






一 概要
CIFAR-10分类问题是机器学习领域的一个通用基准,其问题是将32X32像素的RGB图像分类成10种类别:飞机,手机,鸟,猫,鹿,狗,青蛙,马,船和卡车。
更多信息请移步CIFAR-10和Alex Krizhevsky的演讲报告
二 目标
本教程的目标是建立一个相对简单的CNN卷积神经网络用以识别图像。在此过程中,本教程:
- 高亮网络架构,训练和验证的典型组织。
- 为构建更大更复杂的模型提供模板。
选择 CIFAR-10的原因是其复杂程度足以训练tensorFlow拓展成超大模型能力的大部分。同时,于训练而言,此模型也足够小,这对于想实现新想法和尝试新技术堪称完美。
三 教程的高亮部分
CIFAR-10教程演示了使用TensorFlow构建更大更复杂模型几个重要结构:
- 核心数学组件包括
卷积,修正的线性激活,最大池化,LRN即局部响应一体化(AlexNet的论文3.3章) - 训练期间网络活动的可视化,包括输入图像、损失函数值、激活函数值和梯度的分布。
- 计算学习参数的均线(moving average)的惯常做法,以及在评估期间使用这些均线来促进预测性能。
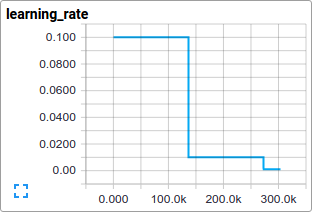
- 随时间系统递减的学习速率清单的实现
-
为消除从磁盘读取模型的延迟和代价极大的图像预处理的预取队列。
我们同时提供了一个多GPU版本的模型演示:
- 配置并行环境下跨多个GPU的训练的单个模型
- 在多GPU中共享和更新变量
我们期望此教程能为基于TensorFlow的可视化任务创建更大CNNs模型提供起点。
四 模型架构
CIFAR-10教程中的模型是一个由可选的卷积和非线性层组成的多层架构。这些网络层之后是连接到一个softmax分类器的全连接的网络层。模型遵照Alxe Krizhevsky所描述的模型架设,只是最前面的几层有细微差别。
此模型获得了一个极致的表现,在一个GPU上训练几个小时可以达到约86%的准确率。下文和代码部分有详细说明。模型由1068298个可学习的参数并且单张图片需要195000000个加乘操作以计算推理。
五 代码组织
此教程的代码位于 tensorflow/models/image/cifar10
| 文件 | 目标 |
|---|---|
| cifar10_input.py | 读取本地的CIFAR-10二进制文件 |
| cifar10.py | 创建CIFAR-10模型 |
| cifar10_train.py | 在CPU或者GPU上训练CIFAR-10模型 |
| cifar10_multi_gpu_train.py | 在多个GPU上训练CIFAR-10模型 |
| cifar10_eval.py | 评估CIFAR-10模型的预测性能 |
六 CIFAR-10 模型
CIFAR-10网络大部分代码在 cifar10.py。完整的训练图包括大概765个操作,我们发现通过使用以下模块来构建计算图,我们可以最大限度的重用代码:
- 模型输入: inputs() 和 distorted_inputs() 分别是评估和训练的读取并预处理CIFAR图像的加法操作
- 模型预测: inference()是推理加法操作,即在提供的图像中进行分类。
- 模型训练: loss() 和 train() 的加法操作是用来计算损失函数,梯度,变量更新和可视化摘要。
七 模型输入
模型的输入部分由从CIFAR-10的二进制文件读取函数 inputs()和distorted_inputs() 完成。这些文件包括固定字节长度的记录,因此我们使用tf.FixedLengthRecordReader 。查看读取数据来学习Reader class如何实现。
图像将按照以下步骤进行处理:
- 它们被裁减成24x24的像素,中央部分用来做评估或随机地用以训练。
-
它们是 approximately whitened 用以使模型对动态变化不敏感。
对于训练部分,我们会额外应用一系列随机扭曲来人为增加数据集:
-
将图像随机的左右翻转随机翻转
- 随机扰乱图像亮度随机亮度
- 随机扰乱图像对比度随机对比度
在图像页可以查看可用的扭曲方法列表。为了在TensorBoard中可视化,我们也在图像中增加了一个 缩略图。这对于校验输入是否构建正确是个良好举措。

从磁盘中读取图像并扰乱,可能会消耗不确定的时间。为防止这些操作拖慢训练过程,我们使用16个独立线程不断地从一个TensorFlow队列。
八 模型预测
模型的预测部分由inference()函数构建,该操作会添加其他操作以计算预测逻辑。模型的此部分组织如下:
| 网络层名称 | 描述 |
|---|---|
| conv1 | 卷积和修正线性激活层 |
| pool1 | 最大池化 |
| norm1 | 局部响应一体化 |
| conv2 | 卷积和修正线性激活层 |
| norm2 | 局部响应一体化 |
| pool2 | 最大池化 |
| local3 | 使用修正线性激活的全连接层 |
| local4 | 使用修正线性激活的全连接层 |
| softmax_linear | 线性转换以产生logits |
下图由TensorBoard生成用以描述推理操作
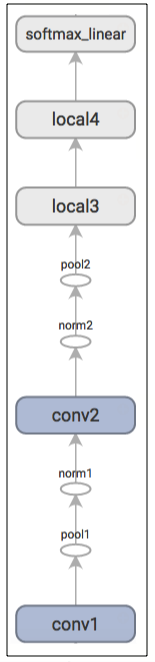
input()和inference() 函数提供了在模型上进行评估的全部所需组件。我们先将注意力移到训练模型。
九 模型训练
训练一个完成N类分类的网络的常用方法是多项式logstic回归,aka.softmax回归。softmax回归在网络输出上应用一个softmax非线性函数并计算标准预测和标签的1-hot编码的交叉熵。我们也将通常使用的权值衰减损益应用到所有学习变量上来完成正则化。 模型的目标函数是交叉熵损失之和,以及由 loss()函数返回的权值衰减项。
我们在TensorBoard使用scalar_summary对其可视化:
我们使用标准的梯度下降算法(见对其他算法的训练方法),其学习速率随时间指数递减。
train()函数添加必要的操作通过计算梯度和更新学习变量(详见GradientDescentOptimizer)以最小化目标变量。
该函数返回一个执行所有的训练和更新一批图像所需的计算操作。
十 运行和训练模型
通过运行脚本cifar10_train.py训练操作
Python cifar10_train.py
注意:首次运行该脚本时,CIFAR-10数据集会被自动下载。数据集大小为 160MB
如果成功,你将会看到如下输出:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
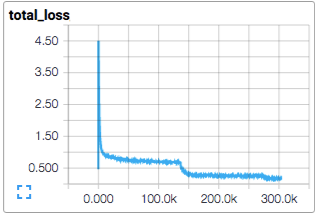
脚本每运行10次输出一次总的损失函数值。注意:
- 第一批数据可能会相当慢(例如:几分钟),因为预处理线程会将20万张处理过的图像数据填充混洗队列。
- 输出的损失函数值是最近一批数据的均值,要记得损失函数值是 交叉熵和权值递减项的总和。
-
密切关注批处理速度,以上数据由 Tesla K40c机器上输出,如果在CPU上运行可能会输出比这个更低的速率。
cifar10_train会定期保存所有的模型参数到checkpoint files,但是它并不评估模型。checkpoint files将会被用于cifar10_eval.py来衡量预测性能。见下文的评估模型
脚本cifar10_train.py的终端输出的文本只提供了模型如何训练的最小视角。我们可能需要更多的信息:
-
损失函数值真的在递减吗?还是说只是噪声
- 模型的输入训练图像是否合适?
- 其梯度,激活函数,权值是否合理?
-
当前的学习速率?
TensorBoard 提供了此类函数,展示了脚本cifar10_train.py通过SummaryWriter阶段性输出的数据。
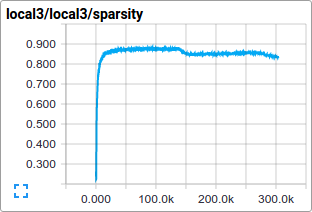
比如说,我们可以查看激活函数分布和训练过程中local3特性的稀疏度。
损失函数值会随着时间呈现,但是由于训练过程中某些批量数据量过小而出现一些噪音数据。实际情况中,我们发现可视化原生数据之外的均线(moving averages)很有用。可以通过脚本ExponentialMovingAverage查看。
十一 评估模型
接下来,我们需要评估我们的训练模型在hold-out数据集上的性能。模型由脚本cifar10_eval.py评估。它由inference()函数构建模型,并使用cifar-10数据集中的10000张图像。它会计算图像的真实标签的最高预测匹配的频率。
为观察模型如何逐步在训练过程提高,评估脚本会阶段性地运行由cifar10_train.py脚本创建的checkpoint files。
python cifar10_eval.py
注意:不要在相同的GPU上运行训练和评估,否则会出现内存不足错误。可以考虑在分开的GPU上运行,或者在运行评估程序时挂起训练程序
你将会看到如下输出:
2015-11-06 08:30:44.391206: precision @ 1 = 0.860
...
脚本极少情况下会返回精确度为precision @ 1 ,当前这个例子返回的是86%的准确率。cifar10_eval.py也会导出一些可以在TensorBoard里可视化的概要信息。
训练脚本计算所有的学习参数的变动均值(moving average version)。评估脚本则用变动均值(moving average version)替换所有的学习的模型参数,这些替换将有益于模型评估时的性能。
十二 使用多GPU训练模型
在分布式并行环境下训练模型需要一致的训练过程。接下来,我们将模型副本分配到训练数据集的每个子集上。
简单地运行异步更新模型参数将导致局部最优化,这是因为单个模型的副本可能会在过时的模型参数上进行训练了。反过来说,完全的同步更新将会使整个过程与最慢的模型副本一样慢。
工作站中的多GPU一般有相似的速度和内存。因此,我们按照如下步骤设计训练系统:
- 每个GPU上放一份独立的模型副本。
-
通过等待所有的GPU完成某一批数据的处理来同步更新模型参数。
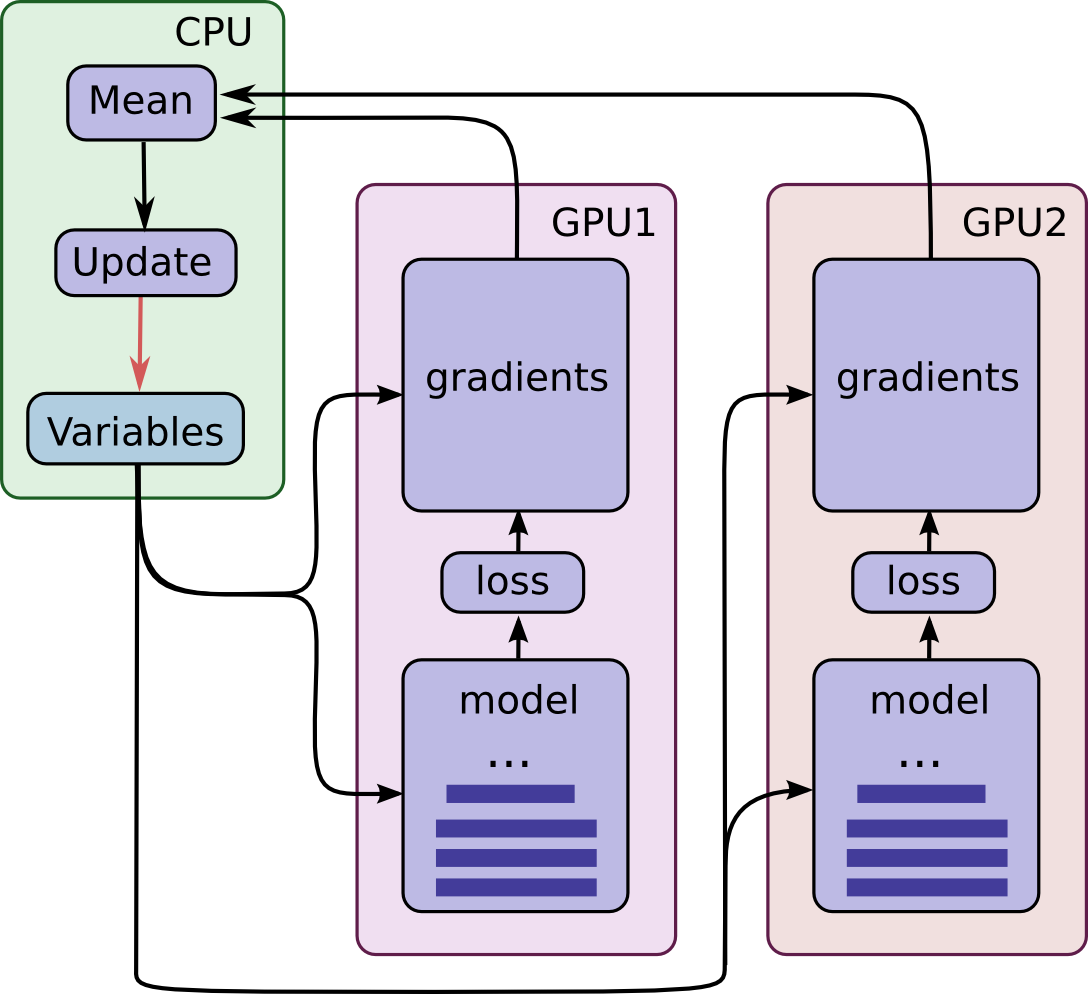
如下是模型的数据图:
注意到,每个GPU都会计算一份独一无二的数据的inference和梯度。这样的设置将极有效地在多GPU之间划分一个大批量数据。
这样的设置需要所有的GPU共享模型参数。众所周知,从GPU传输数据或者传输数据到GPU都相当慢。因此,我们决定在CPU上存储和更新所有的模型参数(见绿色盒图)。只有当一批数据已经被所有GPU处理之后,一份新的模型参数才会被传输到GPU。
GPU在操作上是同步的,所有的来自各个GPU的梯度都会被累加和均值化。模型参数会被所有模型的梯度均值更新。
十三 在设备上放置变量和操作
在设备上放置操作和变量需要一些特殊抽象。
第一个抽象是我们需要一个函数来计算模型的单个副本的inference和梯度。在代码中,我们将这种抽象标为tower。我们必须为每个tower设置两个参数。
- 一个tower内所有的操作都需要一个独一无二的名字。tf.name_scope()通过前置范围的形式提供了方法。比如说,第一个tower,tower_0内的所有操作都会有一个前置 tower_0/conv1/Conv2D。
-
某个tower的首选硬件设备。tf.device()可以来指定。比如说,第一个tower的所有的操作使用范围device(‘/gpu:0’) 指明其应当在第一颗GPU上运行。
所有的变量都会被固定到CPU,并且可以通过tf.get_variable()在多GPU之间共享。关于如何共享变量请见下文。
十四 在多GPU上运行和训练模型
对于有多颗GPU的机器,使用cifar10_multi_gpu_train.py脚本将会更快的训练模型。次代码在多颗GPU之间并行训练模型。
python cifar10_multi_gpu_train.py --num_gpus=2
GPU数量默认为1.















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









