 FlashAttention算法原理及优化分析
FlashAttention算法原理及优化分析





一、FlashAttention的概述
FlashAttention是一种IO感知精确注意力算法。通过感知显存读取/写入,FlashAttention的运行速度比PyTorch标准Attention快了2-4倍,所需内存也仅是其5%-20%。随着Transformer变得越来越大、越来越深,但它在长序列上仍然处理的很慢、且耗费内存。(自注意力时间和显存复杂度与序列长度成二次方),现有近似注意力方法,在试图通过去牺牲模型质量,以降低计算复杂度来解决该问题。但存在一定的局限性,即不能提升运行时的训练速度。
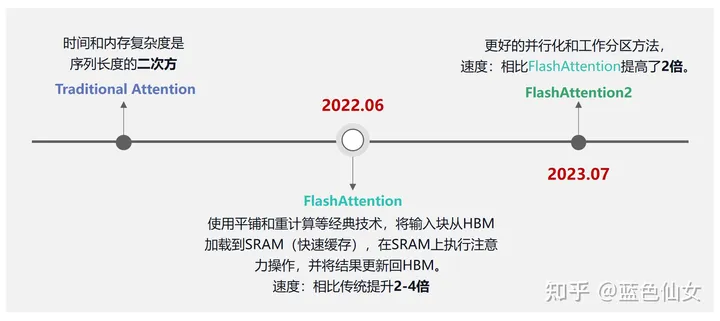
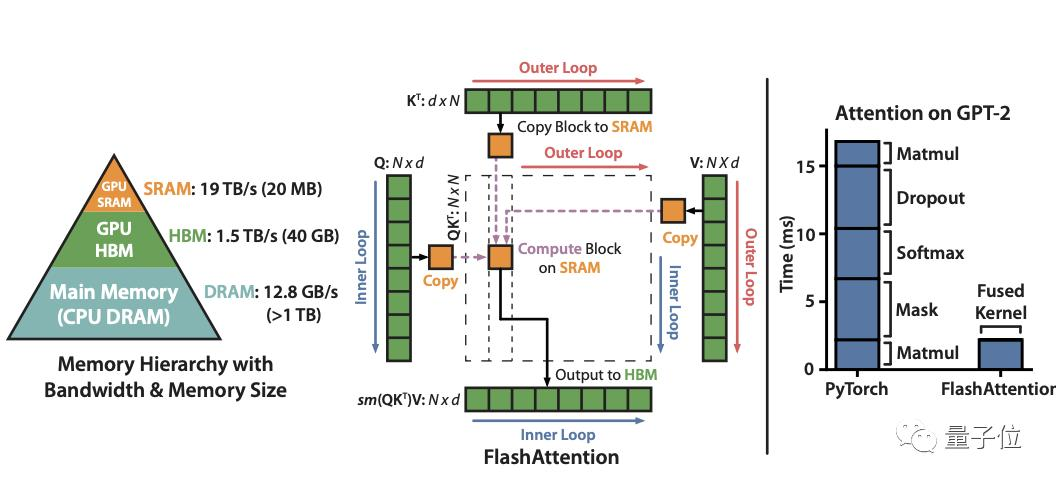
基于这样子背景,研究人员觉得应该让注意力算法具有IO感知,即考虑显存级间的读写,比如大但慢的HBM(High Bandwidth Memory)技术与小但快的SRAM。基于这样的背景,研究人员提出了FlashAttention,具体有两种加速技术:
Flash Attention主要运用了两种技术:分块和算子融合计算。
-
分块即将输入划分成块,并单独处理每个块的注意力;
-
算子融合,将多个算子融合成一个算子,将所有注意力操作融合到CUDA内核中。
在深度学习中,Attention Mechanism(注意力机制)用于在序列数据中学习不同位置的重要性权重,以便更好地捕捉序列中的关键信息。Attention Scores(注意力分数)是用来计算这些权重的指标。以下是关于计算Attention Scores的推导过程的文档:
二、FlashAttention v1具体原理的探究
先上经典的示意图
2.1 注意力机制快速了解
在注意力机制中,Q(Query)、K(Key)、V(Value)和softmax函数是核心概念,用于计算注意力权重并生成输出表示。
Query(查询)、Key(键)、Value(值)
-
Query Q(查询):查询是用来寻找与之相关性的键的向量。在注意力机制中,查询向量Q通常是通过对输入数据进行线性变换得到的,用于衡量查询与键的相似度,决定了在生成输出表示时每个键的重要程度。
-
Key K(键):键是用来表示输入数据的向量,与查询一起计算注意力权重。键向量K也是通过对输入数据进行线性变换得到的。
-
Value V(值):值是用来生成最终输出表示的向量。值向量V同样是通过对输入数据进行线性变换得到的,根据注意力权重对值进行加权求和得到最终输出。
Softmax函数
Softmax函数是一个常用的激活函数,通常用于多分类问题中,将输入转化为概率分布。在注意力机制中,softmax函数被用来计算注意力权重,将注意力分数转化为概率分布,使得不同位置的输入在生成输出时得到不同的权重。

标准的Attention实现算法如下。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5671
5671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









