







之前做数据梳理的时候对主数据进行了一个总结,虽然项目没有很好的开展,不过对我来说也是有很多收获的,这里把之前用到的一些文档总结如下。
术语和定义
主数据
早期以 ERP 为代表的制造业集成应用系统的发展过程中,产生了信息孤岛和数据处理危机问题。为了解决这些问题,主数据这个概念随之诞生。
目前,对主数据的定义没有统一,一些 MDM 产品提供商和学者提出了各自对主数据的定义,如下:
David Loshin 在其主数据管理的著作中对主数据的定义是:主数据是企业中跨应用的核心业务实体,包括元数据、定义、属性、关系、角色和类别等。
维基百科对主数据的定义是:主数据是在企业中可以共享的、一致的业务实体,是跨系统、跨应用和跨流程的基础数据的唯一来源,包括业务数据、非结构数据、分析型数据、组织架构数据及元数据。
Gartner 公司的定义是:主数据是描述企业核心实体的、跨业务流程的、统一的数据标识和属性。
ISO 标准中的定义:主数据是指事务处理需参考的独立的基础数据实体。
著名的软件供应商 oracle 的定义:多个业务系统中最核心的、需要共享的数据,它是支持企业业务和分析的关键基础数据;IBM 对主数据的定义是:存在于多个异构系统中的跨核心业务实体的、具有高价值的数据。尽管不同角色对主数据定义的表达形式有所差异,但都反映了主数据的基本特征。总的来说,主数据的定义是:
主数据(Master Data)是指具有高业务价值的、可以在企业内跨越各个业务部门被重复使用的数据,具有相对静态的特点,是单一的、准确的、权威的数据来源。
基础主数据
基础主数据就是在品名规范、收集模板、扩充视图填写过程中需要提前维护的字段,类似于元数据,是其他主数据的基础数据。
基础主数据分为两大类:一类是自定义的基础数据,这部分数据在新建 主数据时可以新增,数据申请人员有权限进行申请,如用户创建的属性时, 发现系统中没有该类属性,则该用户可以申请新增此属性。另一类是很少新增或 者修改的基础数据,这些数据一般是货币、国家、行业、标准等,在系统初始化。
主数据编码标准
主数据编码标准定义了数据的分类和编码规则,是主数据标准化建设的核 心内容。 通过对主数据分类编码的标准化,杜绝自然语言描述下的不规则和理解 的二义性,便于实现计算机信息处理,以提高信息管理的效率
主数据属性标准
主数据标准,是各类主数据的数据模型标准,定义了属性构成、元数据、数据关系和参考数据等内容,是主数据标准化的关键。主数据包括物料、供应商、 客户、财务、组织架构数据。每类主数据应该由哪些属性(或字段)去约束,都 需要提前规范化、标准化。
主数据管理
主数据管理(Master Data Managent, MDM)描述了一组规程、技术和解决方案,用于为所有利益相关方(如用户、应用程序、数据仓库、流程以及贸易伙伴)创建并维护业务数据的一致性、完整性、相关性和精确性。
主数据编码标准
编码原则
编码过程中遵循以下总体原则:
- 唯一性
确保主数据对象的数据条目都有一个唯一的代码,不重复;
- 科学性
根据业务需求,选择主数据最稳定的本质属性或特征作为分类的基础和依据;
- 兼容性
应与相关标准协调一致,确保与集团、相关伙伴在有关主数据编码上尽量遵循公共的标准;
- 可扩充性
编码应留有适当的后备容量,以便适应不断扩充的需要;
- 简明性
编码结构应尽量简单,长度尽量短,以便节省存储空间和减少代码的差错率;
- 实用性
编码应尽可能反映编码对象的现实特点,避免过于理想,而造成对业务效率的降低;
编码规则
企业信息编码方法
信息化的过程中,为了便于计算机处理信息,需要给企业的各类信息(人员、物资、机构等)进行编码。信息编码一般由数字和字母组成,编码位数由编码对象的多少决定,同时还要遵循一定的信息分类和编码原则。根据代码的含义性将代码分为图示的几大类型。按照代码所代表的编码对象或编码对象的特征,又可以将代码分为标识码和特征码,特征码又包括分类码、结构码、状态码、一般取值码等。这些编码之间的分类也不是绝对的,在实际应用过程中可以按照具体的编码对象选择最佳的编码或多类编码的组合。
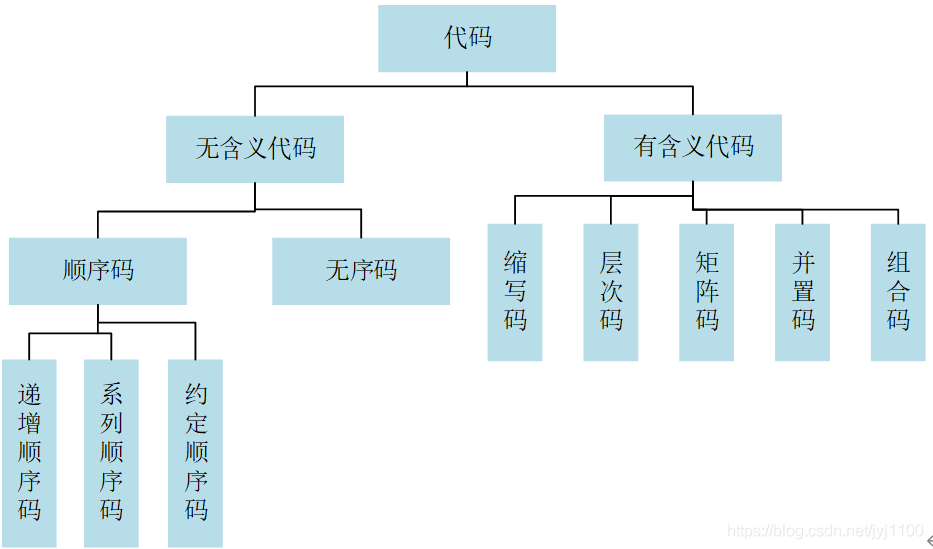
3-1编码规则示意图
顺序码
在一个有序的字母、数字或者字母加数字的集合中,顺序地为编码对象分配编码。顺序码包括三种类型:递增顺序码、系列顺序码和约定顺序码。
递增顺序码:按照预先定义的字母或者数字递增步长顺序增加。
系列顺序码:首先划分编码对象类别,然后确定各个类别的代码范围,最后,顺序地赋予编码对象在各自类别编码范围内的代码值。
约定顺序码:首先将编码对象本身按照某种顺序(缩写字母顺序或事件、活动的年代顺序等)进行排列,然后再将有序的代码值(字母或数字顺序)与其排列顺序进行一一对应,从而得到编码对象的代码值。这种编码的前提是所有的编码对象都预先已知并且编码对象集合不会扩展。该编码不是完整意义上的顺序码。
无序码
无序码是对编码对象用无序的字母或自然数进行编码,该编码无规律可循,通常由计算机随机给出。通常作为复合码的一部分而使用。
缩写码
缩写码,将编码对象的名称(英文或者中文拼音)进行缩写,编码的形成是取名称中的一个或多个字符(如首字母)。缩写码适用于编码对象是相对稳定的且被人们所熟知的有限标识代码集。
层次码
该编码方式以线分类为基础,下位类包含在上位类中,层次码的编码基础是编码对象各层级间特性的差异,将编码对象编成连续递增的复合代码。
层次码适用于统计目的、基于学科的出版分类等情况
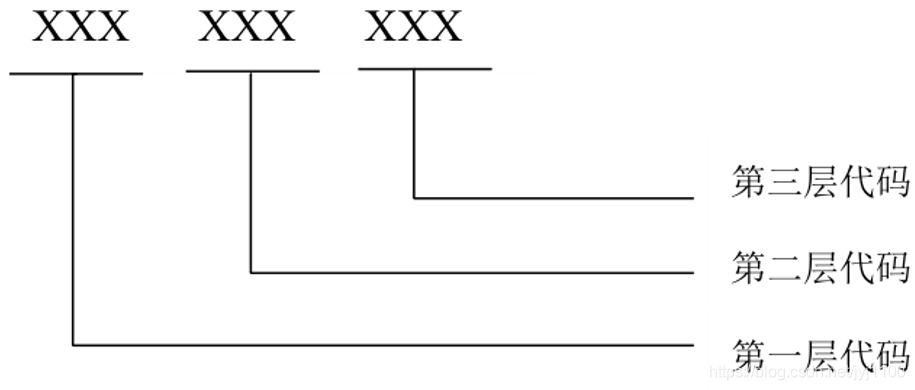
3-2层次码示例
矩阵码
这种编码方式以矩阵表(复式记录表)为基础,编码对象的代码是矩阵表中行值和列值的组合,这样不同的编码对象对应一样的行(或列)会有若干相同的特性。矩阵码对编码对象的要求是具有良好的结构和稳定性,如汉字编码字符集[31] 。
并置码
这种编码实质上是将编码对象的特性代码段组合而成的复合代码(如图 2-7所示)。这些特性代码描述编码对象相互独立的特性,可以是无序码、缩写码、顺序码等任意编码类型。面分类法常使用此编码结构。
主数据项
主数据分类方法
信息分类的基本方法有三种:线分类法、面分类法和混合分类法。
线分类法
线分类法也称层级分类法。它将分类对象按照若干属性依次分为若干逐级展开的层级类目,形成一个有层次的分类体系。在该体系中,同层级类目之间互不重复交叉、形成并列关系,不同层级类目之间是从属关系。采用线分类法进行编码时一般采用的编码结构是层次码,为每个层级编码,最低的层级可以使用流水码,最终编码是各层级编码的组合。该分类体系可以用分类树进行表示(如图所示)。
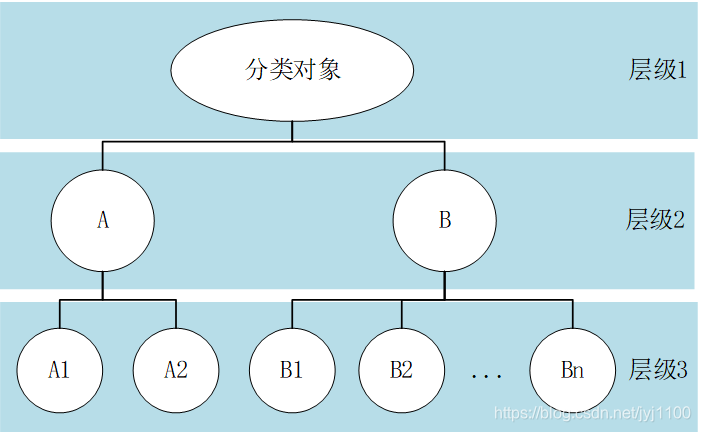
4-1线分类图示
线分类法具有清晰的层次结构,能较好地反映类目之间的隶属关系,是人们习惯使用的分类方式,既符合手工操作的习惯,也易于被计算机处理。但是该分类体系结构弹性较差,当改动或者删除分类层级中的一个中间类目时,会引起该类目的下层级结构发生变化;另外,当分类层级较深时,代码位会变长,影响使用效率。
面分类法
面分类法是依据分类对象本身固有的各种属性(或特性),划分成互相之间没有隶属关系独立的“面”,每个“面”由一组类目组成。将某个“面”下的一种类目和其他某个或多个“面”的一种类目组合在一起,可以组成一个复合类目。采用面分类法进行编码时,对每个面进行编码,然后将“面”编码进行组合即为最终编码。面分类法示意图如所示。
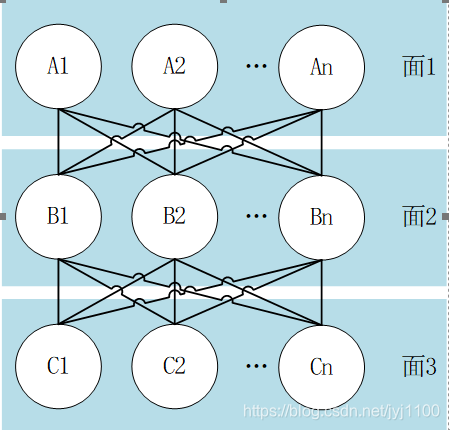
4-2面分类图示
面分类法描述的分类结构具有较大的柔性,单个“面”内类目的改变不会引起其他“面”的变化;面分类法使用性更强,在分类属性(或特性)不改变的情况下,可以通过类目组合规则的变化对分类结果进行调整。当然,该方法也有不足:采用该分类进行编码,使得编码容量利用不充分;当分类属性(或特性)较多时,组合数量会急剧增加;另外,根据对象特性划分的面有时类目很多,但实际组合应用的不多,即存在大量无应用意义的组合,导致结构上的冗余;同时难于手工信息处理。
混合分类法
混合分类法将线分类法和面分类法综合起来运用,吸收两种方法优点,避免各自的缺点,从而得出更为合理的分类结构。在实际应用过程中,通常将线分类法作为主体,在划分的某一个层次中将面分类法作为辅助分类方法进行分类。如由德国提出的著名的 OPITZ分类码,该编码方案在对零件进行编码时取得了良好的效果。
定义因研究不同各有差别,但实施是非常重要的,毕竟主数据分类好,产品开发加班少,希望以后有机会实施整个数据治理。

















 2884
2884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









