







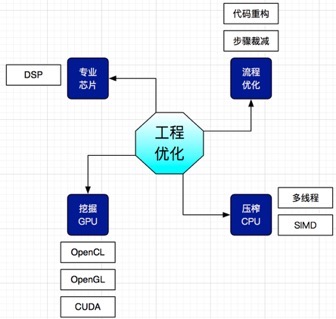
图像算法的工程优化技术
当一个很酷的图像算法实现之后,我们希望集成到软件中去,这时将会遇到最大的拦路虎:性能。
可以想像一下,如果美图秀秀做一个美颜效果要转圈圈转个30秒,还会有多少人用呢。
学术界喜欢推出复杂度更低的算法,去解决性能问题,而在实际工程应用中,对代码的优化和硬件的良好运用效果来得更快更显著,这里就对不改动算法,纯工程方面做性能优化的技术作一个简介。
流程优化——节能减排
对初始的算法代码进行优化,减少不必要的计算步骤,合理安排循环位置,减少过度的函数调用,尽可能保证内存访问连续等等,统称流程优化。
普适性:5
这个一般是进行工程性优化的第一步骤,即使找不到可优化的流程,也要分析出来性能瓶颈来,可以在什么地方进一步优化。
有效性:2
原来的代码写得越差,优化余地越大,但如果在一开始算法代码就是由资深软件工程师写的,就基本上没有什么优化余地了。
易用性:5
经验丰富的程序员,对慢代码有天然的敏感,并能够改造它,而资历尚浅的程序员,尽管看不出来代码的好坏,也可以去发现性能瓶颈。
图像反色的代码示例:
/*优化前代码*/
void reverse(Bitmap* src)
{
for (int y=0; y<src->height(); ++y)
{
for (int x=0; x<src->width(); ++x)
{
/*每个像素都调函数,编译器无法优化*/
Color c = src->getColor(x, y);
c.r = 0xFF - c.r;
c.g = 0xFF - c.g;
c.b = 0xFF - c.b;
src->setColor(c, x, y);
}
}
}/*优化后代码*/
/*针对RGBA格式的图像*/
void reverse(Bitmap* src)
{
int h = src->height();
int w = src->width();
const int bpp = 4;//每个像素所占字节
for (int y=0; y<h; ++y)
{
unsigned char* linePixels = src->getAddr(0, y);
for (int x=0; x<w; ++x)
{
/*不用在意这边的乘法,相对于读写内存几乎可以忽略*/
linePixels[bpp*x] = 0xFF - linePixels[bpp*x];
linePixels[bpp*x+1] = 0xFF - linePixels[bpp*x+1];
linePixels[bpp*x+2] = 0xFF - linePixels[bpp*x+2];
}
}
}SIMD与多线程——压榨CPU
中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的性能好坏是决定机器快慢的最重要因素。
在摩尔定律渐渐失效的今天,CPU厂商不断往多核和强化SIMD指令集去努力。这就要求图像算法的优化人员对多线程和SIMD技术有所了解,压榨CPU的能力。
SIMD技术
SIMD即Single Instruction Multiple Data,单指令多数据流,是CPU中能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。在图形图像算法中使用SIMD技术,可以一次性计算多个像素,从而提高性能。
主流CPU架构及对应的SIMD指令集名称如下图:
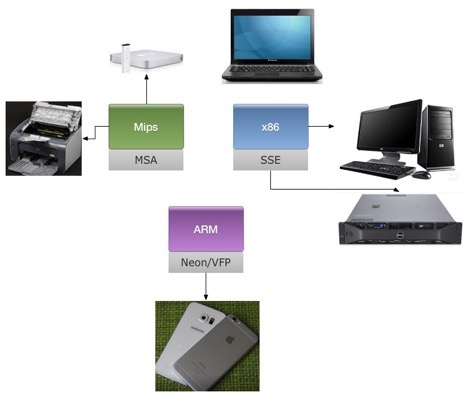
现在是移动互联网时代,绝大部分情况下我们都在优化移动端(手机App)的代码,而移动端主流的CPU架构是ARM架构。NEON技术是适用于ARM Cortex-A系列处理器的一种128位SIMD扩展结构。因此,一般而言我们在做SIMD优化时,都是在做Neon优化。
普适性:4
只要是支持SIMD指令集的CPU,系统开发者和第三方开发者都能使用。主流的CPU架构(ARM、x86、mips)都支持,仅在少数低端设备上会应用不了。
进行SIMD优化需要算法本身有一定的可并行性。
有效性:5
性能提升是必然而且显著的,大部分情况下都有4-5倍的性能提升,只要能做,就是必选方案!
易用性:2
需要专业技术人才,由于各种CPU指令集不一样,基于SIMD指令集开发的代码没有什么共通的框架,学习使用SIMD是一个比较慢的过程,需要对着CPU的指令集文档反复地看。
开发周期长,BUG难发现与修复,比如用Neon时,由于arm提供的交叉编译工具非常不给力,很多时候都要直接写汇编,汇编代码的调试是非常费时费力的。
另外,由于SIMD是细粒度的并行,并行算法怎么设计在很多情况下都是要思索一番的,典型地如一个矩阵旋转,都不是很容易,即便是专业的技术人才,也不能一下子就实现出来。
参考:
http://blog.csdn.net/jxt1234and2010/article/details/50437884
http://blog.csdn.net/jxt1234and2010/article/details/46620001
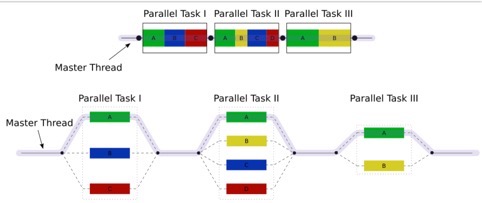
多线程技术
当系统有多个线程/进程时,CPU会按一定的调度策略,把它们尽可能放在不同的核上执行,多线程优化就是把算法拆成多个子任务,跑在不同的线程上,利用CPU多个核的能力,并行执行算法。
比较有名的框架是OpenMP,不过在移动端的算法优化时,一般来说还是自己写线程比较好。
普适性:5
大部分算法都是可以用多线程技术并行的,比如导向滤波,美白调色,高斯模糊等等。
有效性:3
多线程的使用要求算法本身运算量足够大,不然起不到加速效果。多线程的加速比不稳定,在有其他程序抢占资源时很可能没有效果。
易用性:5
由于是粗粒度并行,设计并行方案相对简单,甚至在OpenMP框架下,加一行注释就能搞定。虽然理解线程、同步等概念需要一点积累,但总体而言,多线程优化还是最简单好用的方案。
美白算法优化示例(核心步骤涉密隐藏了)
/*优化前*/
void GLBrightFilter::vFilter(GLBmp* dst, const GLBmp* src) const
{
//GPCLOCK;
GLASSERT(NULL!=dst);
GLASSERT(NULL!=src);
GLASSERT(dst->width()==src->width());
GLASSERT(dst->height()==src->height());
auto w = dst->width();
auto h = dst->height();
auto bpp = dst->bpp();
auto _dst = (unsigned char*)(dst->pixels());
auto _src = (unsigned char*)(src->pixels());
_run(_dst, _src, 0,0,w,h,bpp);
}采用C++11标准中的线程优化:
/*优化后*/
void GLBrightFilter::vFilter(GLBmp* dst, const GLBmp* src) const
{
//GPCLOCK;
GLASSERT(NULL!=dst);
GLASSERT(NULL!=src);
GLASSERT(dst->width()==src->width());
GLASSERT(dst->height()==src->height());
auto w = dst->width();
auto h = dst->height();
auto bpp = dst->bpp();
auto _dst = (unsigned char*)(dst->pixels());
auto _src = (unsigned char*)(src->pixels());
if (h < 500)
{
_run(_dst, _src, 0,0,w,h,bpp);
return;
}
int hunit = h /4;
int hoffset[] = {0, hunit, 2*hunit,3*hunit, h};
std::vector<std::thread*> queues;
for (int i=0; i<4; ++i)
{
int t = hunit*i;
int _h = hoffset[i+1]-hoffset[i];
auto f = ([=]{
_run(_dst, _src,0,t,w,_h,bpp);
});
queues.push_back(new std::thread(f));
}
for (auto t : queues)
{
t->join();
delete t;
}
queues.clear();
}这个例子中的优化有一个缺点,就是每次都要创建、销毁线程。进一步提升性能的方案是创建线程池,但这样的话线程池的管理就要费点脑筋。
OpenCL/CUDA/OpenGL——挖掘GPU
图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和移动设备(如平板电脑、智能手机等)上图像运算工作的微处理器。
由于GPU功能越来越强,加以GPU上编程的实现,人们开始使用GPU去执行一些原本跑在CPU上的算法,这就是所谓的GPGPU(前一个GP则表示通用目的General Purpose)。
要使用GPU进行通用计算,需要基于一个框架,目前的框架主要有 CUDA、OpenGL 和 OpenCL。
CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。这个架构只能在装配了NVIDIA显卡的机器上使用。
OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器。
OpenGL(全写Open Graphics Library)是个定义了一个跨编程语言、跨平台的编程接口规格的专业的图形程序接口,它主要用于图形渲染,但一些图像算法也可以使用它来完成。
普适性:3
平台方面:CUDA只适用于NVDIA的GPU,OpenCL在移动设备上目前还没有被完全支持,OpenGL一般设备都可使用。
算法方面:使用CUDA和OpenCL技术一般都要求算法能做到数据并行,OpenGL的使用条件更为苛刻,仅适用于可以像素级算法。
有效性:4
在PC、服务器上采用GPU优化,非常有效而且性能提升明显,动不动就是百千倍的效率增幅,但在手机上,这个效率就不高了,因为手机端内存带宽少而且GPU性能不那么强。手机上一般用到的只有OpenGL对图像滤镜的优化。
易用性:2
CUDA/OpenCL/OpenGL的编程都是大工程,幸运的是,有很多地方是可重用的,因此,它们有相应的框架/开源库支持,如使用GPU实现滤镜,有GPUImage,这使得开发难度下降不少。
尽管如此,要理解 GPU 和 CPU 的硬件差异和编程方式差异,还是需要一点功夫的(CPU编程是串行思维,GPU编程需要有数据并行思维)。而且,由于这些标准在不同设备上的支持程度不一样,也会有很多问题要解决。
图像反色在OpenGL的实现(仅写出片断着色器)
precision mediump float;
varying vec2 textureCoordinate;
uniform sampler2D inputImageTexture;
void main()
{
vec4 color = texture2D(inputImageTexture, textureCoordinate);
gl_FragColor = vec4((vec3(1.0)-color.rgb), color.a);
}专用芯片
当算法足够重要时,值得为了它设计集成电路,添加新芯片。比如Jpeg图像格式的编解码算法,由于Jpeg格式应用非常广泛,一般做集成芯片的厂商都会加一块专业实现该算法的芯片。
数字信号处理器DSP(digital signal processor)是一种专用于(通常为实时的)数字信号处理的微处理器。

普适性:1
仅在有DSP芯片,或者对特定的算法,值得添加专用芯片去做时,可以采用。仅适用于开发集成芯片系统的技术人员使用,做第三方App的是用不了的。
有效性:5
绝大部分情况下,算法改成DSP或专业芯片特定实现,都可以极大提升性能。在有DSP处理器,或确实是很重要的算法,值得加芯片的话,就可实现。
易用性:1
既需要硬件人员设计电路,又需要软件人员去编写驱动,打通流程,实现难度最高,DSP上面的编程比在GPU上编程还困难。
参考资料
http://www.ruanyifeng.com/blog/2011/08/amazing_algorithms_of_image_processing.html
http://www.arm.com/zh/products/processors/technologies/neon.php
http://www.cnblogs.com/hrlnw/p/3723072.html
https://en.wikipedia.org/wiki/OpenMP
http://blog.csdn.net/firefly_2002/article/details/8545236
http://junzhuivs.blog.51cto.com/7446454/1249404/















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









