








🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月25日14点24分
神秘男子影,
秘而不宣藏。
泣意深不见,
男子自持重,
子夜独自沉。
StyleShot: 任意风格的快照
风格迁移是计算机视觉和图像处理领域中的一项重要任务,它涉及到将一张图像(参考图像)的风格应用到另一张图像(内容图像)上。这项技术在艺术创作、设计、娱乐和多个实际应用中都有广泛的应用。随着深度学习技术的发展,特别是生成对抗网络(GANs)和扩散模型的出现,风格迁移的研究得到了显著的推动。这些模型能够生成高质量和多样化的图像,为风格迁移任务提供了新的解决方案。
StyleShot是一种创新的图像风格迁移技术,它允许用户将任意图像的风格应用到另一张图像上。这项技术的背景建立在深度学习和生成模型的快速发展之上,尤其是在文本到图像生成领域。随着扩散模型的引入,图像生成的质量得到了显著提升。
1. 概述
本文通过复现并解读图像风格迁移领域最新的SOTA方法,来解读基于深度学习的图像风格迁移领域的最新研究进展。本文解读的论文是《StyleShot: A Snapshot on Any Style》,作者来自同济大学和上海人工智能实验室。

论文强调了良好的风格表示对于无需测试时调整的风格迁移至关重要且足够,通过构建一个风格感知编码器(style-aware encoder)和有序的风格数据集(StyleGallery),实现了风格迁移。StyleShot方法简单有效,能够模仿各种所需的风格,如3D、平面、抽象甚至细粒度风格。通过大量实验验证,StyleShot在多种风格上的性能优于现有方法。
2. 背景及意义
图像风格迁移的目标是将参考图像的风格应用到内容图像上,使得生成的图像既保持内容的一致性又展现出目标风格。这一部分主要分为两个研究方向:
- 基于GAN和AutoEncoder的方法:早期的风格迁移工作主要基于生成对抗网络(GAN)或自动编码器(AutoEncoder),这些方法通常需要成对的训练数据,并且是在监督学习的情况下进行的。
- 利用预训练CNN模型的方法:另一种研究方向是利用预训练的卷积神经网络(CNN)来识别不同层次的风格特征,这些方法通常在无监督的情况下进行,能够在未配对的数据上实现风格转换。
此外,还有一些方法通过调整模型权重或嵌入来实现风格迁移,这些方法在测试时需要对特定风格进行调整,这导致了计算和存储成本较高。
尽管现有的风格迁移技术取得了一定的进展,但仍面临一些挑战:
- 风格表示的局限性:现有的方法通常难以充分表示和迁移复杂的风格特征,如颜色、纹理、光照和布局等。
- 测试时调整的高成本:一些方法需要在测试时对模型进行调整,这导致了高计算和存储成本,限制了它们在实际应用中的可行性。
- 风格泛化能力:现有方法通常在特定风格上表现良好,但对于未见过的风格或细粒度风格,其泛化能力有限。
针对这些挑战,作者提出了StyleShot方法,旨在通过专门设计的风格感知编码器和内容融合编码器,以及一个风格平衡的数据集,来提高风格迁移的性能和泛化能力,同时避免了测试时调整的需要。
3. 模型结构
StyleShot的架构和关键组件包括风格感知编码器(Style-Aware Encoder)、内容融合编码器(Content-Fusion Encoder)以及风格平衡数据集StyleGallery的构建和去风格化(De-stylization)策略。
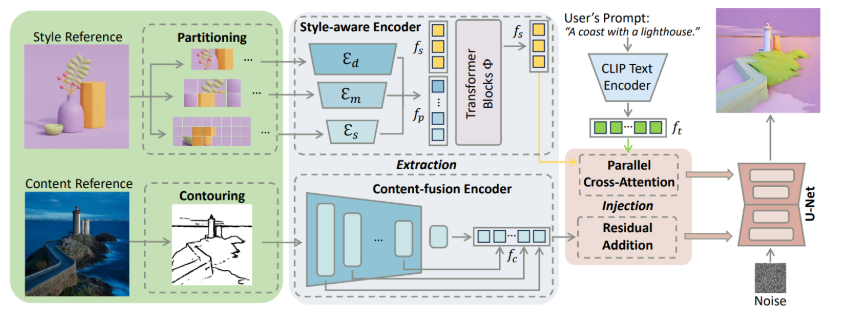
3.1 预备知识

3.2 风格感知编码器
在训练一个大规模数据集上的风格迁移模型时,每个图像都被视为一种独特的风格。先前的方法通常使用CLIP图像编码器来提取风格特征。
然而,CLIP更擅长于表示与图像的语言相关性,而不是模拟图像风格,这包括了像颜色、素描和布局这样的方面,这些风格特征难以通过语言表达,限制了CLIP编码器捕捉相关风格特征的能力。
因此,作者提出了一个风格感知编码器,专门设计用于提取丰富和富有表现力的风格嵌入。
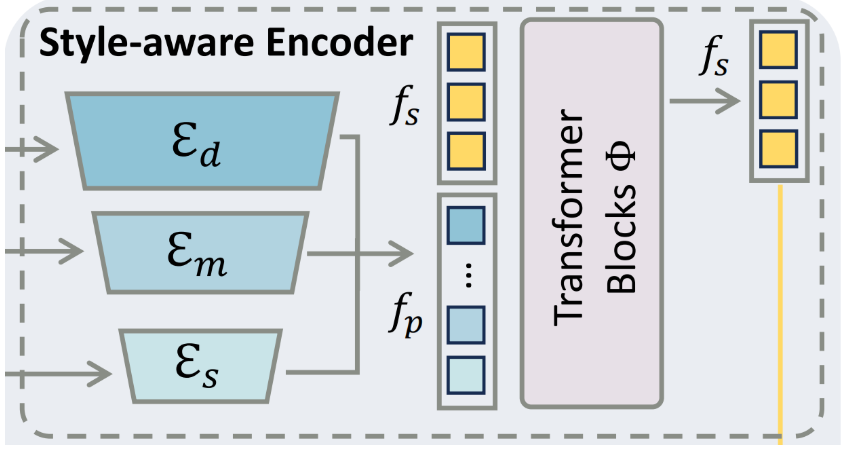
风格提取
- 多尺度补丁分割:与CLIP图像编码器不同,风格感知编码器采用多尺度补丁分割方案,处理参考图像为不同大小的非相邻补丁(1/4、1/8和1/16图像长度),并使用不同深度的ResBlocks来提取多层次的风格特征。
- 混合专家(MoE)结构:通过轻量级块为不同大小的补丁提取多级补丁嵌入,然后将这些多级补丁嵌入输入到一系列的Transformer Blocks中,以进一步学习风格特征。
风格注入
- 并行交叉注意力模块:借鉴IP-Adapter的思想,通过独立的映射函数将风格嵌入投影到关键和值上,然后与潜在嵌入进行交叉注意力计算,将风格嵌入注入到预训练的Stable Diffusion模型中。
3.3 内容融合编码器
在实际应用场景中,用户会提供文本提示或图像以及一个风格参考图像,分别用来控制生成的内容和风格。先前的方法通常通过操作内容图像特征来转移风格。
然而,内容特征与风格信息是耦合的,导致生成的图像保留了内容的原始风格。这一限制阻碍了这些方法在复杂风格迁移任务中的性能。与此不同,论文通过在原始图像空间中消除风格信息,预先解耦内容信息,然后引入一个专门设计用于内容和风格整合的内容融合编码器。
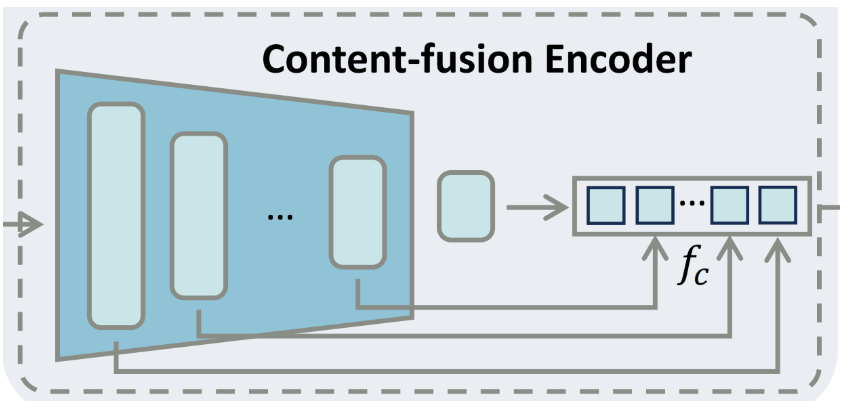
这种方法的核心在于,它允许模型在不依赖于内容原始风格特征的情况下,更灵活地应用和融合不同的风格特征。通过这种方式,可以更准确地控制生成图像的风格,同时保持内容的一致性和完整性。这种预解耦和融合策略使得StyleShot能够在各种风格迁移任务中实现更高质量的结果,无论是在文本驱动的风格迁移还是图像驱动的风格迁移中。
内容提取
- 去风格化:使用HED检测器进行轮廓检测,以及阈值和膨胀操作,从参考图像中移除风格,只保留必要的内容结构。
内容注入
- 残差添加:类似于ControlNet,内容融合编码器将内容嵌入策略性地整合到主要的U-Net中,以促进内容和风格的融合。
两阶段训练策略
- 第一阶段:先训练风格感知编码器和相应的交叉注意力模块,不包括内容组件。
- 第二阶段:在冻结风格感知编码器的情况下,单独训练内容融合编码器。
3.4 StyleGallery & 去风格化
StyleGallery
- 构建风格平衡的数据集:为了训练风格感知编码器,作者构建了一个包含多样化风格图像的数据集StyleGallery,该数据集从多个公开可用的数据集中选取图像,并确保风格分布更加平衡和多样化。
去风格化
- 解耦风格和内容:为了避免文本提示中的风格描述与参考图像中的风格信息相互纠缠,作者从StyleGallery中的所有文本图像对中移除了与风格相关的描述,仅保留与内容相关的文本。
4. 部署方式
GPU 4090D
Ubuntu 20.04
PyTorch 2.0.1
Python 3.8
Cuda 11.3
以基于风格图像驱动的图像风格迁移为例,部分关键代码实现如下:
import os
from types import MethodType
# 导入torch库,用于深度学习模型
import torch
# 导入OpenCV库,用于图像处理
import cv2
# 从annotator模块导入SOFT_HEDdetector,用于边缘检测
from annotator.hed import SOFT_HEDdetector
# 从annotator.lineart导入LineartDetector,用于线性艺术风格检测
from annotator.lineart import LineartDetector
# 从diffusers导入UNet2DConditionModel,用于条件UNet2D模型
from diffusers import UNet2DConditionModel, ControlNetModel
# 从transformers库导入CLIPVisionModelWithProjection,用于视觉模型
from transformers import CLIPVisionModelWithProjection
# 从PIL库导入Image,用于图像处理
from PIL import Image
# 从huggingface_hub导入snapshot_download,用于下载预训练模型
from huggingface_hub import snapshot_download
# 从ip_adapter导入StyleShot和StyleContentStableDiffusionControlNetPipeline,用于风格迁移
from ip_adapter import StyleShot, StyleContentStableDiffusionControlNetPipeline
# 导入argparse库,用于解析命令行参数
import argparse
def main(args):
# 设置基础模型路径和transformer块路径
base_model_path = "runwayml/stable-diffusion-v1-5"
transformer_block_path = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
# 设置设备为cuda,即GPU
device = "cuda"
# 根据命令行参数选择预处理器
if args.preprocessor == "Lineart":
detector = LineartDetector()
styleshot_model_path = "Gaojunyao/StyleShot_lineart"
elif args.preprocessor == "Contour":
detector = SOFT_HEDdetector()
styleshot_model_path = "Gaojunyao/StyleShot"
else:
raise ValueError("Invalid preprocessor")
# 如果模型路径不存在,则下载模型
if not os.path.isdir(styleshot_model_path):
styleshot_model_path = snapshot_download(styleshot_model_path, local_dir=styleshot_model_path)
print(f"Downloaded model to {styleshot_model_path}")
# 下载基础模型和transformer块
# weights for ip-adapter and our content-fusion encoder
if not os.path.isdir(base_model_path):
base_model_path = snapshot_download(base_model_path, local_dir=base_model_path)
print(f"Downloaded model to {base_model_path}")
if not os.path.isdir(transformer_block_path):
transformer_block_path = snapshot_download(transformer_block_path, local_dir=transformer_block_path)
print(f"Downloaded model to {transformer_block_path}")
# 设置模型权重路径
ip_ckpt = os.path.join(styleshot_model_path, "pretrained_weight/ip.bin")
style_aware_encoder_path = os.path.join(styleshot_model_path, "pretrained_weight/style_aware_encoder.bin")
# 初始化UNet2D模型和内容融合编码器
unet = UNet2DConditionModel.from_pretrained(base_model_path, subfolder="unet")
content_fusion_encoder = ControlNetModel.from_unet(unet)
# 从预训练模型创建管道
pipe = StyleContentStableDiffusionControlNetPipeline.from_pretrained(base_model_path, controlnet=content_fusion_encoder)
styleshot = StyleShot(device, pipe, ip_ckpt, style_aware_encoder_path, transformer_block_path)
# 打开风格图像
style_image = Image.open(args.style)
# 处理内容图像
content_image = cv2.imread(args.content)
content_image = cv2.cvtColor(content_image, cv2.COLOR_BGR2RGB)
content_image = detector(content_image)
content_image = Image.fromarray(content_image)
# 生成图像
generation = styleshot.generate(style_image=style_image, prompt=[[args.prompt]], content_image=content_image)
# 保存生成的图像
generation[0][0].save(args.output)
if __name__ == "__main__":
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument("--style", type=str, default="style.png")
parser.add_argument("--content", type=str, default="content.png")
parser.add_argument("--preprocessor", type=str, default="Contour", choices=["Contour", "Lineart"])
parser.add_argument("--prompt", type=str, default="text prompt")
parser.add_argument("--output", type=str, default="output.png")
args = parser.parse_args()
main(args)5. 实验结果
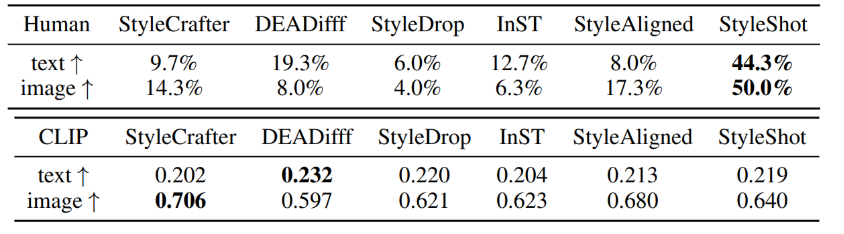
StyleShot是目前图像风格迁移领域的SOTA方法。
下面我们以基于风格图像驱动的图像风格迁移为例,我们将下面的图片作为内容图像进行实验:

将下面三张图片作为风格图像与内容图像融合:

得到了下面的结果:

可以看到,模型取得了非常好的融合效果,既保留了内容图像的特征,又完美融合了风格图像的特点。
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











