







目前为止语义分割的最经典框架DeepLab,后续很多分割框架也是根据其修改而来的。其构建思想的闪光点有很多,下面将会一一为各位读者讲解。感兴趣的同学可以参考原文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
创新点
– Atrous convolution (即Dilated convolution),在不改变输出尺寸的情况下增大感受野。
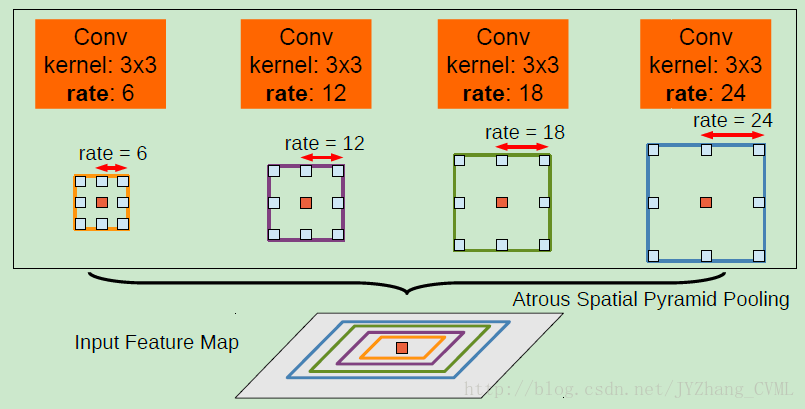
– ASPP (Atrous Spatial Pyramid Pooling),解决 multi-scale 分割的问题。
– 采用深度卷积神经网络耦合概率图模型的方法,改善分割边界特性。语义分割问题存在的挑战 —— 于上面创新点一一对应
下降的特征分辨率,由网络中max-pooling和down-sampling组合引起。
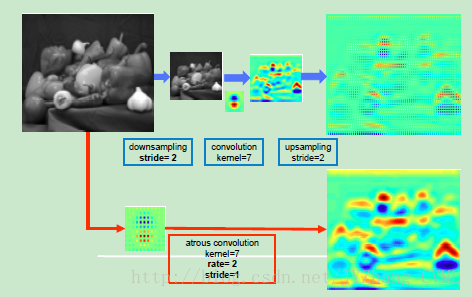
DeepLab中的解决方法:将最后几个max-pooling中的降采样操作去除,然后上采样后续的卷积核形成 atrous convolution。这种方式是 deconvolution 的有力替代。与常规卷积操作相比,多孔卷积能够在不缩小feature map分辨率的同时,有力的(指数级)增大感受野,且并不会引入很大的计算复杂性。物体的多尺度性质
一种最标准的多尺度处理方法是,输入原始输入图像的多个multi-scale缩放版本得到对应的multi-scale feature map,然后对feature map进行缩放到原始尺寸,将其最大的响应作为其多尺度的feature map。可想而知这种方法并不能有效的计算。
DeepLab中的解决方法:在spatial pyramid pooling的基础上,提出 ASPP 技术:在多孔卷积之前以多个采样率采样特定的特征层 —— 不同采样率的多个并行多孔卷积层。Invariance不变性造成的分割边界的不准确
对于分类问题而言,网络的invariance有助于提高算法的鲁棒性,提高分类精度,然而对于分割问题,这种不变性则对空间准确性带来不利影响。在FCN中采用“Skip-layers”从多层网络中提取Hyper-column特征,在其他方法中定位任务被委托给底层的基于超像素的分割方法。但是在DeepLab中采用一种有效的替代方法:利用全连接的条件随机场提高模型得到最后分割的精确性 —— 改善边缘细节,而且考虑图像的长距离的依赖性。
算法框架
- 首先利用图像分类任务pre-trained得到的模型 VGG-16 或者 ResNet-101 ,将其中所有全连接层转换成卷积层。
- 采用 Atrous convolution 提高特征分辨率,使得原来的输出特征单元感受野stride =32降低成stride = 8。(其实文章的网络构架并没有完全消除降采样操作,还是先进行了2步降采样,后面才用atrous convolution保持特征分辨率的同时,加大感受野)
- 采用简单的双线性插值对上述stride = 8的feature map进行8倍上采样操作,恢复成原始图像分辨率。从而实现逐项素的 dense prediction。
- 最后利用全连接的CRFs进行分割结果的优化。
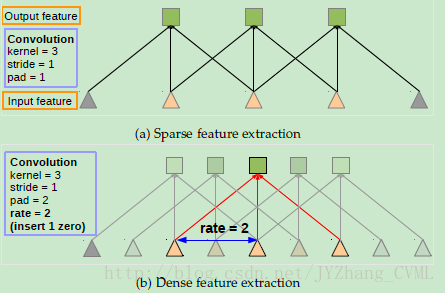
算法细节1 —— 多空卷积 atrous convolution
以传统的FCN网路为例,构建中连续的max pooling和striding的操作在扩大感受野的同时也不可避免的减小了特征图的空间分辨率(32倍的减小),而FCN采用的方法是利用deconvolution操作将feature map恢复成原先的分辨率,然而这样会需要额外的内存和时间。
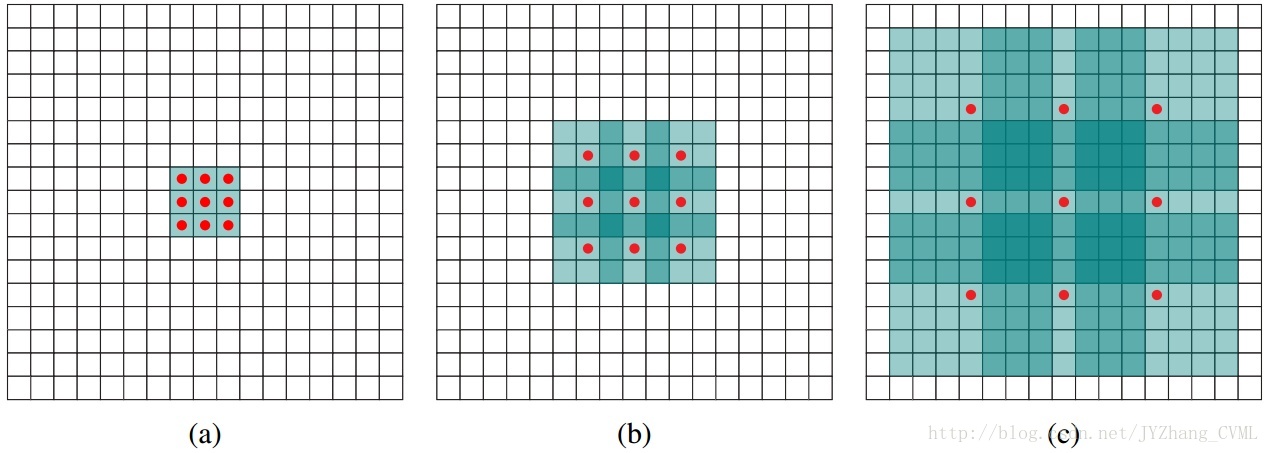
上图(a)采用rate=1的多孔卷积也即常规的卷积操作。图(b)采用的3*3的rate=2的多空卷积,真实的卷积核尺寸为3*3但是由于空洞的出现,实际卷积的图像patch大小为7*7,但其中只有9个红色的点对应的卷积核参数不为0。因此如果图(b)是级联在图(a)之后的操作,则通过这样的多孔卷积的方式感受野变为 7*7 。同理图(c)将感受野扩大到15*15。
总的来说,如果仅仅采用常规卷积操作级联不采用降采样操作(保证特征的维度),感受野只能呈现线性增大的趋势,而采用多孔卷积操作则可以变为指数级增大的效果。
算法细节2 —— ASPP
收到R-CNN的空间金字塔池化方法的启发,以单个尺度重对提取的特征进行重采样,等效于对任意尺度的区域进行分析分类。在DeepLab中采用不同采样率的多个并行的多孔卷积层,对不同采样率下得到的特征在独立的分支中进行处理,并融合产生最后的结果。
算法细节3 —— 全连接CRFs对于分割效果的改善
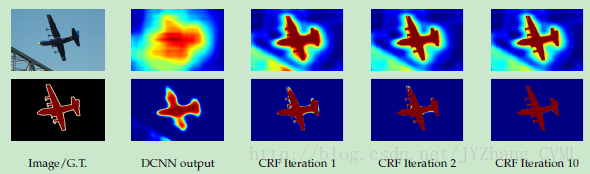
如图所示,分割的定位精度和分类性能之间存在着固有的trade-off:更深的网络(正常max pooling)常常具有很强的不变性和较大的感受野,在分类问题中具有很好的效果,然而会造成平滑的相应。DCNN的得分图仅仅能够预测物体的存在和非常粗略的位置,对于其分割边界的精度是很差的。
因此为了进一步改善细节部分的分割效果,我们耦合DCNN的识别能力和全连接的CRF的细粒度定位精度来获得更好的分割效果。对于边界细节的效果远远优秀于现有的方法。总结
个人认为,这篇DeepLab V2分割文章在图像分割领域具有重要的意义。首先推广了多孔卷积这一理念,使得在不缩小特征分辨率的同时能够有效的扩展感受野,进而准确的识别目标。同时,感受野的扩大也会带来分割定位的不准确,DeepLab提出耦合全连接的CRFs进行定位的细化,具有很强的实际意义。最后配套与多孔卷积ASPP方法被提出以针对分割问题中广泛存在的 multi-scale 问题。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









