






投机解码
投机解码(speculative decoding)最早在[1,2]中被提出。其方法可以概括为由一个小模型一次猜一批可能的结果,再由大模型并行地验证这些结果是否要接受。 投机解码算法的提出,主要源于两点观察:
- 和early exit的想法类似,在一些相对简单的问题下,我们可以用小模型(或者大模型的前面几层)的输出得到很好的结果。 如果我们用小模型去回答这些简单的问题,在遇到难题的情况下再调用大模型,就可以整体的生成效率。
- 大模型在做推理任务的时候,一次只能生成一个token,无法并行计算。如果我们能让大模型一次处理一批tokens,就能利用上算例的并行能力。(大模型推理的时候batch size往往为1)
投机解码利用了上面两个观察,先用小模型猜后续的若干个tokens,如果当前的问题比较简单,则小模型有更大的可能猜对多个token。 然后再用大模型并行的验证这一些token是否符合大模型的输出。由于现代计算机的并行能力,我们可以近似的认为大模型处理一个token和处理w个token的用时是几乎一样的。 假设我们一次猜n个tokens,平均有m个token会被最终接收,那么在这个过程中: 我们调用了n次小模型D,1次大模型T,生成了m个token,平均每个token的用时为
(
n
D
+
T
)
/
m
(nD+T)/m
(nD+T)/m。只要nD显著地小于(m-1)T,就能实现很好的加速效果。

对于大模型来说,decoding的时候有几种方案:
- Greedy:每次选择logit最大的token
- 归一化logits后按照分布采样
- Top k: 保留最大的k个token
- Top p: 从大到小保留概率分布和为p的token
- (top k/top p)+(greedy/sampling)
投机是一个加速推理的技术,为了保证这样得到的结果performance不下降,这一系列工作认为只要保证最后的概率分布一样即可。因此,只需要大模型验证的方法能保证整个过程输出的结果的概率分布不变。
具体的验证方法如下图伪代码所示。验证操作弥补了小模型和大模型之间的概率分布的gap,思路是对于小模型的每一次猜测,根据大模型和小模型的概率分布去判断这一次猜测有多大概率是正确的。相当于是从小模型的采样到大模型的采样之间做了一个映射,可以把小模型和大模型的概率分别看成若干个随机事件,然后将小模型的随机事件和大模型的随机时间做映射,如果两边的随机事件的结果一致,我们就认为这个猜测是正确的。下图的做法可以理解成是最大化猜测正确概率的一个映射。特别地,如果两个概率分布一样,则猜测正确的概率为1。
如果在某一部中我们认为小模型的猜测是错误的,那么后面的结果都是无效的。此时用大模型最后一步得到的概率分布做一个采样后退出。这一步既是保证输出同分布必须的,又可以保证每次至少输出一个token。

在投机解码算法中,比较重要的指标是每一步猜中的概率(大约等于前文的m/n)。假设每一次猜测互相独立,每一步猜中的概率为 β \beta β, 猜 γ \gamma γ次,则期望的接受token数为 β + β 2 + . . . + β γ + 1 = 1 − β γ + 1 1 − β \beta + \beta^2 + ... + \beta^\gamma + 1 = \frac{1-\beta^{\gamma+1}}{1-\beta} β+β2+...+βγ+1=1−β1−βγ+1(最后一个1是最后一次sample得到的token)
Tree decoding
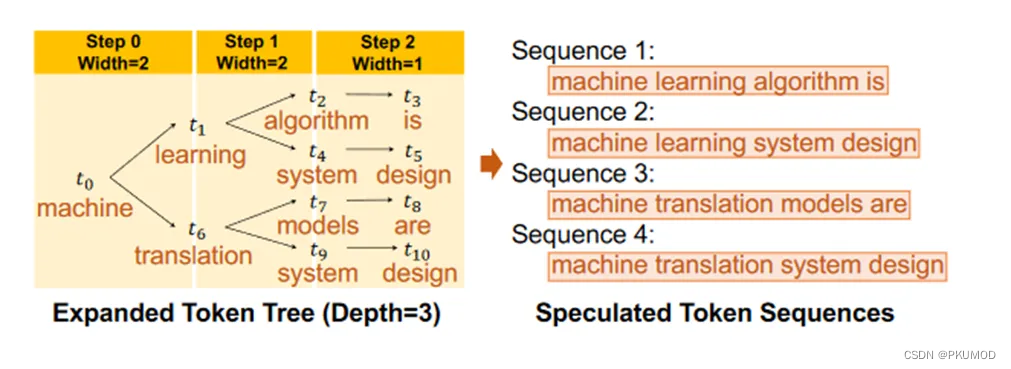
在投机解码的基础上,一些工作发现一次预测一条链的话,概率衰减的非常快(假设独立,则第 γ \gamma γ个token的期望接受率为 β γ \beta^\gamma βγ),所以不能预测很长的链,导致不能充分利用上大模型验证的并行度。为了提高 β \beta β,一个思路是每一次不止猜一个token,而是猜多个token。SpecTr[3]提出了一次预测k个sequence,并提出了与之相对应的sampling方法。
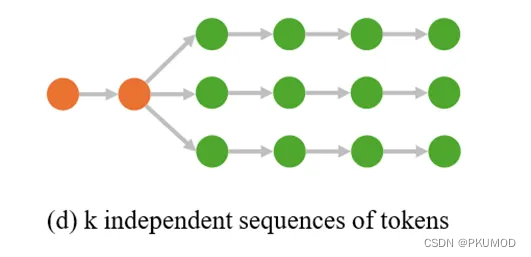
更进一步地,不止在第一步猜k个token,我们可以在每一步都猜多个tokens,这样每一步的 β \beta β都会变大。只要由此带来的额外的计算开销小于更高的 β \beta β带来的加速,那么猜更多的token就是可以接受的。SpecInfer[4]提出了一个树结构的decoding方案。这个工作用一个可学习的方案来决定每一层的width。此外,SpecInfer还用多个不同的小模型来猜下一步的token。 这一步设计的出发点是如果一个小模型的概率分布和大模型差的很多,会导致 β \beta β的值很小。如果我们选择多个不同的小模型,那么他们的概率分布的和就更可能覆盖大模型的概率分布,使得 β \beta β不会特别低。
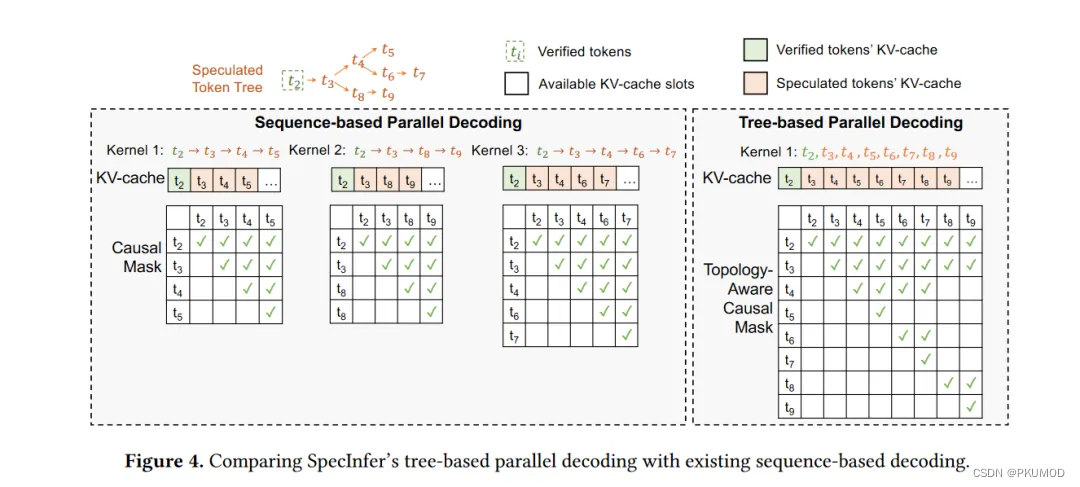
树结构会带来token之间复杂的依赖关系,对于transformer-base的模型来说很难处理这样的情况。如果对树上的每一个从root到leaf的路径都用大模型做一次验证,即使使用key-value cache,大量的叶子节点也会导致算法退化到最原始的一次预测一个token的场景。针对这个情况SpecInfer提出了tree attention来加速decoding的速度。方法是将树上的祖先关系变成attention-mask的可见关系。
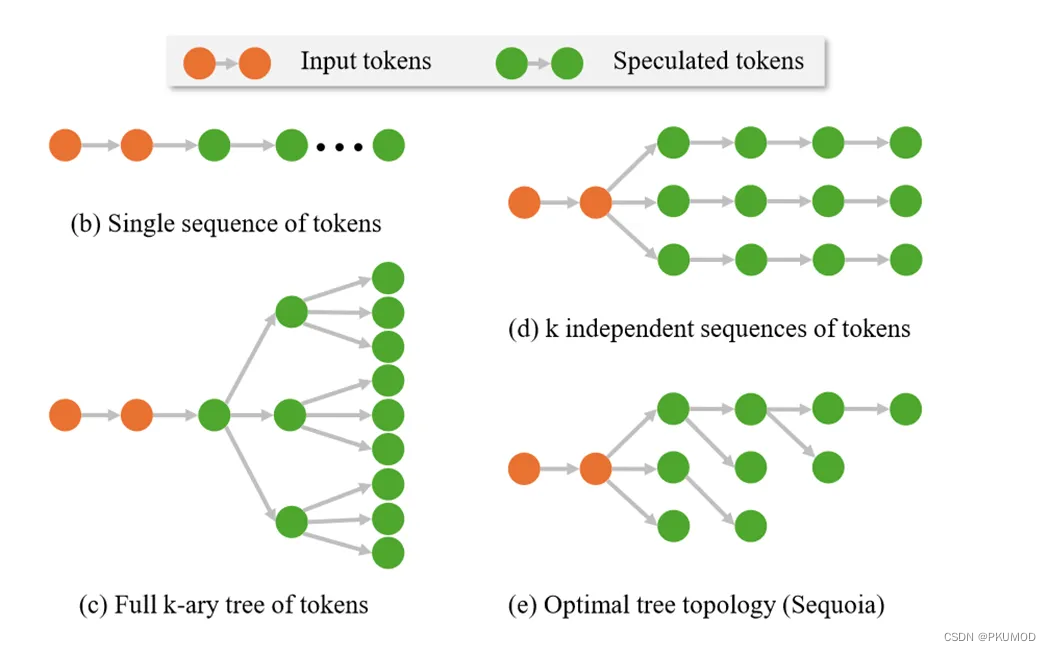
在上述方法的基础上。Sequoia提出了一种动态规划的方法来得到解码树结构的树结构。这个方法假设每一次的期望接受率是独立同分布的,这样就可以先通过一部分数据算出一个平均的接受率,然后基于这个接受率,使用动态规划的方法计算出最优的解码树结构。这个方法基于小规模数据的模拟结果得到估计概率,而这个模拟无法模拟出所有情况,因为每一层有vocabsize个分支,随着层数的增加处理的空间会指数级增长。 因此Sequoia利用硬件的一些指标限制了动态规划的空间(即限制了每一层的宽度和整体的深度)。
[1] Chen, Charlie, et al. “Accelerating large language model decoding with speculative sampling.” arXiv preprint arXiv:2302.01318 (2023).
[2] Leviathan, Yaniv, Matan Kalman, and Yossi Matias. “Fast inference from transformers via speculative decoding.” International Conference on Machine Learning. PMLR, 2023.
[3] Sun, Ziteng, et al. “Spectr: Fast speculative decoding via optimal transport.” Advances in Neural Information Processing Systems 36 (2024).
[4] Miao, Xupeng, et al. “Specinfer: Accelerating generative llm serving with speculative inference and token tree verification.” arXiv preprint arXiv:2305.09781 (2023).
[5] Chen, Zhuoming, et al. “Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding.” arXiv preprint arXiv:2402.12374 (2024).

















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









