






一、嵌入式系统分层
- 操作系统的作用:向下管理硬件、向上提供接口(API)。
- 应用开发:即使用系统提供的接口(API),做上层应用程序的开发
- 底层开发:即做操作系统本身的开发
Linux层次结构
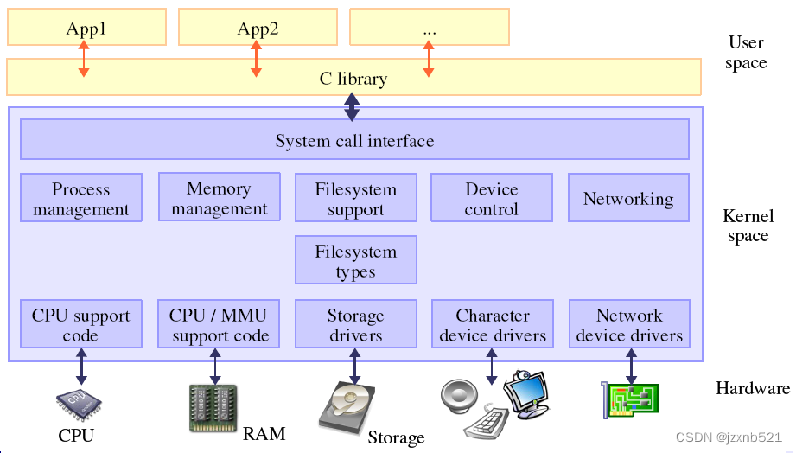
Linux子系统
- 进程管理:管理进程的创建、调度、销毁等
- 内存管理:管理内存的申请、释放、映射等
- 文件系统:管理和访问磁盘中的文件
- 设备管理:硬件设备及驱动的管理
- 网络协议:通过网络协议栈(TCP、IP...)进行通信
底层开发学习路线:ARM -> 系统移植 -> 驱动开发
ARM学习内容:CPU 接口 硬件

计算机硬件基础
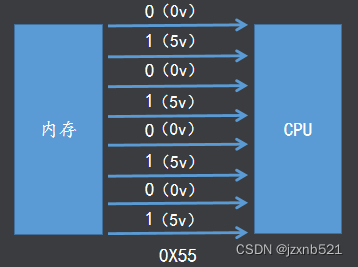
在计算机中数据的存储、运算、传输都是以高低电平的方式 二进制(0、1)
所以数字电路中用高、低电平来表示逻辑1和0。 0x55 - > 0101 0101
计算机组成
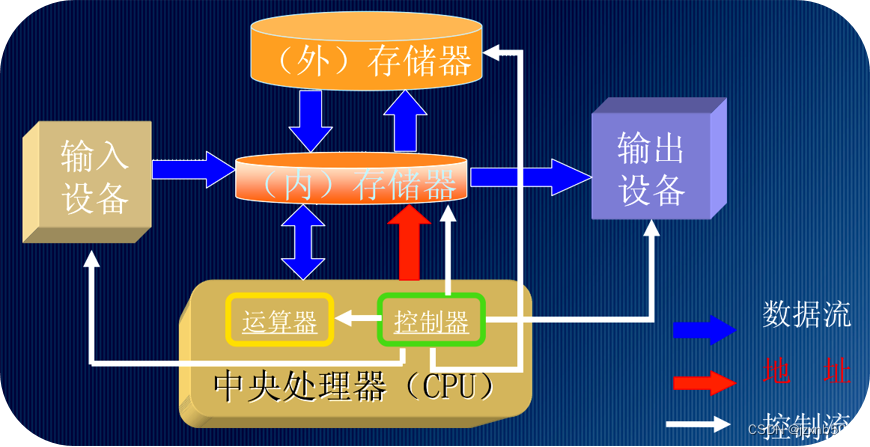
- 输入设备 把其他信号转换成计算机能识别和处理的信号并送入计算机中 如键盘、鼠标、 摄像头等
- 输出设备 把运算结果以人或其他设备所能接受的形式送出计算机外 如显示器、音响、打 印机等
- 存储器 存储器是用来存储程序和数据的部件,是实现"存储程序控制"的基础 如内存、硬盘等
- 运算器 CPU中负责进行算数运算和逻辑运算的部件,其核心是算术逻辑单元ALU
- 控制器 控制器是CPU的指挥中心,其控制着整个CPU执行程序的逻辑过程
注:运算器和控制器共同组成了CPU
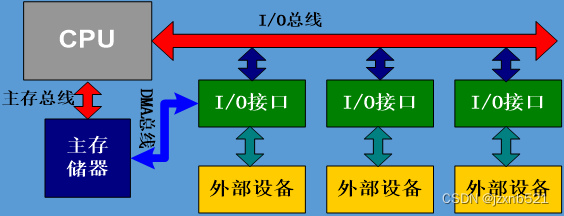
总线
总线是计算机中各个部件之间传送信息的公共通信干线, 在物理上就是一束导线按照其传递信息的类型可以分为数据总线、地址总线、控制总线
DMA总线:DMA(Direct Memory Access)即直接存储器访问,使用DMA总线可以不通过CPU直接在存储器之间进行数据传递
多级存储结构与地址空间
三级存储结构
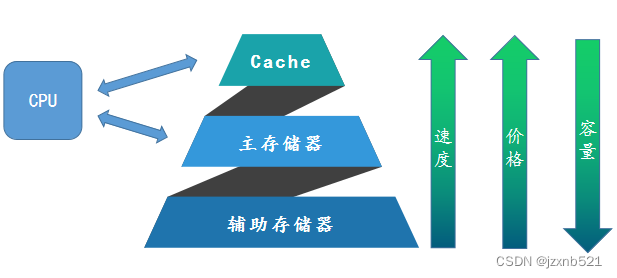
使用三级存储结构是为了兼顾速度、容量、价格
Cache (高速缓存): 速度最快、价格最贵、容量最小、断电数据丢失、cpu可直接访问 存储当前正在执行的程序中的活跃部分,以便快速地向CPU提供指令和数据
主存储器(内存) : 速度、价格、容量介于Cache与辅存之间、断电数据丢失、cpu可直接访问 存储当前正在执行的程序和数据
辅助存储器 (硬盘) : 速度最慢、价格最低、容量最大、断电数据不丢失、cpu不可直接访问 存储暂时不运行的程序和数据,需要时再传送到主存
CPU能够直接读写cache和主存储器
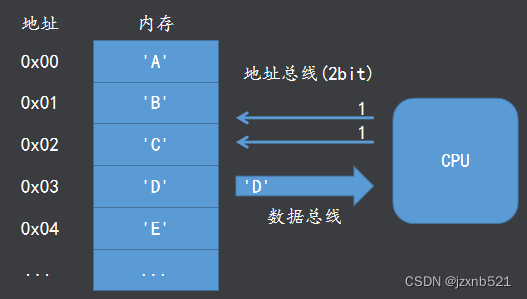
地址空间
一个处理器能够访问(读写)的存储空间是有限的,我们称这个空间为它的地址空间(寻址空间),一般来说N位地址总线的处理器的地址空间是2的N次方。
如:地址总线为32bit的处理器的地址空是 2的32次幂 也就是 4294967296bit 也就是4GB。
CPU工作原理概述
CPU工作原理
关于寄存器:计算机基础知识——认识寄存器 源自博主:简说Linux内核
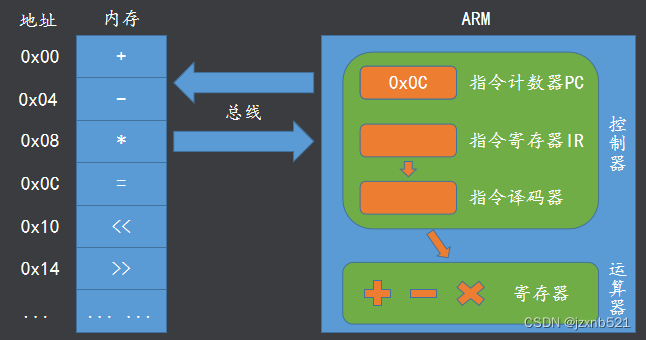
指令的执行过程
一条指令的执行分为三个阶段 :
- 取址: CPU将PC寄存器中的地址发送给内存,内存将其地址中对应的指令返回到CPU中的指令寄存器(IR)
- 译码: 译码器对IR中的指令进行识别,将指令(机器码)解析成具体的运算
- 执行: 控制器控制运算器中对应的运算单元进行运算,运算结果写入寄存器
每执行一条指令后PC的值会自动增加指向下一条指令
ARM处理器概述
ARM的含义
ARM(Advanced RISC Machines)有三种含义: 一个公司的名称、一类处理器的通称、一种技术
ARM公司 :
- > 成立于1990年11月,前身为Acorn计算机公司
- > 主要设计ARM系列RISC处理器内核
- > 授权ARM内核给生产和销售半导体的合作伙伴,ARM公司并不生产芯片
- > 提供基于ARM架构的开发设计技术软件工具、评估板、调试工具、应用软件、总线架构、外围设备单元等
ARM产品系列
- 早先经典处理器 包括ARM7、ARM9、ARM11家族
- Cortex-A系列 针对开放式操作系统的高性能处理器 应用于智能手机、数字电视、智能本等高端运用
- Cortex-R系列 针对实时系统、满足实时性的控制需求 应于汽车制动系统、动力系统等
- Cortex-M系列 为单片机驱动的系统提供了低成本优化方案 应用于传统的微控制器市场、智能传感器、汽车周边等

RISC处理器
RISC(精准指令集)只保留常用的的简单指令,硬件结构简单,复杂操作一般通过简单指令的组合实现,一般指令长度固定,且多为单周期指令
RISC处理器在功耗、体积、价格等方面有很大优势,所以在嵌入式移动终端领域应用极为广泛
CISC处理器
不仅包含了常用指令,还包含了很多不常用的特殊指令,硬件结构复杂,指令条数较多,一般指令长度和周期都不固定
CISC处理器在性能上有很大优势,多用于PC及服务器等领域
CISC(Complex Instruction Set Computers,复杂指令集计算集)和RISC(Reduced Instruction Set Computers,精简指令集)是两大类主流的CPU指令集类型,其中CISC以Intel,AMD的X86 CPU为代表,而RISC以ARM,IBM Power为代表。RISC的设计初衷针对CISC CPU复杂的弊端,选择一些可以在单个CPU周期完成的指令,以降低CPU的复杂度,将复杂性交给编译器。举一个例子,CISC提供的乘法指令,调用时可完成内存a和内存b中的两个数相乘,结果存入内存a,需要多个CPU周期才可以完成;而RISC不提供“一站式”的乘法指令,需调用四条单CPU周期指令完成两数相乘:内存a加载到寄存器,内存b加载到寄存器,两个寄存器中数相乘,寄存器结果存入内存a。按照此思路,早期的设计出的RISC指令集,指令数是比CISC少些,单后来,很多RISC的指令集中指令数反超了CISC,因此,引用指令的复杂度而非数量来区分两种指令集。
当然,CISC也是要通过操作内存、寄存器、运算器来完成复杂指令的。它在实现时,是将复杂指令转换成了一个微程序,微程序在制造CPU时就已存储于微服务存储器。一个微程序包含若干条微指令(也称微码),执行复杂指令时,实际上是在执行一个微程序。这也带来两种指令集的一个差别,微程序的执行是不可被打断的,而RISC指令之间可以被打断,所以理论上RISC可更快响应中断。
在此,总结一下CISC和RISC的主要区别:
- CISC的指令能力强,单多数指令使用率低却增加了CPU的复杂度,指令是可变长格式;RISC的指令大部分为单周期指令,指令长度固定,操作寄存器,只有Load/Store操作内存
- CISC支持多种寻址方式;RISC支持方式少
- CISC通过微程序控制技术实现;RISC增加了通用寄存器,硬布线逻辑控制为主,是和采用流水线
- CISC的研制周期长
- RISC优化编译,有效支持高级语言
SOC(System on Chip)
即片上系统,将一个系统中所需要的全部部件集成在一个芯片中
在体积、功耗、价格上有很大优势
指令集
指令
- 能够指示处理器执行某种运算的命令称为指令(如加、减、乘 ...)
- 指令在内存中以机器码(二进制)的方式存在
- 每一条指令都对应一条汇编
- 程序是指令的有序集合
指令集
- 处理器能识别的指令的集合称为指令集
- 不同架构的处理器指令集不同
- 指令集是处理器对开发者(程度员)提供的接口
大多数ARM处理器都支持两种指令集:
1) ARM指令集 : 所有指令(机器码)都占用32bit存储空间
代码灵活度高、简化了解码复杂度
执行ARM指令集时PC值每次自增4
2)Thumb指令集 : 所有指令(机器码)都占用16bit存储空间
代码密度高、节省存储空间
执行Thumb指令集时PC值每次自增2
编译原理
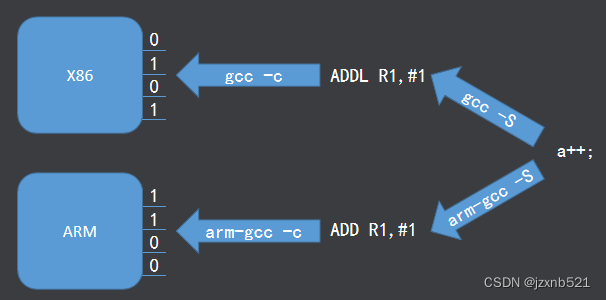
机器码(二进制)是处理器能直接识别的语言,不同的机器码代表不同的运算指令,处理器能够识别哪些机器码是由处理器的硬件设计所决定的,不同的处理器机器码不同,所以机器码不可移植
汇编语言是机器码的符号化,即汇编就是用一个符号来代替一条机器码,所以不同的处理器汇编也不一样,即汇编语言也不可移植
C语言在编译时我们可以使用不同的编译器将C源码编译成不同架构处理器的汇编,所以C语言可以移植
ARM存储模型
ARM数据类型
ARM采用32位架构,基本数据类型有以下三种
Byte 8bits
Halfword 16bits
Word 32bits
数据存储
Word型数据在内存的起始地址必须是4的整数倍
Halfword型数据在内存的起始地址必须是2的整数倍
注:即数据本身是多少位在内存存储时就应该多少位对齐
字节序
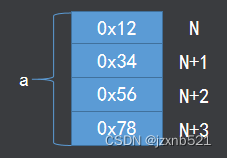
大端对齐 低地址存放高位,高地址存放低位 a = 0x12345678;
小端对齐 低地址存放低位,高地址存放高位 a = 0x12345678;
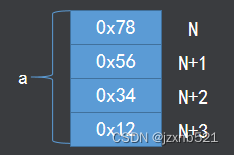
注:ARM一般使用小端对齐
ARM指令存储
1)处理器处于ARM状态时
所有指令在内存的起始地址必须是4的整数倍
PC值由其[31:2]决定,[1:0]位未定义
2)处理器处于Thumb状态时
所有指令在内存的起始地址必须是2的整数倍
PC值由其[31:1]决定,[0]位未定义
注:即指令本身是多少位在内存存储时就应该多少位对齐
ARM工作模式
ARM有8个基本的工作模式
- User 非特权模式,一般在执行上层的应用程序时ARM处于该模式
- FIQ 当一个高优先级中断产生后ARM将进入这种模式
- IRQ 当一个低优先级中断产生后ARM将进入这种模式
- SVC 当复位或执行软中断指令后ARM将进入这种模式
- Abort 当产生存取异常时ARM将进入这种模式
- Undef 当执行未定义的指令时ARM将进入这种模式
- System 使用和User模式相同寄存器集的特权模式
- Monitor 为了安全而扩展出的用于执行安全监控代码的模式
关于工作模式的理解:不同模式拥有不同权限 、不同模式执行不同代码 、不同模式完成不同的功能
ARM工作模式分类
按照权限:User为非特权模式(权限较低),其余模式均为特权模式(权限较高)
按照状态: FIQ、IRQ、SVC、Abort、Undef属于异常模式,即当处理器遇到异常后 会进入对应的模式
寄存器
概念: 寄存器是处理器内部的存储器,没有地址
作用: 一般用于暂时存放参与运算的数据和运算结果
分类: 包括通用寄存器、专用寄存器、控制寄存器
ARM寄存器
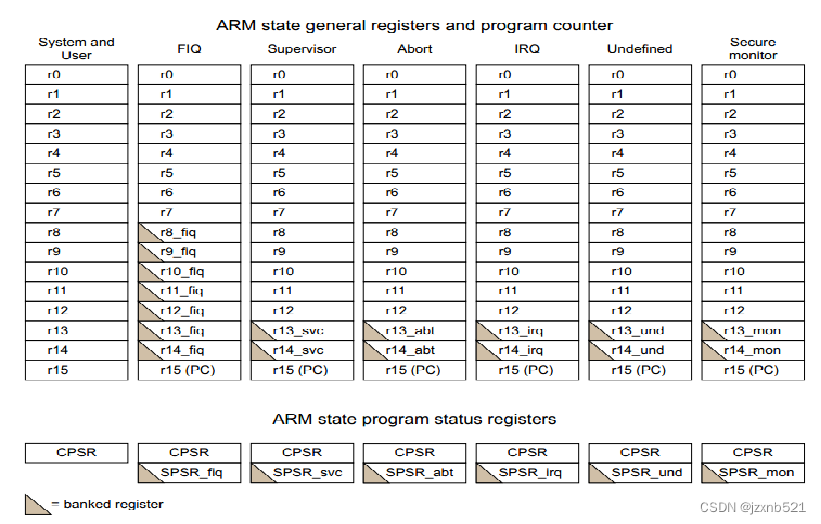
注:在某个特定模式下只能使用当前模式下的寄存器,一个模式下特有的寄存器其他模式下不可使用 (ARM共40个寄存器,不包含monitr的话就是37个)
专用寄存器
- R15(PC,Program Counter) 程序计数器,用于存储当前取址指令的地址
- R14(LR,Link Register) 链接寄存器,一般有以下两种用途:
- > 执行跳转指令(BL/BLX)时,LR会自动保存跳转指令下一条指令的地址,程序需要返回时将LR的值复制到PC即可实现
- > 产生异常/中断时,对应异常模式下的LR会自动保存被异常打断的指令的下一条指令的地址,异常处理结束后将LR的值复制到PC可实现程序返回
- R13(SP,Stack Pointer) 栈指针,用于存储当前模式下的栈顶地址
CPSR寄存器
CPSR(Current Program Status Register),当前程序状态寄存器(控制寄存器 32位 )
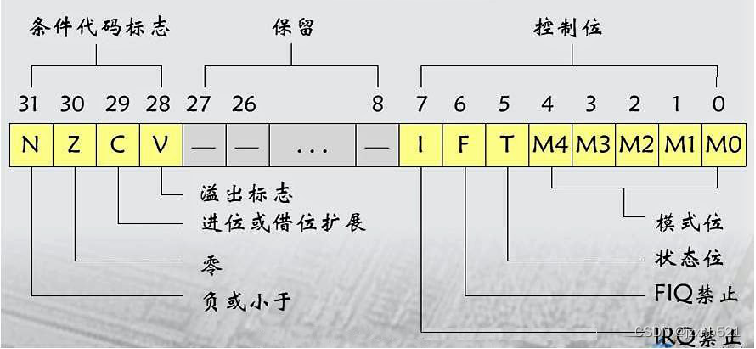
CPSR寄存器分为四个域,[31:24]为条件域用F表示、[23:16]为状 态域用S表示、[15:8]为预留域用X表示、[8:0]为控制域用C表示
Bit[4:0] (0-4模式位)
[10000]User [10001]FIQ [10010]IRQ [10011]SVC
[10111]Abort [11011]Undef [11111]System [10110]Monitor
Bit[5] (5 状态位)
[0]ARM状态 [1]Thumb状态
Bit[6] (6 FIQ中断位)
[0]开启FIQ [1]禁止FIQ
Bit[7] (7 IRQ中断位)
[0]开启IRQ [1]禁止IRQ
Bit[28] > 当运算器中进行加法运算且产生符号位进位时该位自动置1,否则为0
(有符号数) > 当运算器中进行减法运算且产生符号位借位时该位自动置0,否则为1
Bit[29] > 当运算器中进行加法运算且产生进位时该位自动置1,否则为0
(无符号数) > 当运算器中进行减法运算且产生借位时该位自动置0,否则为1
Bit[30] > 当运算器中产生了0的结果该位自动置1,否则为0
Bit[31] > 当运算器中产生了负数的结果该位自动置1,否则为0
关于寄存器:计算机基础知识——认识寄存器 源自博主:简说Linux内核
ARM异常处理
异常
概念 :处理器在正常执行程序的过程中可能会遇到一些不正常的事件发生,这时处理器就要将当前的程序暂停下来转而去处理这个异常的事件,异常事件处理完成之后再返回到被异常打断的点继续执行程序。
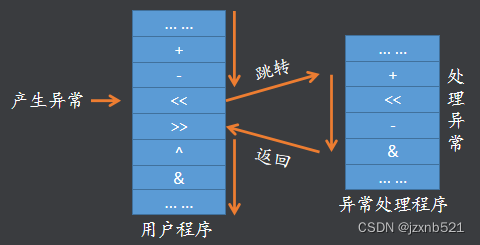
异常处理机制
不同的处理器对异常的处理的流程大体相似,但是不同的处理器在具体实现的机制上有所不同;比如处理器遇到哪些事件认为是异常事件遇到异常事件之后处理器有哪些动作、处理器如何跳转到异常处理程序如何处理异常、处理完异常之后又如何返回到被打断的程序继续执行等我们将这些细节的实现称为处理器的异常处理机制
ARM异常源
概念 :导致异常产生的事件称为异常源
ARM异常源 :
- FIQ 快速中断请求引脚有效
- IRQ 外部中断请求引脚有效
- Reset 复位电平有效
- Software Interrupt 执行swi指令
- Data Abort 数据终止
- Prefetch Abort 指令预取终止
- Undefined Instruction 遇到不能处理的指令
ARM异常模式
在ARM的基本工作模式中有5个属于异常模式,即ARM遇到异常后会切 换成对应的异常模式

ARM异常响应
ARM产生异常后的动作(自动完成)
1.拷贝CPSR中的内容到对应异常模式下的SPSR_<mode>
2.修改CPSR的值
2.1.修改中断禁止位禁止相应的中断
2.2.修改模式位进入相应的异常模式
2.3.修改状态位进入ARM状态
3.保存返回地址到对应异常模式下的LR_<mode>
4.设置PC为相应的异常向量(异常向量表对应的地址)
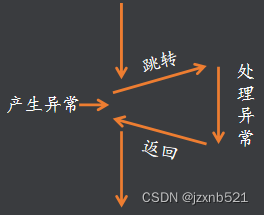
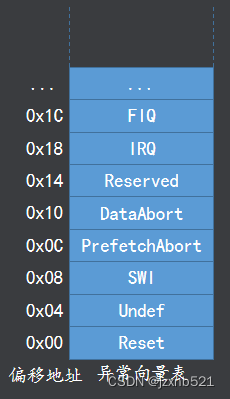
异常向量表
- > 异常向量表的本质是内存中的一段代码
- > 表中为每个异常源分配了四个字节的存储空间
- > 遇到异常后处理器自动将PC修改为对应的地址
- > 因为异常向量表空间有限一般我们不会再这里写异常处理程序,而是在对应的位置写一条跳转指令使其跳转到指定的异常处理程序的入口
注:ARM的异常向量表的基地址默认在0x00地址 , 但可以通过配置协处理器来修改其地址
异常返回
ARM异常返回的动作(自己编写)
1.将 SPSR_<mode> 的值复制给CPSR,使处理器恢复之前的状态
2.将 LR_<mode> 的值复制给PC,使程序跳转回被打断的地址继续执行
IRQ异常举例
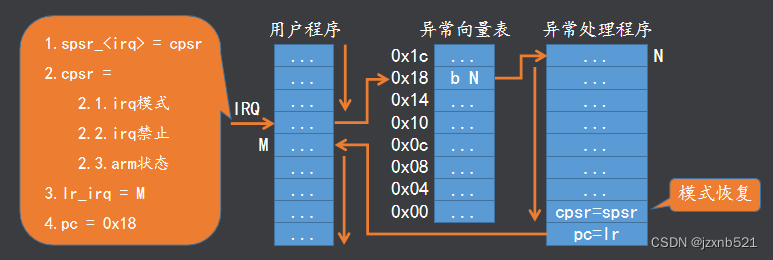
注:整个过程CPSR保存的永远是当前程序运行状态,SPSR只是异常时对原来的CPSR进行备份
异常优先级
多个异常同时产生时的服务顺序:(高优先级可以打断低优先级)
高:Reset > Data Abort > FIQ > IRQ > Prefetch Abort >Software Interrupt >Undefined instruction 低
FIQ和IRQ
FIQ的响应速度比IRQ快
- FIQ在异常向量表位于最末 ,可直接把异常处理写在异常向量表之后,省去跳转
- FIQ模式有5个私有寄存器(R8-R12),执行中断处理程序前无需压栈保存寄存器,可直接处理中断
- FIQ的优先级高于IRQ
- 两个中断同时发生时先响应FIQ
- FIQ可以打断IRQ,但IRQ不能打断FIQ
ARM微架构
指令流水线
一条指令的执行过程可分解为若干阶段,每个阶段由相应的功能部件完成。如果将各阶段视为相应的流水段,则指令的执行过程就构成了一条指令流水线。
假设一条指令的执行过程分为如下5个阶段(也称功能段或流水段):
- 取指(IF):从指令存储器或缓存(Cache)中取指令。
- 译码/读寄存器(ID):操作控制器对指令进行译码,同时从寄存器堆中取操作数。
- 执行/计算地址(EX):执行运算操作或计算地址。
- 访存(MEM):对存储器进行读写操作。
- 写回(WB):将指令执行结果写回寄存器堆。
把k+1条指令的取指阶段提前到第k条指令的译码阶段,从而将第k+1条指令的译码阶段与第k条指令的执行阶段同时进行,如图所示。
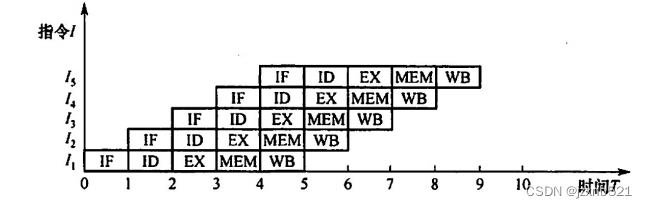
ARM指令流水线
- ARM7采用3级流水线
- ARM9采用5级流水线
- Cortex-A9采用8级流水线
注:虽然流水线级数越来越多,但都是在三级流水线的基础上进行了细分
PC的作用(取指)
不管几级流水线,PC指向的永远是当前正在取指的指令,而当前正在执行的指令的地址为PC-8
引入流水线
指令流水线机制的引入确实能够大大的提升指令执行的速度 但在实际执行程序的过程中很多情况下流水线时是无法形成的 比如芯片刚上电的前两个周期、执行跳转指令后的两个周期等 所以指令流水线的引入以及优化只能使平均指令周期不断的接 近1而不可能真正的达到1,且流水线级数越多芯片设计的复杂 程度就越高,芯片的功耗就越高。
多核处理器
多核处理器即一个SOC中集成了多个CPU核,
作用: 不同的线程可以运行在不同的核心中做到真正的并发
资源 : 多核处理器共用外设与接口资源

↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑理论部分↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
二、 ARM指令集仿真
汇编
- 每条汇编都会唯一对应一条机器码,且CPU能直接识别和执行,即汇编中所有的指令都是CPU能够识别和执行的
- 汇编中寄存器的使用、栈的分配与使用、程序的调用、参数的传递等 都需要自己维护
C语言
- 每条C语句都要被编译器编译成若干条汇编指令才能被CPU识别和执行,即C语句中的指令CPU不一定能直接识别,需要编译器进行“翻译”
- C中寄存器的使用、栈的分配与使用、程序的调用、参数的传递等 都是编译器来分配和维护
Keil
Keil MDK 是用于基于 ARM Cortex-M 微控制器的完整软件开发环境。它集成了uVision IDE C/C++编译器、调试器以及其他中间组件,支持众多芯片供应商,易于学习和使用。
ARM指令集概述
汇编的中符号
- 指令:能够编译生成一条32bit机器码,并且能被cPu识别和执行
- 伪指令:本身不是指令,编译器可以将其替换成若干条指令
- 伪操作:不会生成指令,只是在编译阶段告诉编译器怎么编译
ARM指令集
- 数据处理指令:进行数学运算,逻辑运算
- 跳转指令:实现程序跳转,本质就是修改了PC寄存器
- Load/Store指令: 访问(读写)内存
- 状态寄存器传送指令:用于访问(读写)CPSR寄存器
- 软中断指令:给CPU发送中断信号 触发软中断
- 协处理器指令:操作协处理器的指令
汇编指令
1.数据处理指令:数学运算、逻辑运算
1.1数据搬移指令
MOV R1,#1
@R1 =1
MOV R2, R1
@ R2 = R1
MVN R0, #0xFF //MVN:先给数按位取反再去搬移
@ R0 = ~0xFF /R0 = 0xFFFFFF00(32位)
1.2立即数
- 立即数的本质就是包含在指令当中的数,属于指令的一部分
- 立即数的优点:取指的时候就可以将其读取到CPU,不用单独去内存读取,速度快
- 立即数的缺点:不能是任意的32位的数字,有局限性
MOV R0, #0x12345678 //error 长度溢出 机器码共32位 不能光立即数就占了32位
MOV R0, #0x12 //->机器码 E3A00012
1.3编译器替换
MOV R0, #0xFFFFFFFF
(编译器内部把上述指令换成了MVN R0,#0x00000000 与上同理)
数据运算指令基本格式
《操作码》《目标寄存器》《第一操作寄存器》《第二操作数》
- 操作码 : 指示执行哪种运算
- 目标寄存器: 存储运算结果
- 第一操作寄存器: 第一个参与运算的数据(只能是寄存器)
- 第二操作数: 第二个参与运算的数据(可以是寄存器或立即数)
加法指令
MOV R2, #5
MOV R3, #3
ADD R1, R2, R3
@R1 = R2 + R3
ADD R1, R2, #5
@ R1 = R2 + 5
减法指令
SUB R1, R2, R3
@ R1 = R2 - R3
SUB R1, R2, #3
@ R1 = R2 - 3
逆向减法指令
RSB R1, R2, #3
@ R1 = 3 - R2
乘法指令
MUL R1, R2, R3
@ R1 = R2 * R3
@ 乘法指令只能是两个寄存器相乘
按位与指令
AND R1, R2, R3
@ R1 = R2 & R3
按位或指令
ORR R1, R2, R3
@ R1 = R2 | R3
按位异或指令
EOR R1, R2, R3
@ R1 = R2 ^ R3
左移指令
LSL R1, R2, R3
@ R1 = (R2 << R3) R1 是R2左移R3位如:R2 = 0xF0(1111 0000) R3=0x02 R1=0x3C0(0011 1100 0000)
右移指令
LSR R1, R2, R3
@ R1 = (R2 >> R3)
位清零指令(BIC)
MOV R2, #0xFF
BIC R1, R2, #0x0F@最后R1= 0xF0 把R2最后四位清零放到R1中
第二操作数中的哪一位为1,就将第一操作寄存器的中哪一位清零,然后将结果写入目标寄存器
格式扩展
MOV R2, #3
MOV R1, R2, LSL #1
@ R1 = (R2 << 1)
数据运算指令对条件位(N、Z、C、V)的影响
默认情况下数据运算不会对条件位产生影响,在指令后加后缀”S“才可以影响
如:SUBS
带进位的加法指令:
两个64位的数据做加法运算:
- 第一个数的低32位放在 R1
- 第一个数的高32位放在 R2
- 第二个数的低32位放在 R3
- 第二个数的高32位放在 R4
- 运算结果的低32位放在 R5
- 运算结果的高32位放在 R6
@ 第一个数
@ 0x00000001 FFFFFFFF
@ 第二个数
@ 0x00000002 00000005
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x00000001
@ MOV R3, #0x00000005
@ MOV R4, #0x00000002
@ ADDS R5, R1, R3 //引入后缀S 以观察进位C
@ ADC R6, R2, R4 //ADC 带进位加法 本质是使用进位标志位
@ 本质:R6 = R2 + R4 + 'C'
带借位的减法指令:
@ 第一个数
@ 0x00000002 00000001
@ 第二个数
@ 0x00000001 00000005
@ MOV R1, #0x00000001
@ MOV R2, #0x00000002
@ MOV R3, #0x00000005
@ MOV R4, #0x00000001
@ SUBS R5, R1, R3
@ SBC R6, R2, R4
@ 本质:R6 = R2 - R4 - '!C'
2.跳转指令
实现程序的跳转,本质就是修改了PC寄存器
@ 方式一:直接修改PC寄存器的值(不建议使用,需要自己计算目标指令的绝对地址)
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV PC, #0x18
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
@ 方式二:不带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ B FUNC
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
@ 方式三:带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址,
@同时将跳转指令下一条指令的地址存储到LR寄存器
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ BL FUNC
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
@ MOV PC, LR
@ 程序返回ARM指令的条件码
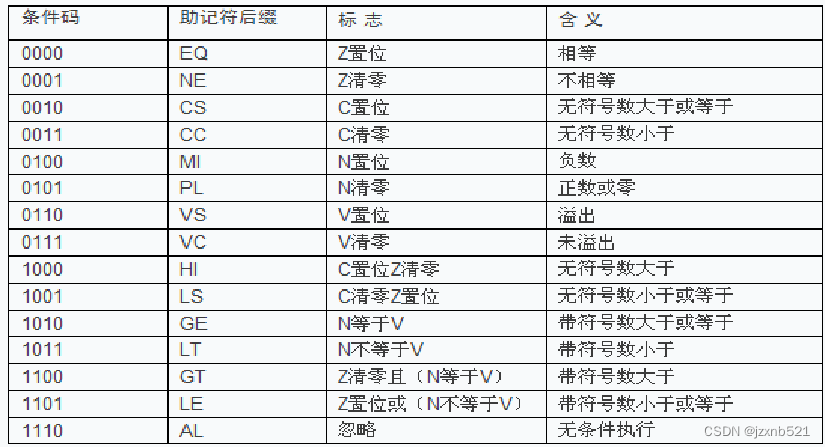
比较指令(CMP)
CMP指令的本质就是一条减法指令(SUBS),只是没有将运算结果存入目标寄存器
@ MOV R1, #1
@ MOV R2, #2
@ CMP R1, R2
@ BEQ FUNC
@ 执行逻辑:if(EQ){B FUNC} 本质:if(Z==1){B FUNC}
@ BNE FUNC
@ 执行逻辑:if(NQ){B FUNC} 本质:if(Z==0){B FUNC}
@ MOV R3, #3
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ ARM指令集中大多数指令都可以带条件码后缀
@ MOV R1, #1
@ MOV R2, #2
@ CMP R1, R2
@ MOVGT R3, #3
@ 练习:用汇编语言实现以下逻辑
@ int R1 = 9;
@ int R2 = 15;
@ START:
@ if(R1 == R2)
@ {
@ STOP();
@ }
@ else if(R1 > R2)
@ {
@ R1 = R1 - R2;
@ goto START;
@ }
@ else
@ {
@ R2 = R2 - R1;
@ goto START;
@ }
@ 练习答案
@ MOV R1, #9
@ MOV R2, #15
@ START:
@ CMP R1,R2
@ BEQ STOP
@ SUBGT R1, R1, R2
@ SUBLT R2, R2, R1
@ B START
@ STOP:
@ B STOP3 Load/Srore指令:访问(读写)内存(LD **/ ST**)
@ 写内存
@ MOV R1, #0xFF000000
@ MOV R2, #0x40000000
@ STR R1, [R2]
@ 将R1寄存器中的数据写入到R2指向的内存空间
@小端对齐 40 : 00
41 : 00
42 : 00
43 : FF
@ 读内存
@ LDR R3, [R2]
@ 将R2指向的内存空间中的数据读取到R3寄存器
@ 读/写指定的数据类型
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STRB R1, [R2]
@ 将R1寄存器中的数据的Bit[7:0]写入到R2指向的内存空间(一个字节)
@ STRH R1, [R2]
@ 将R1寄存器中的数据的Bit[15:0]写入到R2指向的内存空间(一个半字)
@ STR R1, [R2]
@ 将R1寄存器中的数据的Bit[31:0]写入到R2指向的内存空间(一个字)
@ LDR指令同样支持以上后缀寻址方式
寻址方式就是CPU去寻找操作数的方式
寻址方式分为指令寻址和数据寻址。
1.指令寻址
指令寻址分为顺序寻址和跳跃寻址。
顺序寻址是通过程序计数器PC加1自动形成下一条指令的地址。
跳跃寻址是通过转移类指令实现。
2.数据寻址
在指令字中必须设置一个字段来表明是哪种寻址方式。并且指令的地址字段通常都不表示操作数的有效地址,我们把它称为形式地址,记作 A ,有效地址记作 EA,由寻址方式和形式地址共同确定。
指令的格式通常为:

为了方便研究,假设机器字长、存储字长、指令字长都相同。
2.1立即寻址
@ MOV R1, #1
@ ADD R1, R2, #1
立即寻址的特点是操作数就在指令内,因此,也叫做立即数,采用补码的形式存放,在执行阶段不访问内存。
但是指令的位数是有限的,这也就限制了立即数的范围。

2.2 直接寻址
直接寻址的指令字中的形式地址A就是操作数的有效地址EA,即 EA=A;
他的优点就是,从指令中可以直接的得到操作数的有效地址,且只访问内存一次。缺点呢就是A的位数限制了操作数的寻址范围,而且,必须修改A的值才能修改A的地址。

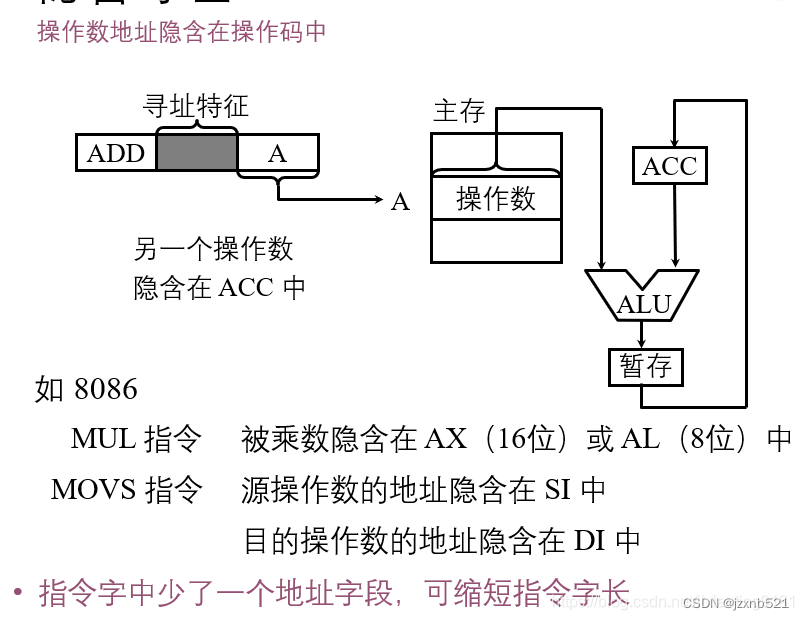
2.3 隐含寻址
隐含,就是不明显。隐含寻址就是不明显的给出操作数的地址,操作数的地址隐含于操作数或某个寄存器内,例如,一地址格式的加法指令只给出一个操作数的地址,另外一个操作数的就隐含在ACC累加器中,这样,累加器的地址就是操作数的地址。
这种隐含寻址的方式在指令字中就少了一个地址,有利于缩短指令字长。
2.4 间接寻址
间接寻址的操作数的有效地址是由指令字中的形式地址给出的,也就是指令字中给出的是真实地址的地址,即EA=(A);
间接寻址的优点有,扩大了操作数的寻址范围,便于编制程序。
例如:
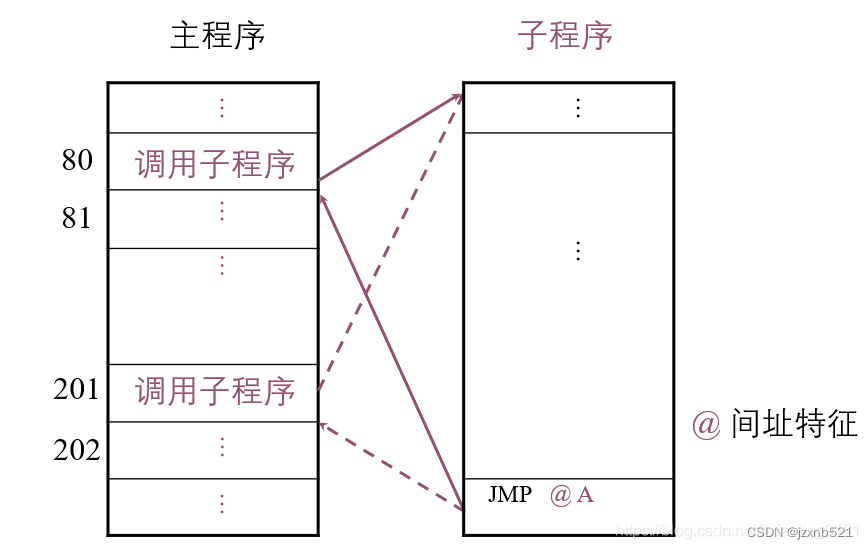
图中表示在调用子程序前先将返回地址保存在子程序最末端指令形式地址A内便可以准确的返回断点处。
2.5 寄存器寻址
@ ADD R1, R2, R3
寄存器直接寻址指令字中的内容是寄存器的编号,操作数在指定编号的寄存器里。
由于寄存器直接寻址不访问内存,执行的速度加快,而且,只需指定寄存器的编号就可以了(计算机内寄存器数量有限),所需指令字较短,节省了储存空间。因此寄存器寻址在计算机中得到广泛应用。

寄存器移位寻址
@ MOV R1, R2, LSL #1
先给R2左移一位然后搬移至R1
2.6 寄存器间接寻址
@ STR R1, [R2]
寄存器间接寻址也是指定寄存器编号,但是寄存器内存放的并不是操作数,而是操作数的有效地址(相当于指针)。
有效地址在寄存器中,操作数在存储器中,执行阶段访存,但访存比间接寻址少一次,便于编制循环程序

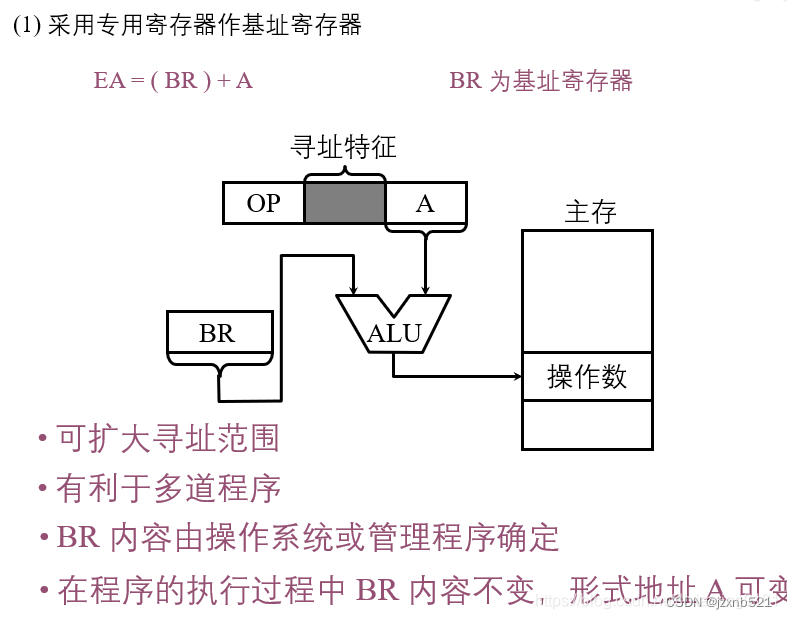
2.7 基址寻址
基址寻址需要有基址寄存器BR,操作数的有效地址等于形式地址加上基址寄存器中的内容(基地址)。
基址寄存器分为隐式和显式。隐式是指计算机内设有一个专门的,用户不必明显指出该基址寄存器,只需由寻址特征位反应基址寻址就可以。而显式是在一组通用寄存器内由用户指定一个基址寄存器存放基地址。
基址寻址中的BR由系统或者管理程序根据主存的使用情况分配初始值,便可将用户程序的逻辑地址转化为主存的物理地址(实际地址)。
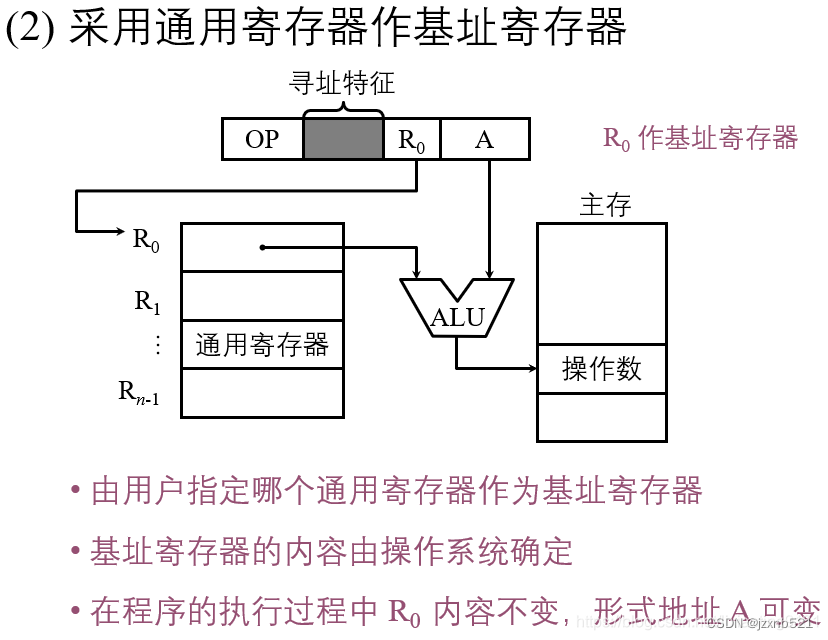
2.8 变址寻址
变址寻址与基址寻址极为相似,有效地址等于指令字中的形式地址与变址寄存器IX的内容相加 。
基址寻址主要用于为程序或数据分配内存空间,故基址寄存器的内容通常由操作系统或管理程序确定,在程序的执行过程中其值是不可变的,而指令字中的形式地址A是可变的,在变址寻址中,变址寄存器的内容是用户设定的,在程序执行过程中其值可变,而指令字中的A是不可变的。
变址寻址主要用于处理数组问题,在数组处理过程中,可设定A为数组的首地址,不断改变变址寄存器的IX内的内容,便可以得到数组中任一数据中的地址,特别适合编制循环程序。
基址加变址寻址
MOV R1, #0xFFFFFFFF
MOV R2, #0x40000000
MOV R3, #4
STR R1, [R2,R3]
@ 将R1寄存器中的数据写入到R2+R3指向的内存空间
STR R1, [R2,R3,LSL #1]
@ 将R1寄存器中的数据写入到R2+(R3<<1)指向的内存空间
基址加变址寻址的索引方式
@ 前索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2,#8]
@ 将R1寄存器中的数据写入到R2+8指向的内存空间
@ 后索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2],#8
@ 将R1寄存器中的数据先写入到R2指向的内存空间,然后R2自增8@执行结束:地址 0x40000000 里是 0xFFFFFFFF R2 里面存储 0x40000008
@ 自动索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2,#8]!
@ 将R1寄存器中的数据写入到R2+8指向的内存空间,然后R2自增8
@执行结束:地址 0x40000008 里是 0xFFFFFFFF R2 里面存储 0x40000008
@ 以上寻址方式和索引方式同样适用于LDR
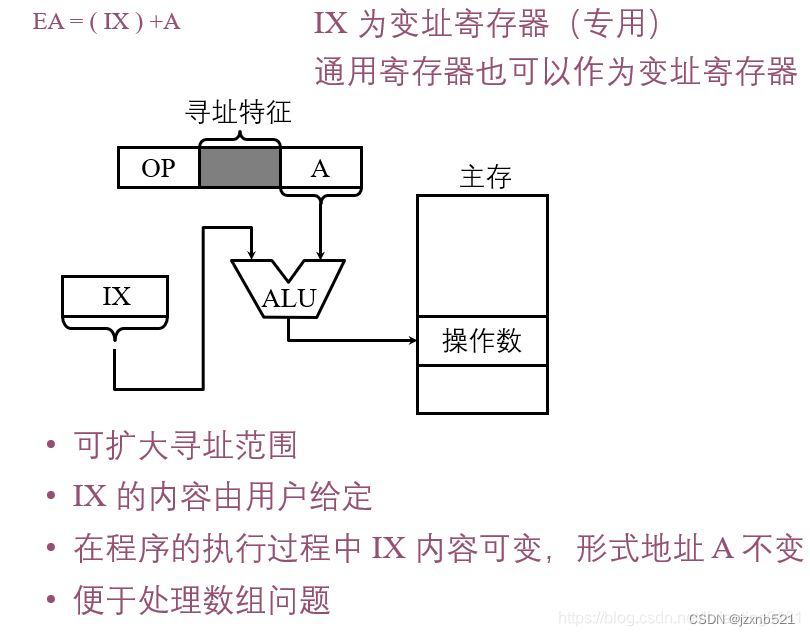
2.9 相对寻址
相对寻址的有效地址是将程序计数器PC内容与指令字中形式地址A相加而成。
如图可见,操作数的位置与当前指令的位置有一段距离A。
相对寻址最大的特点就是转移地址不固定,他随PC值的变化而变化,因此,无论主程序在哪段区域,都可正常运行,对编写浮动程序特别有利。
4. 多寄存器内存访问指令
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STM R11,{R1-R4}
@ 将R1-R4寄存器中的数据写入到以R11为起始地址的内存空间中
@ LDM R11,{R6-R9}
@ 将以R11为起始地址的内存空间中的数据读取到R6-R9寄存器中
当寄存器编号不连续时,使用逗号分隔
STM R11,{R1,R2,R4}
不管寄存器列表中的顺序如何,存取时永远是低地址对应小编号的寄存器
STM R11,{R3,R1,R4,R2} @结果同 R1 R2 R3 R4 的顺序
自动索引照样适用于多寄存器内存访问指令(方便下一次执行存储)
STM R11!,{R1-R4} @存储完之后R11的值变为0x40000030(自增16字节(4*4))
多寄存器内存访问指令的寻址方式
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STMIA R11!,{R1-R4}
@ 先存储数据,后增长地址
@ STMIB R11!,{R1-R4}
@ 先增长地址,后存储数据
@ STMDA R11!,{R1-R4}
@ 先存储数据,后递减地址
@ STMDB R11!,{R1-R4}
@ 先递减地址,后存储数据
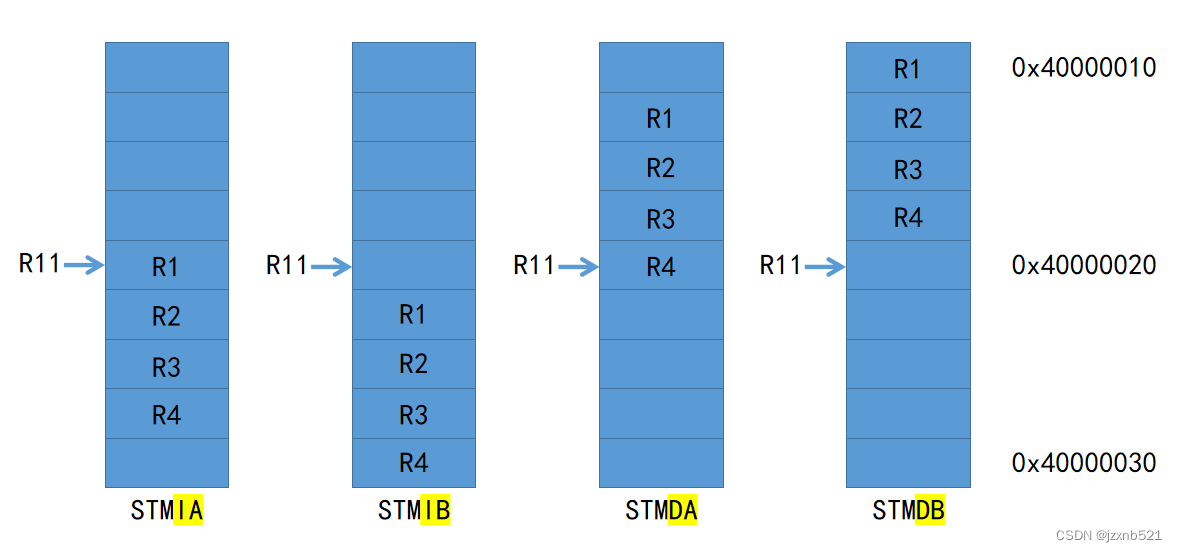
应用场合:压栈与出栈
栈的种类与使用
栈的本质就是一段内存,程序运行时用于保存一些临时数据
如局部变量、函数的参数、返回值、以及程序跳转时需要保护的寄存器等
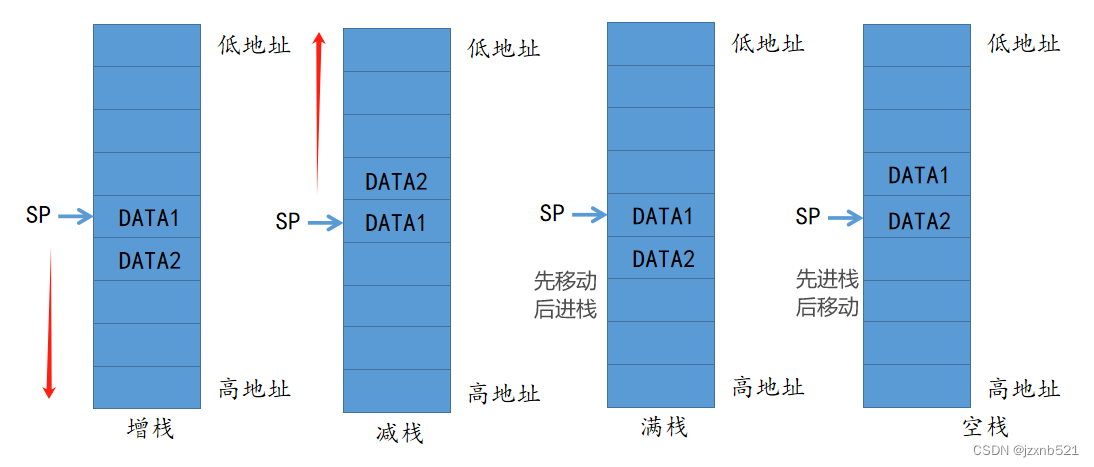
栈的分类
增栈:压栈时栈指针越来越大,出栈时栈指针越来越小
减栈:压栈时栈指针越来越大,出栈时栈指针越来越小
满栈:栈指针指向最后一次压入到栈中的数据,压栈时需要先移动栈指针到相邻位置然后再压栈
空栈:栈指针指向最后一次压入到栈中的数据的相邻位置,压栈时可直接压栈,之后需要将栈指针移动到相邻位置
栈分为空增(EA)、空减(ED)、满增(FA)、满减(FD)四种
ARM处理器一般使用满减栈(原理:STMDB)进栈,(原理:LDMIA)出栈
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STMFD R11!,{R1-R4}
@ LDMFD R11!,{R6-R9}@写程序时直接使用后缀FD可知为满减栈(编译器内部会自动替换为STMDB/LDMIA)
栈的应用举例
1.叶子函数的调用过程举例(不调用其他函数的函数就是叶子函数)
MOV SP, #0x40000020 @ 初始化栈指针
MIAN:
MOV R1, #3
MOV R2, #5
BL FUNC
ADD R3, R1, R2
B STOP
FUNC:
STMFD SP!, {R1,R2} @ 压栈保护现场 R1写入18 R2写入1C
MOV R1, #10
MOV R2, #20
SUB R3, R2, R1
LDMFD SP!, {R1,R2} @ 出栈恢复现场 并且栈指针SP重新指向#0x40000020
MOV PC, LR
STOP:
B STOP @死循环,防止程序跑飞
.end @汇编程序的结束2.非叶子函数的调用过程举例(调用了其他函数的函数就是叶子函数)
MOV SP, #0x40000020
MIAN:
MOV R1, #3
MOV R2, #5
BL FUNC1
ADD R3, R1, R2
B STOP
FUNC1:
STMFD SP!, {R1,R2,LR} @内存1C存的LR
MOV R1, #10
MOV R2, #20
BL FUNC2
SUB R3, R2, R1
LDMFD SP!, {R1,R2,LR}
MOV PC, LR
FUNC2:
STMFD SP!, {R1,R2} @内存0C存的10 内存10存的20
MOV R1, #7
MOV R2, #8
MUL R3, R1, R2
LDMFD SP!, {R1,R2}
MOV PC, LR
@ 执行叶子函数时不需要对LR压栈保护,执行非叶子函数时需要对LR压栈保护局部变量存在栈中 不初始化会出现野数据 因为存于栈中的数据出栈时不会清0
状态寄存器传送指令:访问(读写)CPSR寄存器
@ 读CPSR
MRS R1, CPSR
@ R1 = CPSR
@ 写CPSR
MSR CPSR, #0x10
@ CPSR = 0x10
@ 在USER模式下不能随意修改CPSR,因为USER模式属于非特权模式
MSR CPSR, #0xD3
***软中断指令:触发软中断 ***
@ 异常向量表
B MAIN
B .
B SWI_HANDLER
B .
B .
B .
B .
B .
@ 应用程序
@ MAIN:
MOV SP, #0x40000020 @初始化SVC模式下的栈指针
MSR CPSR, #0x10 @ 切换成USER模式,开启FIQ、IRQ
MOV R1, #1
MOV R2, #2
SWI #1 @ 触发软中断异常
ADD R3, R2, R1
B STOP
@ 异常处理程序
@ SWI_HANDLER:
STMFD SP!,{R1,R2,LR} @ 压栈保护现场
MOV R1, #10
MOV R2, #20
SUB R3, R2, R1
LDMFD SP!,{R1,R2,PC}^ @ 出栈恢复现场
@ 将压入到栈中的LR(返回地址)出栈给PC,实现程序的返回
@ ‘^’表示出栈的同时将SPSR的值传递给CPSR,实现CPU状态的恢复‘^’表示出栈的同时将SPSR的值传递给CPSR,实现CPU状态的恢复
应用:SWI在Linux内核内部用的较多(系统调用) 使当前从用户态切换为内核态
用户:(user状态) a++; write();[使用系统调用,告诉系统内核帮我写磁盘]
Linux内核:write函数内部有一个SWI指令,执行后触发软终端切换成SVC模式,能够向下读写磁盘内容。
硬盘:***@@@****
协处理器指令:操控协处理器的指令
1.协处理器数据运算指令
CDP
2.协处理器存储器访问指令
STC 将协处理器中的数据写入到存储器
LDC 将存储器中的数据读取到协处理器
3.协处理器寄存器传送指令
MRC 将协处理器中寄存器中的数据传送到ARM处理器中的寄存器
MCR 将ARM处理器中寄存器中的数据传送到协处理器中的寄存器
伪指令
本身不是指令,编译器可以将其替换成若干条等效指令
空指令(消耗一个指令周期时间)
NOP
LDR即可作为指令、亦可做为伪指令
指令(LDR)
LDR R1, [R2]
@ 将R2指向的内存空间中的数据读取到R1寄存器
伪指令(LDR)
LDR R1, =0x12345678
@ R1 = 0x12345678
@ LDR伪指令可以将任意一个32位的数据放到一个寄存器@ 类似MOV 但是MOV格式里的立即数不能为32位数
LDR R*,
LDR R1, =STOP
@ 将STOP表示的地址写入R1寄存器
LDR R1, STOP
@ 将STOP地址中的内容写入R1寄存器(如同*p)
伪操作
不会生成代码,只是在编译之前告诉编译器怎么编译
GNU的伪操作一般都以‘.’开头
.global symbol
@ 将symbol声明成全局符号
.local symbol
@ 将symbol声明成局部符号
.equ DATA, 0xFF
MOV R1, #DATA@把FF放到R1
.macro FUNC
MOV R1, #1
MOV R2, #2
.endm
FUNC
.if 0
MOV R1, #1
MOV R2, #2
.endif
.rept 3
MOV R1, #1
MOV R2, #2
.endr@生成三段重复的中间代码
@ .weak symbol
@ 弱化一个符号,即告诉编译器即便没有这个符号也不要报错
.weak func
B func
@ .word VALUE
@ 在当前地址申请一个字的空间并将其初始化为VALUE
@ MOV R1, #1
@ .word 0xFFFFFFFF
@ MOV R2, #2
@ .byte VALUE
@ 在当前地址申请一个字节的空间并将其初始化为VALUE
@ MOV R1, #1
@ .byte 0xFF
@ .align N
@ 告诉编译器后续的代码2的N次方对齐
.align 4 (16字节对齐)
@ MOV R2, #2
.arm
@ 告诉编译器后续的代码是ARM指令
.thumb
@ 告诉编译器后续的代码是Thumb指令、
.text
@ 定义一个代码段.end
@汇编结束
.data
@ 定义一个数据段
@ .space N, VALUE
@ 在当前地址申请N个字节的空间并将其初始化为VALUE
@ MOV R1, #1
@ .space 12, 0x12
@ MOV R2, #2
@ 不同的编译器伪操作的语法不同
C与汇编的混合编程
C/汇编 混合编程的原则:在那种语言环境下符合哪种语言的语法规则
- 在汇编中将C中的函数当做标号处理
- 在C中将汇编中的标号当做函数处理
- 在C中内联的汇编当做C的语句来处理
1. 方式一:汇编语言调用(跳转)C语言
MOV R1, #1
MOV R2, #2
BL func_c
MOV R3, #3
2. 方式二:C语言调用(跳转)汇编语言
.global FUNC_ASM
FUNC_ASM:
MOV R4, #4
MOV R5, #5C中:
void func_c(void){
int a;
a++;
FUNC_ASM();
a--;
}
3. C内联(内嵌)汇编
即直接在C语言中插入汇编语句
void func_c(void){
int a;a++;
asm{
"MOV R6,#6\n"
"MOV R7,#7\n"
}
FUNC_ASM();
a--;
}
ATPCS协议(ARM-THUMB Procedure Call Standard)
作用:标准化编译器 为了使单独编译的C语言程序和汇编程序之间能够相互调用,必须为子程序之间的调用规定一定的规则
ATPCS协议主要内容
1.栈的种类
1.1 使用满减栈
2.寄存器的使用
2.1 R15用作程序计数器,不能作其他用途
2.2 R14用作链接寄存器,不能作其他用途
2.3 R13用作栈指针,不能作其他用途
2.4 当函数的参数不多于4个时使用R0-R3传递,当函数的参数多于4个时,多出的部分用栈传递
2.5 函数的返回值使用R0传递
2.6 其它寄存器主要用于存储局部变量
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









