







今天给大家分享一个基于视觉和文本的聊天机器人,使用DeepSeek-VL-7B模型提供文本和图像的自动化生成回复,它允许用户在与机器人交互时提交文本和图像输入。

DeepSeek-VL简介
DeepSeek-VL系列代表了在多模态AI领域的一大突破,提供了两种不同规模的模型,分别是13亿参数和70亿参数模型。这些模型利用了DeepSeekAI自研的语言模型DeepSeek-LLM和视觉编码器SigLIP-L的组合,能够处理不同分辨率的图像输入,其中70亿参数规模的模型支持1024×1024分辨率图像的输入,而13亿参数规模的模型支持384×384分辨率图像输入。
在多个标准评测数据集上,DeepSeek-VL系列模型展示了其卓越的多模态理解能力。特别是70亿参数的DeepSeek-VL-7B模型,在多模态理解能力评测数据集上取得了领先的成绩,证明了其在高精度多模态任务处理上的优势。
离线懒人包来了
老规矩,还是无套路直接分享给大家。大家下载到本地解压即用,请注意不要放置在含中文的文件路径中。

大家下载解压到本地。
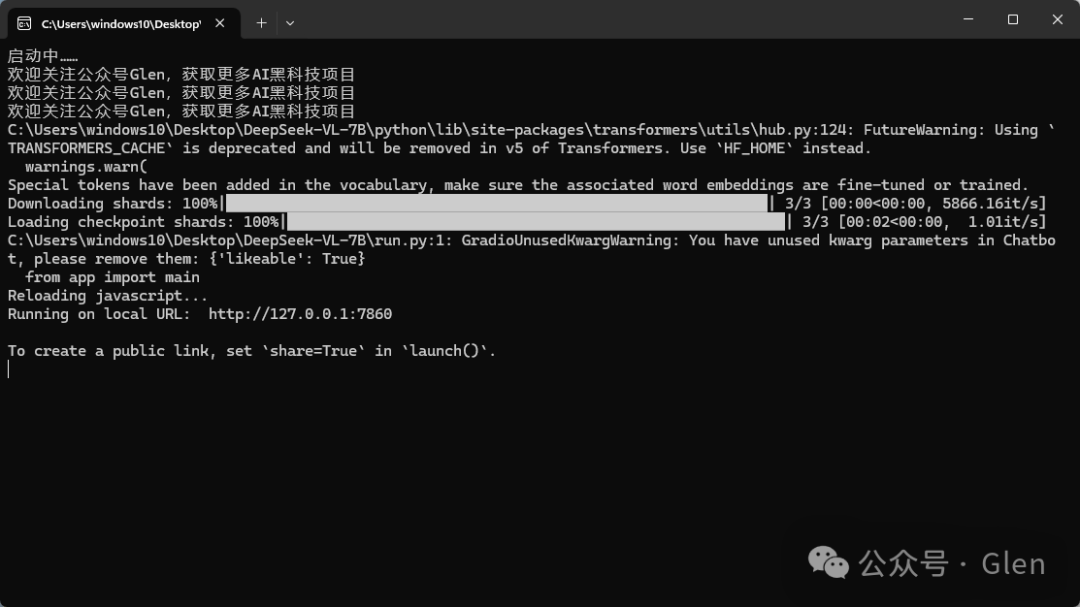
①双击“一键启动.exe”。
②双击一键启动程序后,会打开一个命令提示窗口,项目会自动运行。加载成功后,请自行复制以下网址在浏览器打开“ http://127.0.0.1:7860/”,记得点点关注不迷路哦,后续还有更多酷炫的AI项目分享~
③打开页面后,可以看到项目主界面,界面已经为大家汉化好了。
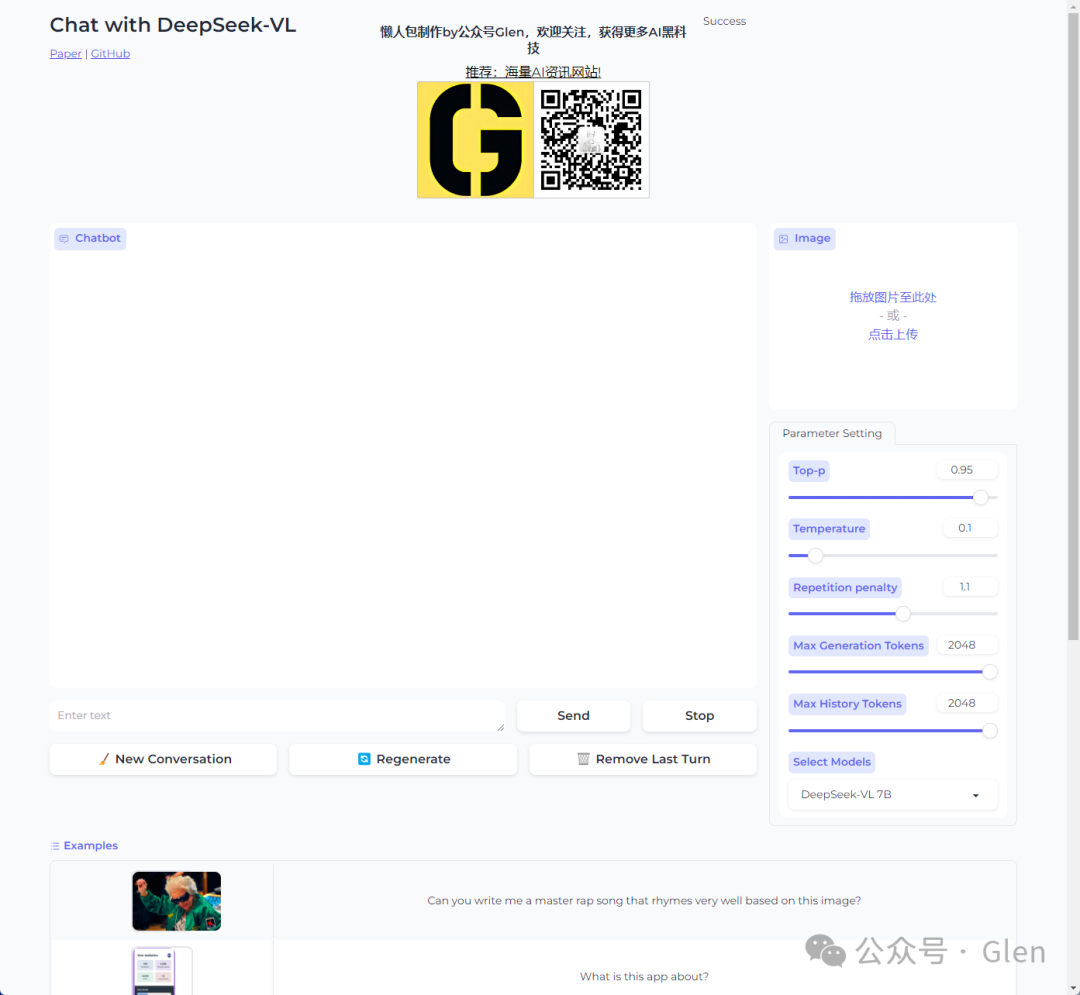
使用很简单,2步极速上手,即刻开始快乐地玩耍:
-
输入提示词:跟使用其他AI大模型一样,输入图片,输入提示词。
-
点击生成:点击“提交”按钮,等待即可。
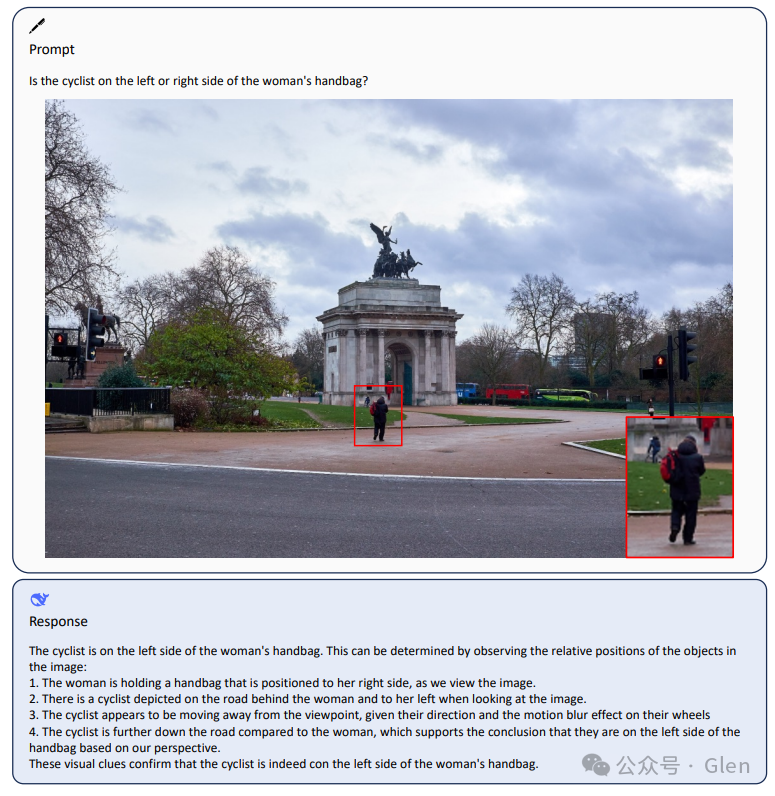
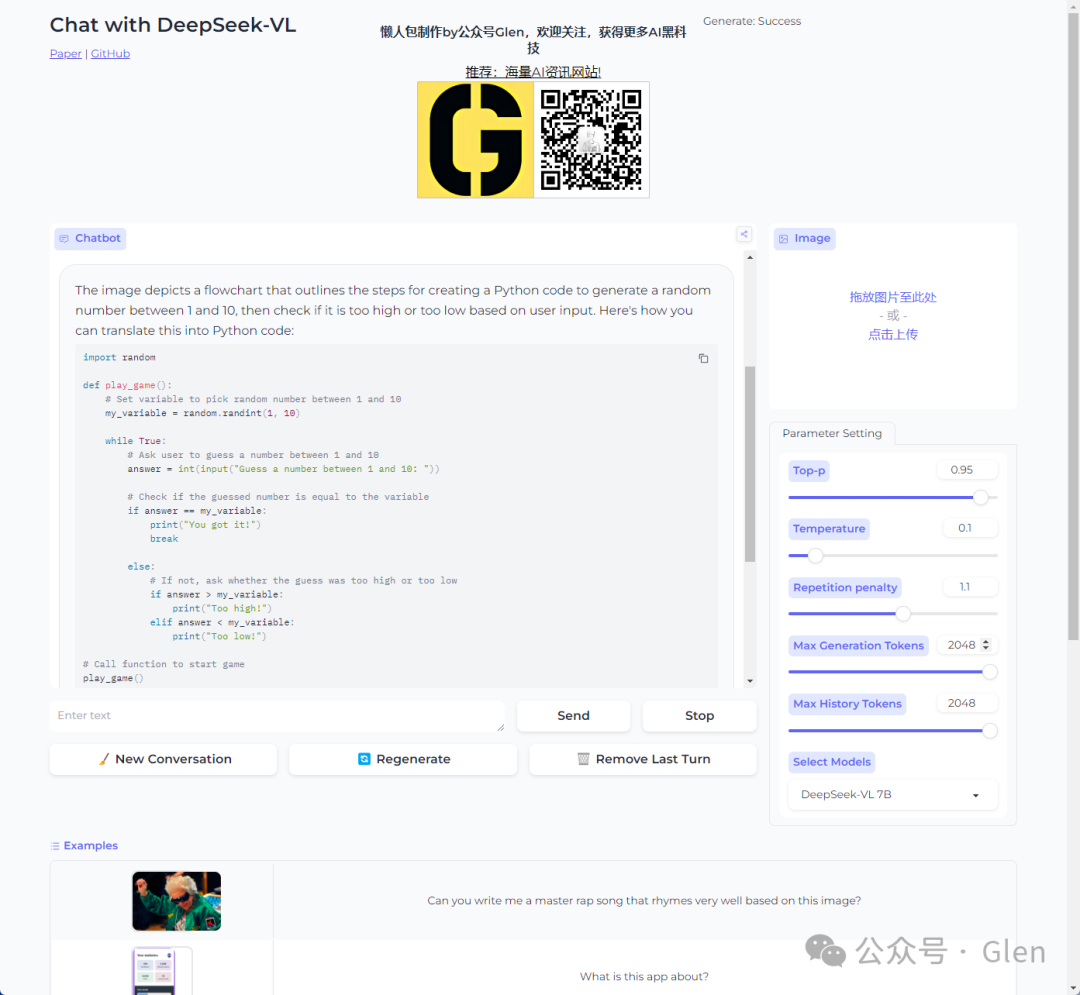
项目运行一段时间后,会得到该项目给出的回答。下图是我亲测的该大模型可以识别图片的内容,并给出回答,我提的问题是让它识别一个网页,然后写出代码。这都能很快的实现,简直可怕!
注意事项:
①该项目建议使用英伟达显卡运行,由于尺寸很小,CPU也可以运行但比较慢;
②请确保安装路径不包含中文,不然可能会引起奇怪的适配问题。
今天就聊到这了,我是Glen,感谢你看我的文章,欢迎大家继续支持我,请点赞、收藏、分享三连走一波吧~
关注公众号Glen,回复【DeepSeek】,免费获得本文资源~















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









