







****公司笔试题整理- 2024/2/21
sizeof结构体整理
-
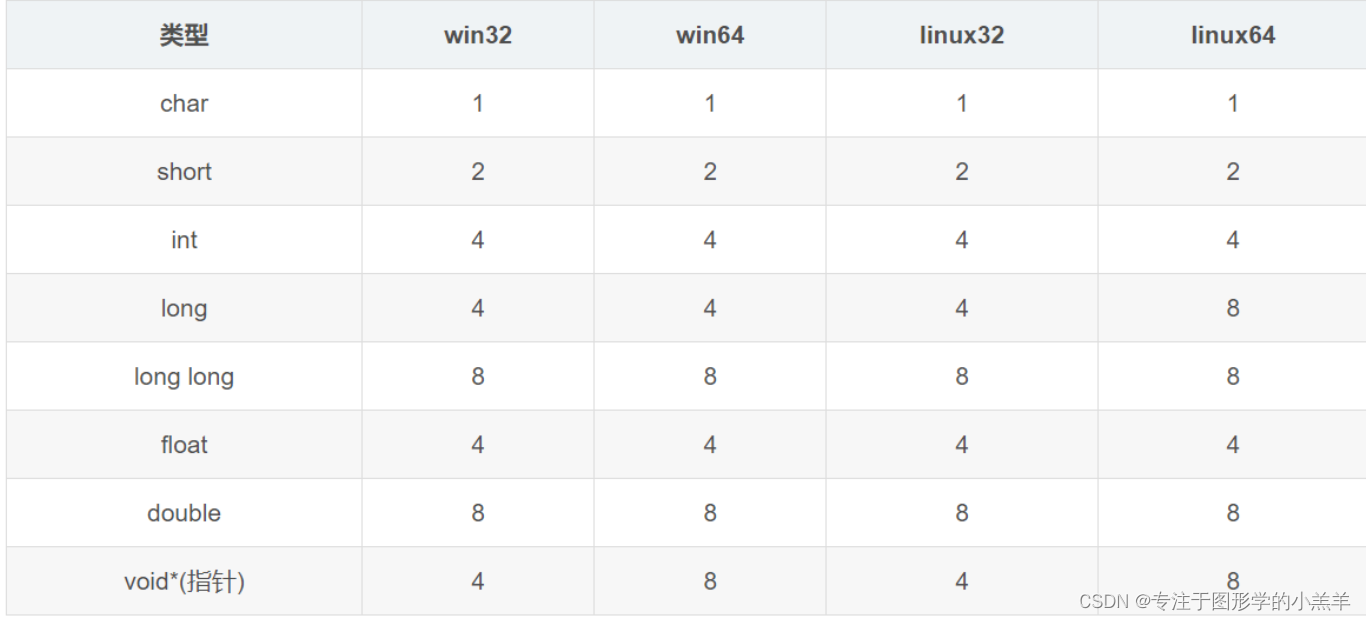
在大多数系统中,通常有以下规律:
char类型通常占用1字节。short类型通常占用2字节。- 指针(
int*,char*,long*等)通常在32位系统上占用4字节,在64位系统上占用8字节。 long long类型通常占用8字节。
但是需要大部分时候考虑内存对齐,不同的顺序可能导致内存对齐而不同内存大小,成员的排列顺序对内存布局是有影响的。成员的大小和对齐要求可能导致结构体中的填充字节,从而影响整体的大小。
内存对齐规则
-
对结构体的成员,第一个数据位于偏移为0的位置,以后每个数据成员的偏移量必须是成员对齐模数的倍数。
-
为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的偏移是否为成员对齐模数的整数倍,若是,则存放本成员,反之,则在本成员与上一成员之前填充一定的字节,从而达到整数倍的要求
-
在数据成员完成自身的对齐后,结构体本身也要进行对齐。意思是该结构体的大小必须是结构体的对齐模数的整数倍。如果其大小不是,那么则在最后一个成员的后面填充字节。
数据对齐
- 基本数据类型的对齐:
char可以在任何地址开始。short通常要求在2的倍数地址开始。int通常要求在4的倍数地址开始。long long通常要求在8的倍数地址开始。
- 结构体对齐:
- 结构体的对齐要求通常是其成员中最大对齐要求的倍数。
- 编译器可能在结构体成员之间插入填充以满足对齐要求。
- 数组对齐:
- 数组的对齐要求通常是其元素类型的对齐要求。
- 指针对齐:
- 指针的对齐要求通常与其指向的数据类型的对齐要求相同。
案例解析
typedef struct{
int i;
char c;
short s;
char buf[21];
}s; //32
/*
由于i是4个字节,然后c是一个字节,s是2个字节,但是s开头必须是2的倍数,所有截至是8,然后8 + 21,就是29,整体是4的倍数,然后就是32
*/
#include <stdio.h>
typedef struct {
char str;
short x;
int num;
double xx;
} s1;
int main() {
size_t size = sizeof(s1);
printf("Size of struct s1: %zu bytes\n", size);
return 0;
}
/*
在32位平台上,s1 的大小可能是 1(char) + 1(padding) + 2(short) + 4(int) + 4(double) = 12 字节。这个结果可能因为编译器和平台的不同而有所变化。在32位平台上,double 类型的对齐要求是4字节,因此填充的字节数相对较小。
*/
#include <stdio.h>
typedef struct {
unsigned char ucld : 1;
unsigned char ucpara0 : 2;
unsigned char ucstate : 6;
unsigned char uctail : 4;
unsigned char ucavail;
unsigned char uctail2 : 4;
unsigned long uldate;
} s;
int main() {
size_t size = sizeof(s);
printf("Size of struct s: %zu bytes\n", size);
return 0;
}
/*
这个程序将输出结构体s的大小。在这个结构体中,ucld占1位,ucpara0占2位,ucstate占6位,uctail占4位,ucavail占8位,uctail2占4位,uldate占32位。根据位域的规则,位域的大小通常是按照最大需要的位数来分配。
*/
C/C++ 字符串赋值方式
#include <iostream>
#include <cstring>
int main() {
// 使用字符串字面值初始化
char str1[] = "Hello, World!";
// 使用strcpy函数赋值
char str2[15];
strcpy(str2, "Copy this!");
// 使用循环逐个赋值
char str3[15];
for (int i = 0; i < 13; i++) {
str3[i] = 'A' + i;
}
str3[13] = '\0'; // 字符串末尾需要添加 null 终止字符
// 使用字符串拷贝函数
char str4[15];
strncpy(str4, "Copy with limit", 14); // 指定拷贝长度
// 使用字符串赋值运算符
char str5[15];
str5 = "Assign this!"; // 错误,不能直接赋值
// 使用string类
#include <string>
std::string str6 = "Hello from string!";
// 使用字符数组的部分赋值
char str7[15] = {'H', 'e', 'l', 'l', 'o', '\0'}; // 部分初始化
// 输出结果
std::cout << "str1: " << str1 << std::endl;
std::cout << "str2: " << str2 << std::endl;
std::cout << "str3: " << str3 << std::endl;
std::cout << "str4: " << str4 << std::endl;
std::cout << "str7: " << str7 << std::endl;
return 0;
}
Linux下计算cpu占用时间
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <unistd.h>
// 获取指定进程的 CPU 使用率
float getProcessCpuUsage(int pid) {
// 构造文件路径
std::string statFilePath = "/proc/" + std::to_string(pid) + "/stat";
// 打开文件
std::ifstream statFile(statFilePath);
if (!statFile.is_open()) {
std::cerr << "Failed to open stat file" << std::endl;
return -1.0f;
}
// 读取文件内容
std::string line;
std::getline(statFile, line);
// 关闭文件
statFile.close();
// 解析第 14 列(utime)和第 15 列(stime)
std::istringstream iss(line);
std::string token;
int column = 1;
unsigned long utime = 0, stime = 0;
while (iss >> token) {
if (column == 14) {
utime = std::stoul(token);
} else if (column == 15) {
stime = std::stoul(token);
break;
}
column++;
}
// 计算 CPU 使用率
unsigned long total_time = utime + stime;
unsigned long hertz = sysconf(_SC_CLK_TCK);
float seconds = static_cast<float>(total_time) / hertz;
return seconds;
}
int main() {
int pid = getpid(); // 替换为您要检查的进程的实际PID
float cpuUsage = getProcessCpuUsage(pid);
if (cpuUsage >= 0.0f) {
std::cout << "Process CPU usage: " << cpuUsage << " seconds" << std::endl;
}
return 0;
}
计算文件夹下所以文件大小
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <dirent.h>
#include <sys/stat.h>
long long calculateFolderSize(const char *folderPath) {
long long folderSize = 0;
// 打开目录
DIR *dir = opendir(folderPath);
if (dir == NULL) {
perror("Error opening directory");
return -1;
}
// 读取目录项
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) {
// 构建文件路径
char filePath[PATH_MAX];
snprintf(filePath, PATH_MAX, "%s/%s", folderPath, entry->d_name);
// 获取文件信息
struct stat fileStat;
if (stat(filePath, &fileStat) == -1) {
perror("Error getting file stat");
closedir(dir);
return -1;
}
// 如果是目录,递归计算目录大小
if (S_ISDIR(fileStat.st_mode) && strcmp(entry->d_name, ".") != 0 && strcmp(entry->d_name, "..") != 0) {
folderSize += calculateFolderSize(filePath);
} else {
// 累加文件大小
folderSize += fileStat.st_size;
}
}
// 关闭目录
closedir(dir);
return folderSize;
}
int main() {
const char *folderPath = "/path/to/your/folder"; // 替换为您要计算大小的文件夹路径
long long folderSize = calculateFolderSize(folderPath);
if (folderSize != -1) {
printf("Folder size: %lld bytes\n", folderSize);
}
return 0;
}
使用了 stat 系统调用来获取文件的详细信息,然后通过递归来获取文件下的所有文件大小
为啥在x86平台下,应用程序A和有个指针p1,应用程序B有个指针p2,且p1和p2的值相等,为什么
答:在典型的操作系统环境中,不同的应用程序运行在各自的用户空间中,彼此之间相互隔离。在这种情况下,应用程序A和应用程序B都是独立,各自有自己的虚拟地址空间。因此,应用程序 A 中的指针 p1 和应用程序 B 中的指针 p2 指向的内存地址在物理内存中是不同的。
但是,如果涉及到进程间通信(Inter-Process Communication, IPC)的机制,如共享内存或内存映射文件,那么在这些机制下,可以实现不同进程之间共享一块内存区域,从而使得两个进程拥有相同的指针值。
Linux的脏数据
在Linux中,"脏数据"通常指的是位于内存中但尚未写入到磁盘的数据。这些数据可能是由应用程序写入到内存中但尚未同步到磁盘的缓存数据,或者是由内核进行的一些操作导致的。
- 脏页(Dirty Pages): 内核中的页面(通常是4KB大小),其中的数据已被修改但尚未写入到磁盘。这些脏页可以是应用程序的缓存数据,也可以是内核进行的文件系统缓冲或其他操作导致的脏页。
- 脏缓冲区(Dirty Buffer): 缓冲区是内核用于缓存文件系统中的数据块的地方。当一个数据块被修改但尚未写入到磁盘时,它被认为是脏的。这包括文件系统元数据和文件数据块。
脏数据的存在是为了提高系统性能,通过将多个写入操作合并为更少的磁盘写入操作,以减少对磁盘的访问次数。这种延迟写入的机制有助于减少对磁盘的随机写入,从而提高系统的整体性能。
导致脏数据产生的典型场景
- 应用程序写入: 当应用程序向文件写入数据时,这些数据首先会被写入到内存中的页缓存。这些页缓存中的数据被认为是脏的,因为它们已经被修改但尚未同步到磁盘。
- 文件系统缓存: 文件系统维护一个缓存,用于存储文件系统的元数据和数据块。当文件系统执行写入操作时,相关的缓存可能会变为脏状态。
- 内核缓冲区: 内核维护用于缓存块设备数据的缓冲区。如果内核对块设备执行写入操作,相关的缓冲区可能会变为脏状态。
- 写时复制(Copy-on-Write): 在某些情况下,操作系统使用写时复制技术,即当多个进程共享相同的内存页面时,只有在其中一个进程试图修改页面内容时才会创建该页面的副本。这也可能导致页面变为脏状态。
- 内存映射文件: 当应用程序使用
mmap函数将文件映射到内存时,对映射区的写入会导致相应的页面变为脏状态。 - 异步写入: 操作系统通常采用延迟写入策略,将多个写操作合并为一个较大的写操作,以提高性能。这可能导致一段时间内有大量的脏数据存在于内存中。
因为脏页的产生就是 修改了文件不会马上同步到磁盘,而是会缓存在内存的 page cache里,等到合适时机再同步到磁盘
内存泄露
是内存泄漏是指在程序运行过程中,动态分配的内存空间未被正确释放,导致这部分内存无法再被程序所访问,但却也无法被操作系统回收。这样的情况会导致程序持续占用内存,最终可能导致系统资源的耗尽,导致程序性能下降甚至崩溃
检查工具: Valgrind
-
模拟执行: Valgrind使用一种称为 VEX 的中间表示来模拟程序的执行。VEX 是一种可扩展、高性能的中间表示,可以在不同的体系结构之间进行转换。Valgrind 将要检测的程序在 VEX 中进行模拟执行,而不是在原生硬件上执行。这样可以提供对程序行为的详细控制,并允许 Valgrind 进行各种检测。
-
动态二进制翻译: Valgrind 使用动态二进制翻译技术将目标程序的二进制代码转换成 VEX 中间表示。这允许 Valgrind在运行时截获对二进制代码的执行,并在 VEX 中进行模拟。这种转换是动态的,发生在程序运行时,使得 Valgrind 能够实时监视和分析程序的行为。
-
插桩: 在程序的执行过程中,Valgrind 在 VEX 中插入检测代码,用于检测内存访问错误、泄漏等问题。这些插桩代码允许 Valgrind 跟踪程序对内存的所有读写操作,并记录有关这些操作的详细信息。
-
内存检测: Valgrind 的主要功能之一是内存检测。它能够检测到对未初始化内存的访问、内存泄漏、越界访问等问题。通过对程序的模拟执行和插桩,Valgrind 能够实时地检测这些错误,并提供详细的报告。
手动实现队列(不带锁)
#include <iostream>
#include <atomic>
#include <memory>
template <typename T>
class Node {
public:
T data;
std::unique_ptr<Node<T>> next;
Node(T value) : data(value), next(nullptr) {}
};
template <typename T>
class LockFreeQueue {
private:
std::atomic<Node<T>*> head;
std::atomic<Node<T>*> tail;
public:
LockFreeQueue() : head(nullptr), tail(nullptr) {}
// 入队操作
void enqueue(T value) {
std::unique_ptr<Node<T>> newNode = std::make_unique<Node<T>>(value);
Node<T>* newTail = newNode.get();
Node<T>* oldTail = tail.exchange(newTail);
if (oldTail != nullptr) {
oldTail->next = std::move(newNode);
} else {
head.store(newTail);
}
}
// 出队操作
T dequeue() {
Node<T>* oldHead = head.load();
if (oldHead == nullptr) {
throw std::underflow_error("Queue is empty");
}
head.store(oldHead->next.get());
T value = oldHead->data;
return value;
}
// 队列是否为空
bool isEmpty() const {
return head.load() == nullptr;
}
// 获取队头元素
T peek() const {
Node<T>* currentHead = head.load();
if (currentHead == nullptr) {
throw std::underflow_error("Queue is empty");
}
return currentHead->data;
}
// 获取队列大小
int size() const {
Node<T>* currentHead = head.load();
int count = 0;
while (currentHead != nullptr) {
count++;
currentHead = currentHead->next.get();
}
return count;
}
};
int main() {
LockFreeQueue<int> myQueue;
myQueue.enqueue(10);
myQueue.enqueue(20);
myQueue.enqueue(30);
std::cout << "Front element: " << myQueue.peek() << std::endl;
std::cout << "Queue size: " << myQueue.size() << std::endl;
std::cout << "Dequeue: " << myQueue.dequeue() << std::endl;
std::cout << "Queue size after dequeue: " << myQueue.size() << std::endl;
return 0;
}
算法题
那次算法题考的是背包问题,好像给的是车站的问题,给了几种方案求最少方案,还有到题是直接拿异或求解
int knapsack(int capacity, const vector<int>& weights, const vector<int>& values) {
int n = weights.size();
vector<vector<int>> dp(n + 1, vector<int>(capacity + 1, 0));
for (int i = 1; i <= n; ++i) {
for (int w = 0; w <= capacity; ++w) {
if (weights[i - 1] <= w) {
dp[i][w] = max(dp[i - 1][w], values[i - 1] + dp[i - 1][w - weights[i - 1]]);
} else {
dp[i][w] = dp[i - 1][w];
}
}
}
return dp[n][capacity];
}
面试总结
本人太菜了,Linux部分完全没有答出来,得要好好反思了,其实里面还考了排序的,好像是堆排的顺序,还有408的基础知识,给定C类IP地址,然后求子网掩码。其他没了,多总结学习
















 1479
1479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











