









岁月匆匆如流水,青春一去不回头。近2年来,随着AI等技术的发展,目前深度学习对图像,语音,文字等已经比较成熟,我也来跟跟风,拿人物图像练练手。
下面是我采用的是DenseNet卷积神经网络模型来训练
自己整理一小部分图片进行训练
第一组:


第二组:

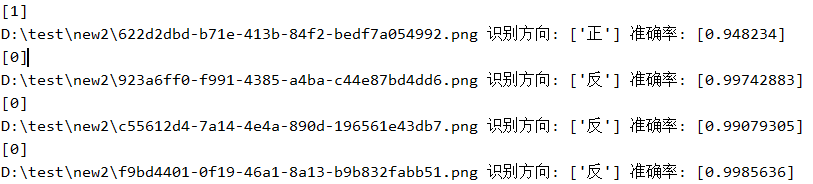
第三组:
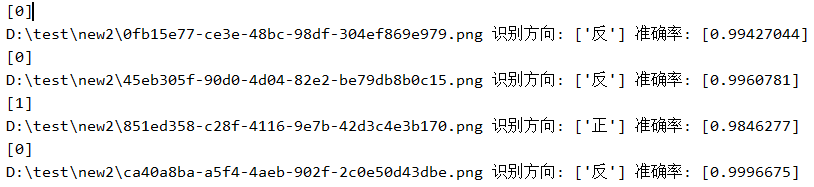
以上我只是用训练的图片随机选择测试了几组数据,由于本人精力有限,没时间玩游戏,在此提出一些思路
岁月匆匆如流水,青春一去不回头。近2年来,随着AI等技术的发展,目前深度学习对图像,语音,文字等已经比较成熟,我也来跟跟风,拿人物图像练练手。
下面是我采用的是DenseNet卷积神经网络模型来训练
自己整理一小部分图片进行训练
第一组:
第二组:
第三组:
以上我只是用训练的图片随机选择测试了几组数据,由于本人精力有限,没时间玩游戏,在此提出一些思路
 883
779
947
5982
2万+
883
779
947
5982
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























