)不过,单靠这个特征还不够,我们还需要综合各个特征,于是可以把上述操作对各个u_i都做一遍,继而得到
(
p
1
∣
2
,
p
2
∣
2
,
p
3
∣
2
,
p
4
∣
2
)
,
(
p
1
∣
3
,
p
2
∣
3
,
p
3
∣
3
,
p
4
∣
3
)
,
.
.
.
(p_{1|2},p_{2|2},p_{3|2},p_{4|2}), (p_{1|3},p_{2|3},p_{3|3},p_{4|3}), ...
(p1∣2,p2∣2,p3∣2,p4∣2),(p1∣3,p2∣3,p3∣3,p4∣3),...
问题是,现在得到这么多预测结果,究竟要选择哪个呢?而且又不是真的要做分类,我们要的是融合这些特征,构成更高级的特征。
于是Hinton认为,既然 u i u_i ui这个特征得到的概率分布是 ( p 1 ∣ i , p 2 ∣ i , p 3 ∣ i , p 4 ∣ i ) (p_{1|i},p_{2|i},p_{3|i},p_{4|i}) (p1∣i,p2∣i,p3∣i,p4∣i)那么我把这个特征切成四份,分别为 ( p 1 ∣ i u i , p 2 ∣ i u i , p 3 ∣ i u i , p 4 ∣ i u i ) (p_{1|i}u_i,p_{2|i}u_i,p_{3|i}u_i,p_{4|i}u_i) (p1∣iui,p2∣iui,p3∣iui,p4∣iui), 然后把这几个特征分别传给 v 1 , v 2 , v 3 , v 4 v_1,v_2,v_3,v_4 v1,v2,v3,v4,最后 v 1 , v 2 , v 3 , v 4 v_1,v_2,v_3,v_4 v1,v2,v3,v4其实就是底层传入的特征的累加
v j = s q u a s h ( p j ∣ i u i ) = s q u a s h ( ∑ i e < u i , v j > Z i u i ) v_j=squash(p_{j|i} u_i )=squash(\sum_{i} \frac{e^{<u_i,v_j>}}{Z_i} u_i) vj=squash(pj∣iui)=squash(i∑Zie<ui,vj>ui)
从上往下看,那么Capsule就是每个底层特征分别做分类,然后将分类结果整合。这时 v j v_j vj应该尽量与所有 u i u_i ui都比较靠近,靠近的度量是内积。因此,从下往上看的话,可以认为 v j v_j vj实际上就是各个 u i u_i ui的某个聚类中心,而Capsule的核心思想就是输出是输入的某种聚类结果。
动态路由:
注意到式子 v j = s q u a s h ( ∑ i e < u i , v j > Z i u i ) v_j=squash(\sum_{i} \frac{e^{<u_i,v_j>}}{Z_i} u_i) vj=squash(∑iZie<ui,vj>ui),为了求 v j v_j vj需要求softmax,可是为了求softmax又需要知道 v j v_j vj,这不是个鸡生蛋、蛋生鸡的问题了吗?而“动态路由”正是为了解决这一问题而提出的,它能够根据自身的特性来更新(部分)参数,从而初步达到了Hinton的放弃梯度下降的目标
下面通过几个例子来解释动态路由的过程:
例1:
让我们先回到普通的神经网络,大家知道,激活函数在神经网络中的地位是举足轻重的。当然,激活函数本身很简单,比如一个tanh激活的全连接层。
可是,如果想用
x
=
y
+
c
o
s
y
x=y+cosy
x=y+cosy的反函数来激活呢?也就是说,得解出
y
=
f
(
x
)
y=f(x)
y=f(x),然后再用它来做激活函数。
然而
x
=
y
+
c
o
s
y
x=y+cosy
x=y+cosy的反函数是一个超越函数,也就是不可能用初等函数有限地表示出来。
但我们可以通过迭代法求出y:
y
n
+
1
=
x
−
c
o
s
y
n
y_{n+1} = x - cos y_n
yn+1=x−cosyn
选择
y
0
=
x
y_0=x
y0=x,代入上式迭代几次,基本上就可以得到比较准确的y了。假如迭代3次,那就是
y
=
x
−
c
o
s
(
x
−
c
o
s
(
x
−
c
o
s
x
)
)
y=x-cos(x-cos(x-cosx))
y=x−cos(x−cos(x−cosx))
可以发现这和动态路由的过程有点像
例2:
再来看一个例子,这个例子可能在NLP中有很多对应的情景,但图像领域其实也不少。考虑一个向量序列
(
x
1
,
x
2
,
…
,
x
n
)
(x_1,x_2,…,x_n)
(x1,x2,…,xn),我现在要想办法将这n个向量整合成一个向量x(encoder),然后用这个向量来做分类:
x
=
∑
i
=
1
n
λ
i
x
i
x= \sum_{i=1}^n \lambda _i x_i
x=i=1∑nλixi
这里的λ_i相当于衡量了x与x_i的相似度。那么,在x出现之前,凭什么能够确定这个相似度呢?
解决这个问题的一个方案也是迭代。首先我们也可以定义一个基于softmax的相似度指标,然后让
x = ∑ i = 1 n e < x , x i > Z x i x= \sum_{i=1}^n \frac{e^{<x,x_i>}}{Z} x_i x=i=1∑nZe<x,xi>xi
一开始,我们一无所知,所以只好取x为各个 x i x_i xi的均值,然后代入右边就可以算出一个x,再把它代入右边,反复迭代就行,一般迭代有限次就可以收敛,于是就可以将这个迭代过程嵌入到神经网络中了。
如果说例1跟动态路由只是神似,那么例2已经跟动态路由是神似+形似了。
通过例1,例2,已经可以很清晰的开始解释动态路由过程了
为了得到各个v_j,一开始先让它们全都等于u_i的均值,然后反复迭代就好。说白了,输出是输入的聚类结果,而聚类通常都需要迭代算法,这个迭代算法就称为“动态路由”。
到此,就可以写出论文里的动态路由的算法了:
动态路由算法
初始化
b
i
j
b_{ij}
bij=0
迭代r次:
c
i
←
s
o
f
t
m
a
x
(
b
i
)
c_i \leftarrow softmax(b_i)
ci←softmax(bi)
s
j
←
∑
i
c
i
j
u
i
s_j \leftarrow \sum_i c_{ij} u_i
sj←∑icijui
v
j
←
s
q
u
a
s
h
(
s
j
)
v_j \leftarrow squash(s_j)
vj←squash(sj)
b
i
j
←
b
i
j
+
<
u
i
,
v
j
>
b_{ij} \leftarrow b_{ij} + <u_i,v_j>
bij←bij+<ui,vj>
返回
v
j
v_j
vj
这里的 c i j c_{ij} cij就是前文的 p j ∣ i p_{j|i} pj∣i前面已经说了, v j v_j vj是作为输入 u i u_i ui的某种聚类中心出现的,而从不同角度看输入,得到的聚类结果显然是不一样的。那么为了实现“多角度看特征”,于是可以在每个胶囊传入下一个胶囊之前,都要先乘上一个矩阵做变换,所以式 v j = s q u a s h ( ∑ i e < u i , v j > Z i u i ) v_j=squash(\sum_{i} \frac{e^{<u_i,v_j>}}{Z_i} u_i) vj=squash(∑iZie<ui,vj>ui)实际上应该要变为
v j = s q u a s h ( ∑ i e < u i , v j > Z i u ^ j ∣ i ) v_j=squash(\sum_{i} \frac{e^{<u_i,v_j>}}{Z_i} \hat{u} _{j|i}) vj=squash(∑iZie<ui,vj>u^j∣i)
u ^ j ∣ i = W j i u i \hat{u}_{j|i} = W_{ji} u_i u^j∣i=Wjiui
这里的
W
j
i
W_{ji}
Wji是待训练的矩阵,这里的乘法是矩阵乘法,也就是矩阵乘以向量。所以,Capsule变成了下图
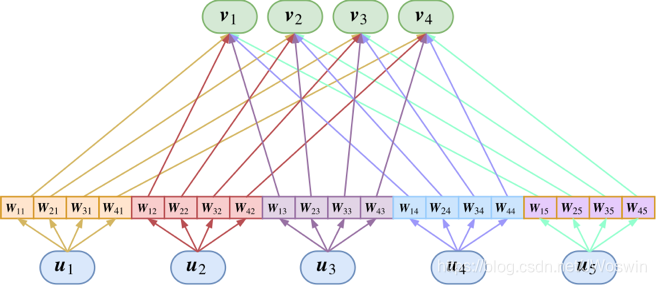
这时候就可以得到完整动态路由了:
动态路由算法
初始化
b
i
j
b_{ij}
bij=0
迭代r次:
c
i
←
s
o
f
t
m
a
x
(
b
i
)
c_i \leftarrow softmax(b_i)
ci←softmax(bi)
s
j
←
∑
i
c
i
j
u
^
j
∣
i
s_j \leftarrow \sum_i c_{ij} \hat{u}_{j|i}
sj←∑iciju^j∣i
v
j
←
s
q
u
a
s
h
(
s
j
)
v_j \leftarrow squash(s_j)
vj←squash(sj)
b
i
j
←
b
i
j
+
<
u
i
,
v
j
>
b_{ij} \leftarrow b_{ij} + <u_i,v_j>
bij←bij+<ui,vj>
返回
v
j
v_j
vj
这样的Capsule层,显然相当于普通神经网络中的全连接层。
DigitCaps层流程总结
- 将PrimaryCaps输入的1152个8D的胶囊从乘 W j i W_{ji} Wji,以达到不同角度看输入的目的,得到[None,10,1152,16,1]
- 对每个1152里面的16D的胶囊,通过动态路由算法聚类出一个 v j v_j vj
- 返回[None,10,16],即输出10个胶囊,分别对应数字0~9,胶囊的模长代表是该数字的概率,每个胶囊内部的值代表了该数字的某一属性
2.5 重构层
重构层就比较简单了,但是也有一些细节需要说明一下
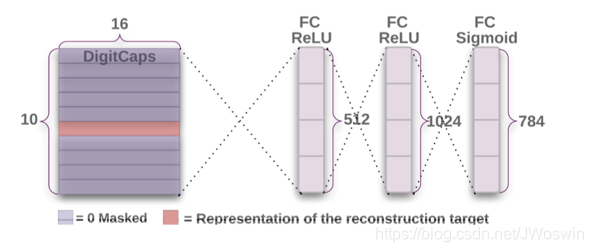
网络很简单,就是三个全连接层,其中有个masked操作,具体原理如下:
因为DigitCaps输出[None,10,16],即每个样本输出10个16D的胶囊,胶囊的模长代表图片是这个类别的概率,而每个16D的胶囊里面各个位置的值则代表了这个数字的一系列属性,重构是该胶囊已经包含了大部分的信息,假设要重构的是数字5,那么就把DigitCaps该位置的mask设置为1,其他位置为0,那么实际重构事,就只有这个胶囊的信息参与了运算。
2.6 损失函数Margin loss + recon loss
Margin loss函数:
L c = T c m a x ( 0 , m + − ∣ ∣ v c ∣ ∣ ) 2 + λ ( 1 − T c ) m a x ( 0 , ∣ ∣ v c ∣ ∣ − m − ) 2 L_c = T_c max(0,m^+ - ||v_c ||)^2+ \lambda (1-T_c )max(0,||v_c||-m^- )^2 Lc=Tcmax(0,m+−∣∣vc∣∣)2+λ(1−Tc)max(0,∣∣vc∣∣−m−)2
- c c c:类别
- T c T_c Tc:指示函数(分类c存在为1,否则为0)
- m − m^- m−: ∣ ∣ v c ∣ ∣ ||v_c || ∣∣vc∣∣上边界,避免假阴性,遗漏实际预测到存在的分类的情况
- m + m^+ m+: ∣ ∣ v c ∣ ) ∣ ||v_c |)| ∣∣vc∣)∣下边界,避免假阳性
- margin loss: ∑ c L c \sum_c L_c ∑cLc
重构误差:
- 作用: 正则化
- 重构网络: MLP
- 重构误差计算方式MSE
3. 运行结果
3.1测试集分类结果
论文分类结果:
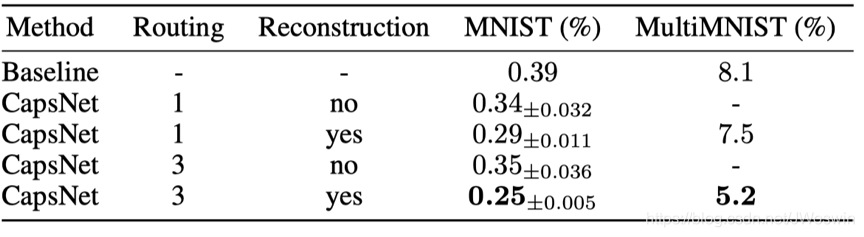
复现
(routing:3,Reconstruction:yes)结果在测试集的准确率平均可达99.24%以上,基本复现成功
3.2 单数字重构效果
论文单数字重构效果:

复现单数字重构效果:
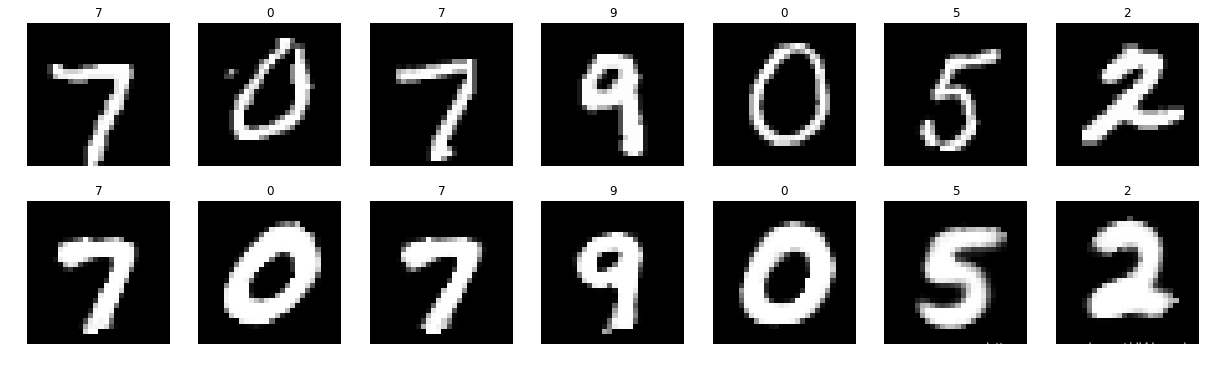
3.3 重叠数字重构效果
论文重叠数字重构效果:

复现重叠数字重构效果:
第一行为实际图片和标签,第二行为预测的图片和标签,第三四行是把第二行两个图片分开的结果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









