







目录
一、背景知识
1.1 投机解码概述
投机解码的核心动机是:在生成任务中,总有简单和复杂的子任务,对于一些较为简单的任务,解码过程存在可以节约资源的环节,使用大模型进行每轮一个token的自回归解码存在资源上的浪费;换句话说,简单的子任务只需要用参数量较小的模型来生成也能取得与使用大模型生成相当的效果,亦或是用大模型在每轮迭代进行多个token的并行解码也依然能保持生成质量。基于此,投机解码采用一种draft-then-verify(起草+验证)的机制来实现这一过程。根据ACL2024的一篇综述[1],现有的投机解码算法可以分为以下两种类型:
1.2 2-models paradigm
该类型的投机解码算法需要两个模型,一个是原始的LLM(称为target model),另一个是结构相似但参数量较小的同类型模型(称为draft model),例如llama-70B和llama-7B就符合这一要求。
该类型的解码先由draft model自回归地生成若干个token,然后将这些token传入target model,target model可以在一次forward中并行地验证这些token,最终接受符合条件的token,从而有望在target model的一次forward中生成多个tokens。(如下图中draft model三次自回归生成3个token,target model用一次forward即可并行验证这些token)。
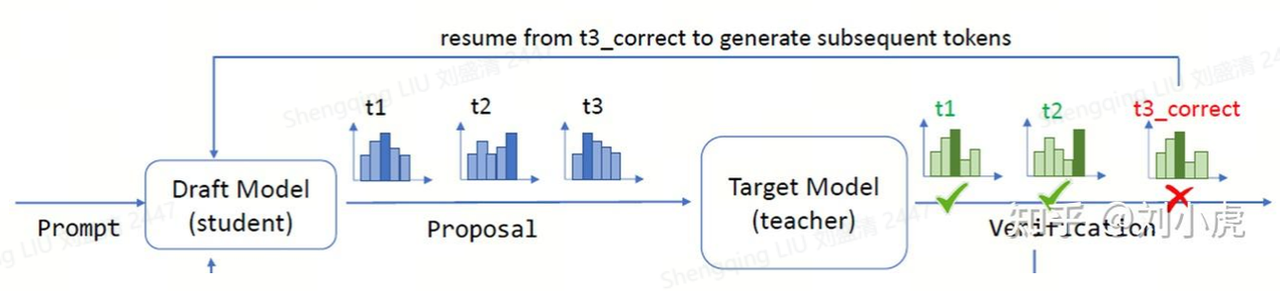
以该图为例,生成2个token的成本=3次draft model的forward+1次target model的forward,而原先使用自回归的成本为2次target model的forward,在draft model的参数量明显小于target model时,推理成本能出现明显的降低。
1.3 1-model paradigm
该类型的投机解码算法只需要一个模型即可(即原始的LLM),该类型的算法通过调整推理架构、添加新的组件、调整算法等方式来充分利用单个模型所具有的能力。
常见的方法有:
-
Post-training:
-
添加多个解码头(Medusa范式):在模型外引入多个解码头实现并行解码,如blockwise decoding,medusa decoding
-
调整模型内部结构:如eagle, early exit等
-
-
Jacobi Decoding范式:借助雅可比迭代的方法实现并行解码,如:original jacobi decoding, lookahead, clms
由于2-models paradigm需要借助两个模型来完成,较为繁琐,为LLM获取一个合适的draft model也是一个巨大的挑战。目前学术界的工作主要是朝着1-model paradigm的方向发展,其实现的难度和耗费的资源都相对较小。
二、2 model投机采样原理
2.1 核心原理阐述
大模型推理自回归采样,逐步串行解码,生成的每个Token都需要将所有参数从存储单元传输到计算单元。因此:内存访问带宽成为重要的瓶颈。这节介绍使用两个模型进行投机采样的原理。该方法的核心思想是使用一个较小的模型(称为草稿模型)来有效地预测多个后续标记,然后使用目标 LLM 并行验证这些预测。该方法旨在使 LLM 能够在单次推理所需的时间范围内生成多个标记。图 16 展示了传统自回归解码方法与推测解码方法的比较。形式上,推测解码方法包含两个步骤:
-
草稿构建:它使用草稿模型以并行或自回归的方式生成多个后续标记,即草稿标记。
-
草稿验证:它使用目标模型在单个 LLM 推理步骤中计算所有草稿 token 的条件概率,然后依次确定每个草稿 token 的接受程度。接受率表示每个推理步骤中接受的草稿 token 的平均数量,是评估该模型的关键指标。
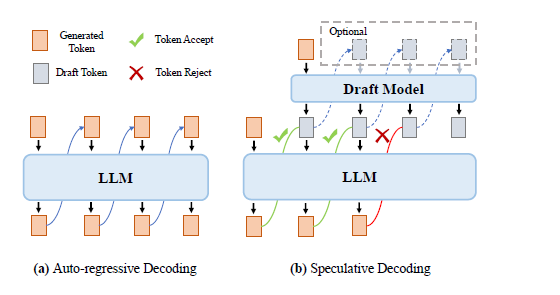
要点总结如下:
-
给定2个生成式模型:目标模型Mp(大模型)和草稿模型(小模型)Mq,它们共享相同的词汇表,但具有不同的参数量P1和P2,模型结构最好一样,保证P1>>P2。
-
在相同的数据上训练,保证Mp和Mq在生成任务上的结果近似。
-
由于参数量的关系,Mp的一次前向推理(即生成一个token)的时间内Mq模型理论上可以生成n个token。
-
所以如果设想,先用小模型进行推理,得到n个token, 那么将n个token 送入大模型中进行一次前向推理验证,按照一定的规则选择接受的token数,那么这样子就会大大的提升推理效率,起到模型加速的效果。
-
Mp 是原始模型,负责生成精确的输出;而 Mq 是一个更为高效的近似模型,用于快速生成候选结果,以便提高整体推理速度。
2.2 推理步骤
2.2.1 自回归推理过程
A. LLM解码时采用的自回归采样,其过程如下:模型使用n个前缀(promt)作为输入,将输出结果处理+归一化成概率分布后,采样生成下一个token。
B. 将生成的token和前缀拼接成新的前缀(n+1),重复执行1步骤,直到生成EOS或者达到最大token数目。
第1步中,将模型输出logits的转换成概率,有几种常用的采样方法,包括argmax、top-k和top-n等。自回归采样中生成的token一个一个地蹦出来,因为每次只对序列长度为1的部分进行有效计算,但是却需要对全部前缀对应位置的activations进行访问,因此计算访存比很低。
2.2.2 投机解码推理过程
公式编辑有点费时,直接将自己写好文档中的给个截图,不想二次编辑了。

需要注意的是,论文中并不限概率 p(x)、q(x) 的形式,默认基于标准的nucleus sampling,但可以扩展到更特殊的sampling包括argmax, top-k等。
nucleus sampling是指一种从语言模型中生成文本的解码策略。具体来说,它通过设置一个概率阈值p,从解码词中挑选出一个累积概率大于p的最小集合。在不同的时间步,随着解码词概率分布的不同,候选词集合的大小会动态变化,这使得生成的文本在保持通顺的同时更加多样化。与固定窗口大小的top-k sampling不同,nucleus sampling的候选词集合大小是根据当前时间步的词汇概率动态调整的,因此能够更好地适应模型的置信度区域变化。
下面是论文中的伪代码:

2.3 示例展示和加速效果
看下论文中的示例:

绿色:目标模型接受了的近似模型给出的token。
红色:目标模型拒绝了近似模型给的token
蓝色:目标模型给出的本次推理中的它推理得到的token.
-
在第一行中,近似模型生成了5个token,目标模型使用这5个token和前缀拼接后的句子”[START] japan’s bechmark bond”作为输入,通过一次推理执行来验证小模型的生成效果。
-
这里,最后一个token ”bond“被目标模型拒绝,重新采样生成”n“。这样中间的四个tokens,”japan” “’s” “benchmark”都是小模型生成的。
-
以此类推,由于用大模型对输入序列并行地执行,大模型只forward了9次,就生成了37个tokens。尽管总的大模型的计算量不变,但是大模型推理一个1个token和5个token延迟类似,这还是比大模型一个一个蹦词的速度要快很多。

这个展示了近似模型每一次输出3个和7个token, 然后和prefix 一起拼接送到大模型进行推理的耗时比较,可以看到和只使用大模型推理相比,加速的效果还是非常明显的。
2.4 结果分析
-
最好的情况
-
小模型生成的n个token和大模型都是一致的。
-
那么小模型推理n次,大模型推理一次,就有n+1个可用的token。
-
结果:节省了n次大模型的推理
-
-
相对差的情况
-
小模型生成的n个token和大模型都不是一致的,也就是拒绝接受小模型给出的输出。
-
那么小模型推理n次,大模型推理一次,只有1个可用的token。
-
结果:,因为小模型的推理耗时和大模型比,可以近似的忽略,所以基本可以认为和原始推理性能相当
-
-
结论:
-
投机采样完全不影响大模型的实际输出结果(推理精度)。也就是这样子的接受和修正逻辑可以保证speculative decoding的采样过程与原始target model自回归采样过程等价,从理论上保证了推理过程不影响效果。
-
在小模型足够近似的情况下,可以大幅度的提升推理性能。
-
2.5 算法的收益评估
2.5.1 平均被接受的token数
-
定义 acceptance rate βx<t:给定 prefix x<t,根据投机采样 逻辑接受 xt∼q(xt∣x<t) 的概率
-
假设不同的 prefix 间是相互独立的,则平均的接受率 α=E(β) 可以作为衡量 speculative decoding 的定量指标:α 越大说明 speculative decoding 的效果越接近原始的自回归采样,也可以说近似模型和目标模型的概率分布越接近。
β、α 与 Draft Model 和 Target Model 分布的关系:定义 Draft Model 和 Target Model 分布的差异 D_LK 如下:
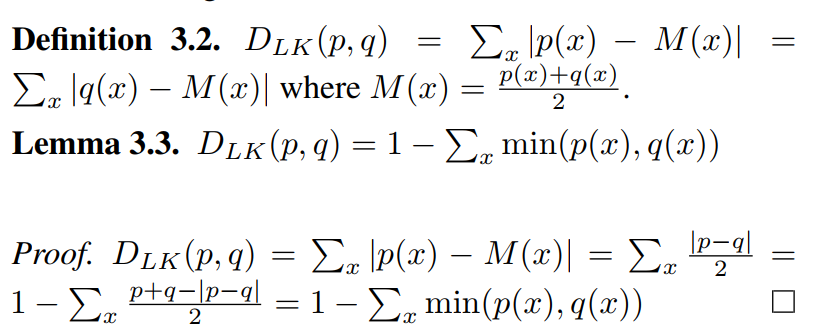
-
当 p(x) 和 q(x) 的分布完全一致时, D_{LK}(p,q) =0;当它们完全不相同时, D_{LK}(p,q)=1。因此 D_{LK}可以作为衡量 Draft Model 和 Target Model 分布差异程度的指标。
-
D_{LK} 是 Draft Model 和 Target Model 分布的差异,用于衡量两个模型之间的分布差异程度。通过 β、α 和C之间的关系,可以更好地理解和优化投机解码的性能。
speculative decoding平均被接受的token数:
与接受率 α 和draft model一次生成的总token数 λ 有关, 公式如下:
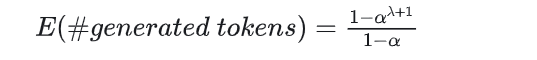
论文中给出的α (两个模型的相似度)和近似模型每一次输出Y个的token给到大模型的平均接受token的关系图:
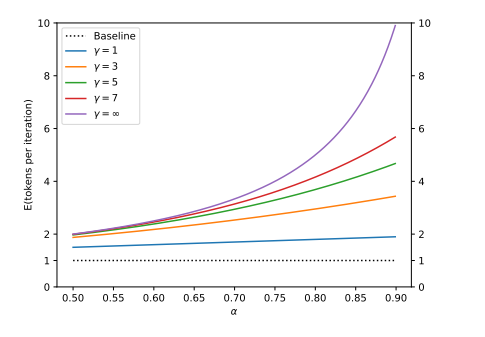
-
α 给定,那么近似模型每一次输出Y个的token越多,平均接受的词也就越多。
-
Y给定的时,α 越大,也就是模型越相似,平均接受的词也就越多。
-
理论上来说,α越接近1,γ值越大,则推测解码的加速效果越好。
2.5.2 加速比因子
c的作用:参数c代表了在运行近似模型Mq一次所需的时间与运行目标模型Mp一次所需的时间之间的比率。换句话说,它表示了Mq相对于Mp的计算成本。如果c很低,意味着近似模型Mq的计算成本非常低,而如果c很高,则表示Mq的计算成本相对较高, 加速系数计算公式:
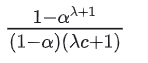
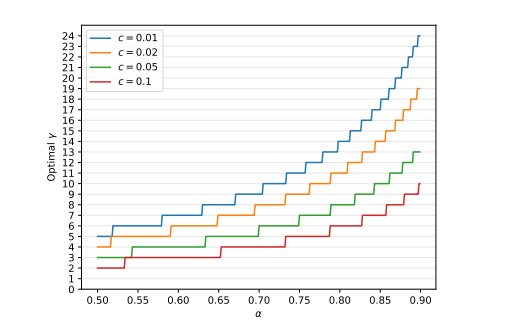
1:α 给定, 模型相似程度一致的情况下, 那么耗时因子C 越小,可以得到的推理加速的效果也就可以越大。
2:成本系数固定,模型越相似,近似模型输出的token 越容易被接收,那么加速效果也越明显。
大神的代码工程实现:https://github.com/feifeibear/LLMSpeculativeSampling
2.6 算法改进与技术演进
从上文分析,个人认为核心在于怎么进一步提升接受率α。更具体地,提升draft model和target model预测分布的一致性 (Alignment) 从而提升接受率 α。总结概述为如下几点:
-
最常见的做法是采用同一系列的模型,使用较小参数量的版本作为较大参数量版本的draft model,但这种方式有一定的局限性,最直接的就是当target model经过垂域SFT时,想获得更好的分布一致性则需要draft model也进行SFT,带来额外的工作量,而且接受率也受限,由此产生后续一系列的改进工作
-
通过distillation提升draft model与target model一致性:参考论文[4]及[3]中的总结,作者分析对比了不同的KD方案,最优的蒸馏方法很大程度上取决于任务和 Decoding Strategy
-
Tree-based speculative decoding:类似集成学习,同时使用多个draft model的结果提升接受率(论文claim对于stochastic decoding可以从52-57% 提升至96-97%),并提出了tree-based speculative decoding解决target model如何同时验证多个draft model的结果 [5], 论文[5]也提出了collectively boost-tuning,用adaptive boosting的方式,每次只训练一个 draft model (论文中称之为SSM),当 SSM 训练完成后,将训练集中这个SSM 的输出与 LLM 输出一致的那些训练数据删去,并用剩下的训练集继续训练下一个 SSM。这样,多个 SSM 的输出可以尽可能地覆盖到 LLM 可能的输出 (参考笔记[3]的总结)
-
Self-drafting:单独的draft model需要额外的微调或者维护,加速比也受限于draft model本身capacity的上限导致的接受率的上限。一种避免单独维护draft model的思路是使用target model本身作为draft model,同时必须保证draft model一次输出多个预测token提供给target model验证,已知不同的实现方案:
-
Multi-Token Prediction Heads: 参考Medusa [6],target model最后一层加了若干个token prediction head (Medusa Head)作为draft model,第 i个 Medusa Head 负责预测当前预测 token 之后的第 i个token,每个 head 取 top-k 的预测构造token tree
-
Lookahead Decoding:参考论文[8],基于LLM也可以一次生成n-gram结果的特点,利用target model生成的n-gram作为draft model实现parallel decoding,底层原理基于Jacobi Decoding
-
speculative decoding的致命缺点就是要维持一个Draft model,而且在有限的计算资源里需加载2个LLM模型,代价有点大!
三、资料引用
[1] Speculative Decoding 综述:https://arxiv.org/pdf/2401.07851
[2]Speculative Decoding: https://arxiv.org/pdf/2211.17192
[3]https://arxiv.org/pdf/2305.09781
[4] DistillSpec: Improving Speculative Decoding via Knowledge Distillation
[5] SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification, https://arxiv.org/abs/2305.09781
[6] MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads, https://arxiv.org/abs/2401.10774
[7] EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty, https://arxiv.org/abs/2401.15077
[8] Breaking the Sequential Dependency of LLM Inference Using Lookahead Decoding, [9]https://arxiv.org/abs/2402.0205
[10]https://proceedings.neurips.cc/paper/2018/file/c4127b9194fe8562c64dc0f5bf2c93bc-Paper.pdf
https://github.com/FasterDecoding/Medusa
https://sites.google.com/view/medusa-llm
https://zhuanlan.zhihu.com/p/690504053
https://zhuanlan.zhihu.com/p/656374338

















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









