







tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
2.修改环境变量:
vim / etc/profile
三台虚拟机都要配置
在最下面添加:
JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
刷新环境变量
source /etc/profile
3.检验JDK:
输入javac:
javac
输入 java -version:
java -version

4.配置hosts
vim /etc/hosts
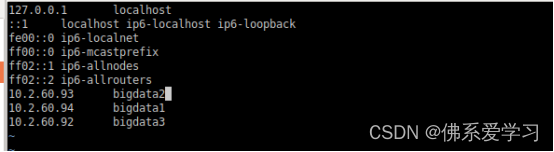
ip地址根据自己虚拟机的ip与名称进行修改
5.做免密登录:
ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
ssh-copy-id bigdata1
ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata2
ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata3
输入代码后根据提示输入yes或者密码
6.分发jdk:
scp -r /opt/module/jdk1.8.0_212/ root@bigdata2:/opt/module/
scp -r /opt/module/jdk1.8.0_212/ root@bigdata3:/opt/module/


二,hadoop:
7.在bigdata1将Hadoop解压到/opt/module
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
8.添加Hadoop的环境变量
三台虚拟机都要配置
vim / etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
刷新环境变量
source / etc/proflie
9.配置文件在hadoop-3.1.3/etc/hadoop里面
①core-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
②hdfs-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata1:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata2:9868</value>
</property>
</configuration>
③yarn-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
图片转存中...(img-4ncMMa5l-1714701983667)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









