







 本文介绍了如何使用极大极小搜索策略和启发式评估函数来设计五子棋AI。AI分析棋局并在有限深度内寻找最佳落子,通过评估函数判断棋局优势。Alpha-Beta剪枝优化搜索效率,实验结果显示AI能够有效应对各种局面。
本文介绍了如何使用极大极小搜索策略和启发式评估函数来设计五子棋AI。AI分析棋局并在有限深度内寻找最佳落子,通过评估函数判断棋局优势。Alpha-Beta剪枝优化搜索效率,实验结果显示AI能够有效应对各种局面。
问题描述
五子棋AI。
设计一个交互式的应用,用户用鼠标在棋盘上单击左键表示落子,然后五子棋AI分析棋局,并在它认为最好的地方落子,双方交替,直到分出胜负或者和棋。
在分析问题的过程中,我们假定图形用户界面已经完成,并且支持“开始游戏”、“重新开始”、“调整先后手”、“调整难度”等功能,获取鼠标的输入以及显示棋盘布局的功能也都正常,那么我们可以把精力放在五子棋AI类的具体实现上。
现在,问题被抽象成,在一个15*15的二维数组中,1表示黑棋,0表示白棋,-1表示还没有落子的空格,AI程序要做的是分析当前的局面,运用启发式评估函数进行搜索,找到对自己最有利(包括对对手限制最多)的地方落子,找到以后AI类返回这个点的坐标。
深度优先搜索似乎是可以完成这个任务的,但是很明显,就算是将大量的不可能是最佳落子点的部分去掉,形成的搜索树也是庞大到不可能在短时间内搜索完成。
人下棋的时候实际上用的是一种试探性的方法。
首先假定在这个位置走了一步棋,然后思考对方会采取哪些策略,或者对我的棋进行围追堵截,或者是继续下他的棋,然后我再根据对方可能采取的方法,看看我是不是有更好的回应……
这个过程一直持续下去,直到若干个轮回以后,找到了一个满意的走法为止。然后我在满意的地方落子。
初学者可能只能看一、两个轮次,而高手可以看几个甚至十几个轮次。
极大极小搜索策略,就是模拟人的这样一种思维过程。
算法描述
极大极小搜索策略
这个搜索策略是考虑双方对弈若干步以后,从可能的走法中找到一个相对较好的来落子,即在有限的搜索深度范围内进行求解。
T:=(s,MAX)
把s加入到OPEN表
CLOSED表为空
LOOP1:
IF OPEN EQ ()
THEN GO LOOP2
n:=FIRST(OPEN)
并将n加入到CLOSED表
IF n可以判断输赢
THEN f(x):=INF OR -INF OR 0, GO LOOP1
ELSE EXPAND(n) to {n_i}, ADD({n_i},T)
IF d(n_i)<k
THEN ADD({n_i},OPEN), GO LOOP1
ELSE 计算f(n_i), GO LOOP1
LOOP2:
IF CLOSED EQ NIL
THEN GO LOOP3
ELSE n_p:=FIRST(CLOSED)
IF n_p in MAX AND f(n_ci) in MIN 有值
THEN f(n_p):=max{f(n_cj)}, 从CLOSED删除n_p
IF n_p in MIN AND f(n_ci) in MAX 有值
THEN f(n_p):=min{f(n_cj)}, 从CLOSED删除n_p
GO LOOP2
LOOP3:
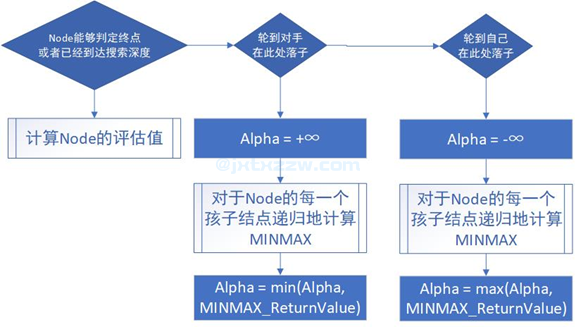
前面的代码都是分别用两部分代码处理了极大节点和极小节点两种情况,其实,可以只用一部分代码,既处理极大节点也处理极小节点。
不同的是,前面的评估函数是针对指定的一方来给出分数的,这里的评估函数是根据当前搜索节点来给出分数的。
每个人都会选取最大的分数,然后,返回到上一层节点时,会给出分数的相反数。
int AI::MINMAX_Search_With_AlphaBetaCutOff(int depth, int player) {
int best = NEGATIVE_INFINITY;
if (depth == this->depth) {
return heuristic(player);
}
list<Point> children;
for (int i = 0; i < GRID_NUM; ++i)
for (int j = 0; j < GRID_NUM; ++j) {
if (chessBoard[i][j] == NONE && nearby(i, j)) {
children.emplace_back(Point(i, j));
}
}
for (list<Point>::iterator it = children.begin(); it != children.end(); it++) {
setPos(*it, player);
int val = -MINMAX_Search_With_AlphaBetaCutOff(depth + 1, 1 - player); // 注意这里有个负号
setPos(*it, NONE);
if (val > best) {
best = val;
next = *it;
}
}
return best;
}
MINMAX搜索的过程是把搜索树的生成和格局估值这两个过程分开来进行,即先生成全部搜索树,然后再进行端结点静态估值和倒退值的计算,这显然会导致低效率。
事实上,如果生成某个结点A以后,马上进行静态估值,得知f(A)=-∞之后,就可以断定再生成其余结点即进行静态计算是多余的,可以马上对MIN结点赋倒推值-∞,而丝毫不会影响MAX的最好优先走步的选择。
Alpha-Beta剪枝用于裁剪搜索树中没有意义的不需要搜索的树枝,以提高运算速度。
它的基本思想是根据上一层已经得到的当前最优结果,决定目前的搜索是否要继续下去。
如果某个着法的结果小于或等于Alpha,那么它就是很差的着法,因此可以抛弃。
如果某个着法的结果大于或等于Beta,那么整个节点就作废了,因为对手不希望走到这个局面,而它有别的着法可以避免到达这个局面。因此如果我们找到的评价大于或等于Beta,就证明了这个结点是不会发生的,因此剩下的合理着法没有必要再搜索。
如果某个着法的结果大于Alpha但小于Beta,那么这个着法就是走棋一方可以考虑走的,除非以后有所变化。
if depth = 0 or node is a terminal node
return the heuristic value of node
if Player = MaxPlayer // 极大节点
for each child of node // 极小节点
alpha := max(alpha, alphabeta(child, depth-1, alpha, beta, not(Player) ))
if beta <= alpha // 该极大节点的值>=alpha>=beta,该极大节点后面的搜索到的值肯定会大于beta,因此不会被其上层的极小节点所选用了。对于根节点,beta为正无穷
break
return alpha
else // 极小节点
for each child of node // 极大节点
beta := min(beta, alphabeta(child, depth-1, alpha, beta, not(Player) )) if beta <= alpha // 该极大节点的值<=beta<=alpha,该极小节点后面的搜索到的值肯定会小于alpha,因此不 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4641
4641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











