







目录
38.Linguistic features for review helpfulness prediction. (Expert Systems with Applications)
31.Does the dispersion of online review ratings affect review helpfulness?(Computers in Human Behavior)
这篇文章是比较新的一篇文章,为在线评论有用性的研究提供了一个新的自变量,看标题可以知道dispertion,衡量了评论星级的离散程度对评论有用性是否有影响。研究在线评论有用性的范式还是比较固定的,首先是因变量的选择,这篇文章直接选择了有用性投票作为因变量,不像前面的文章,选择了有用性投票率作为因变量。
在自变量的选择上,文章选择了评论星级、评论不一致性、评论极端性、评论长度、评论日期、是否含有图片、负向词语作为自变量,同时还包括了各个评论星级打分在评论中的占比,以及文章提出的评论星级的离散程度。文章基于HSM来分析评论星级的离散程度对评论阅读者的影响,最小努力原则和充分原则允许消费者在做决定时进行启发性和系统性的处理,充分性原则允许消费者在个人基于准确和合理的理由以足够的信心做出决定时参与系统的处理,评级的低离差表示评论表达了一致的评级,从而暗示平均评级的高可信度,有经济头脑的消费者不会因为最省力原则而认为个人评分令人印象深刻。低离差的情况下就意味着大部分人的想法是一致的,根据从众理论也可以得出,购买者会根据大众的评价产生购物决策,从而降低了单个评论的有用性。
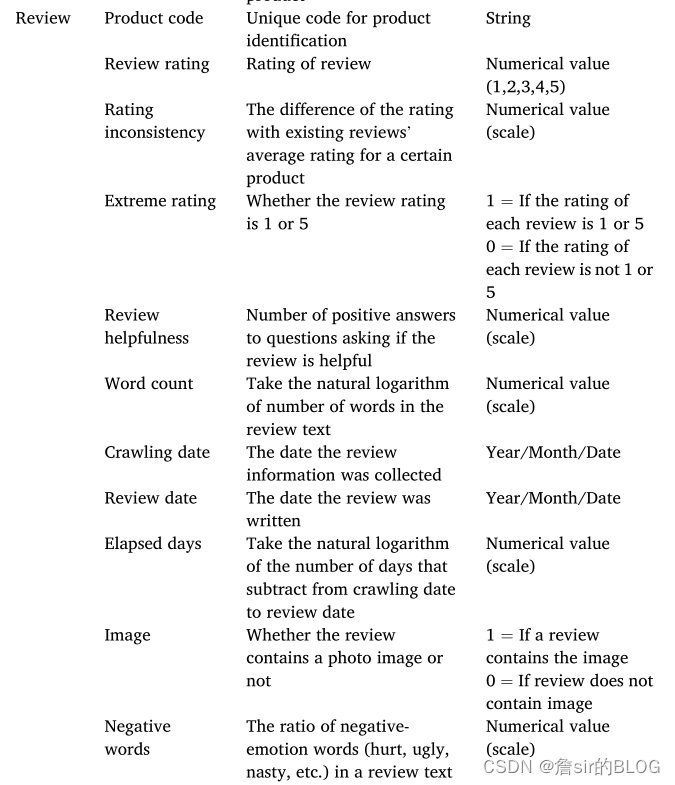
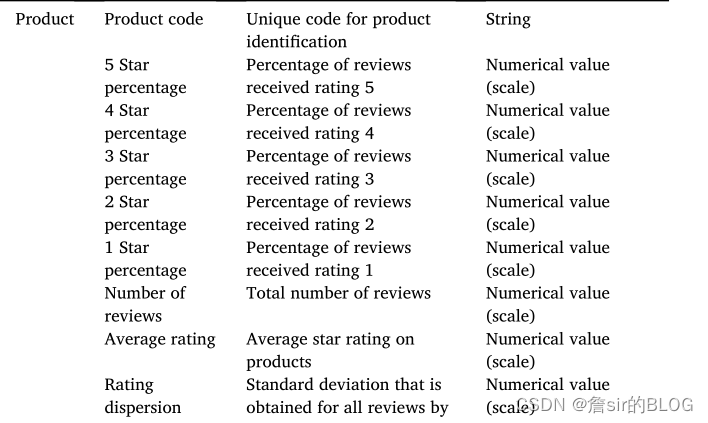
在模型的选择上,由于因变量选择的缘故,文章使用了负二项回归,结果挺漂亮的,评论的离散程度正向显著的影响评论有用性,其余结论和以前的文章得到的结论也都保持了一致。

32.Modeling and prediction of online product review helpfulness: a survey. (In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics)
这是一篇发表在ACL顶会上的关于在线评论有用性的综述,本来是想学习新变量的,结果突然下载到了一篇综述型的文章,那就趁着看综述的机会把之前学习的变量和知识再稍稍巩固一下好了。文章对数据集、自变量、因变量等问题进行了全面的探讨。
在数据集方面,在线评论领域的文献都是根据自己的爬虫去获取各自的数据集,因此研究没有一个统一的数据集,与机器学习领域相比,没有共同的数据集就会带来一个问题,就是彼此提取的新特征无法进行横向比较,无法构建一个baseline,在一定程度上阻碍了学术的发展。也可以看到由于数据集的不同,相同的指标可能会在不同的文献中得到不同的结论。
在因变量的选择上,常见的因变量是有用投票数、有用投票比例、有用或者没用,对应的问题就是回归问题或者二分类问题。评论发表的时间会影响这些因变量。文章给出了一个评论例子,说明了有用性投票比例不一定是最优的因变量,因为示例评论没有那么好,但是依然得到了相当高的评论,因此依然存在没有被挖掘出来的重要变量。但是现行的文献中,基本上都是采用有用性投票比例来进行度量。

在模型表现方面,回归就用MSE系列,分类就用PRF系列指标,排名用NDCG度量。在模型上,NB/SVM/RF/NN都是可以选择的模型。
在特征提取方面,文章总结的还是很详细的,首先是老生常谈的文本长度系列特征;然后是可读系列特征,可读系列特征我感觉还是研究的比较少的,尤其是拼写错误这种文本特征没有很好的进行研究;然后是单词层面的特征,主客观词语数量以及其他词语的数量;内容层面就比如情感特征、离散特征等等;还有就是星级、主观度的特征。评论者特征就比如过去发表的评论总数等等特征。
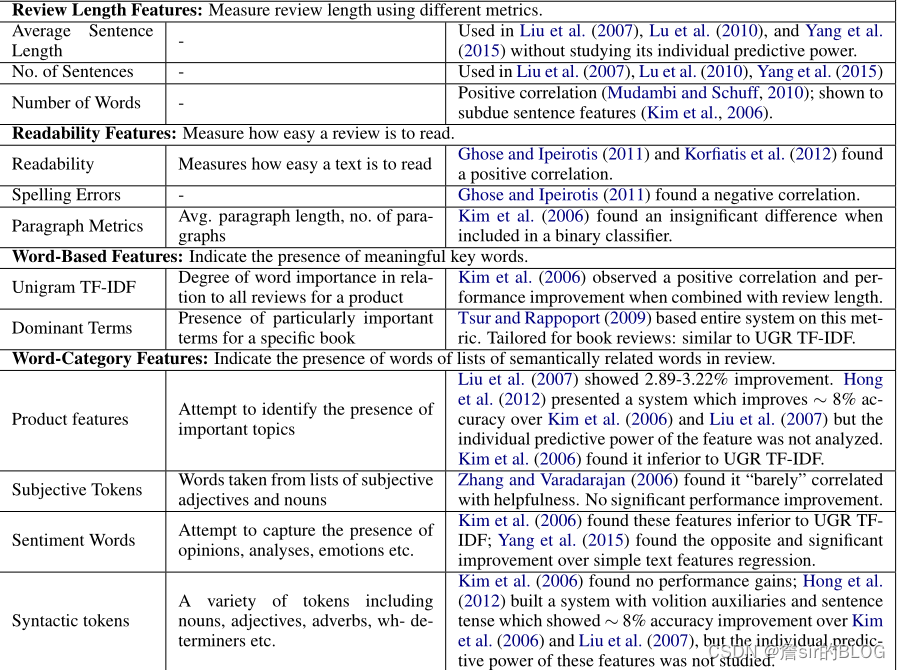

文章还介绍了几种调节效应,例如产品类型、产品星级离散程度、评论者与阅读者相似度、评论书写风格、近邻评论的优异度等都会对评论有用性有调节作用。这里又有了一个新视角,就是推荐系统的问题,从大量评论中推荐几条有用的评论直接给消费者看,但是这种用户关联度的数据可能并不是很好拿到。后面可以去研究一下这种推荐算法。
33.Is this opinion leader's review useful? Peripheral cues for online review helpfulness. (Journal of Electronic Commerce Research)
这篇文章是一篇比较早的文章,所提及的变量和方法和前面的文章都非常相似,没有什么特别新的地方,但是行文思路和模型的选择都是值得学习的,结论也可以在文献综述中引用一下。文章基于ELM模型和SCM模型分析了评论文本本身的特征和评论者的特征对评论有用性的影响。分析评论有用性文章还是三块,因变量、自变量和模型。
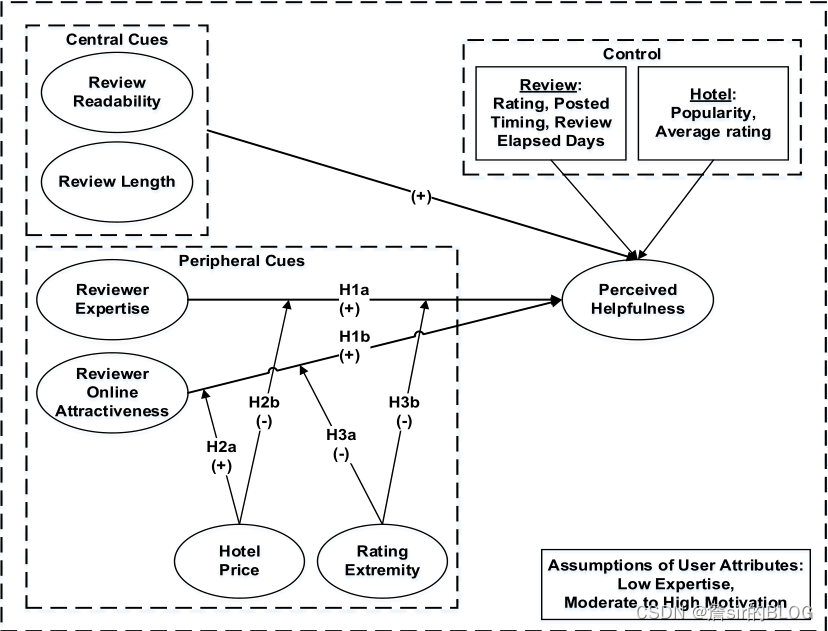
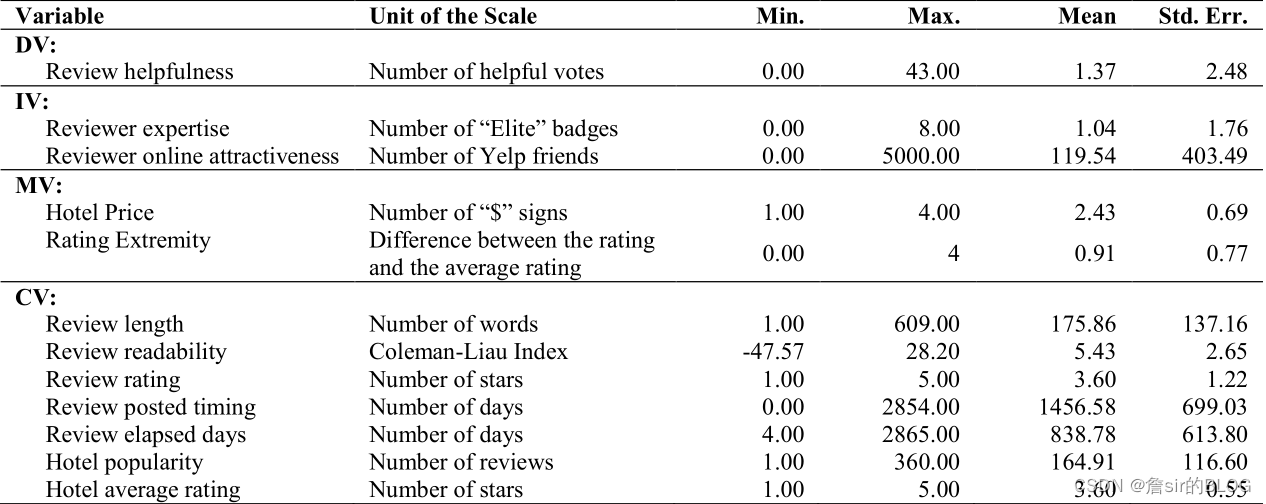
在因变量上,文章直接选择了有用性投票的数量来作为因变量,这样选取因变量的画,时间的因素在预期上应该是会显著的,在模型上,文章选择了负二项回归来进行模型训练。
在自变量的选择上,文本长度、评论者专业水平、评论者吸引力、价格、评论极性(这篇文章用不一致性的定义来定义了极性,这里我还是比较赞成后来的文章的观点,将极性定义为1星或者5星的评论)、可读性、时间、评价星级。自变量的选择都是十分中规中矩的,在理论的解释上,自变量的选择借助了ELM模型以及SCM模型,行文我感觉还是十分扎实的,文章的逻辑很清晰。
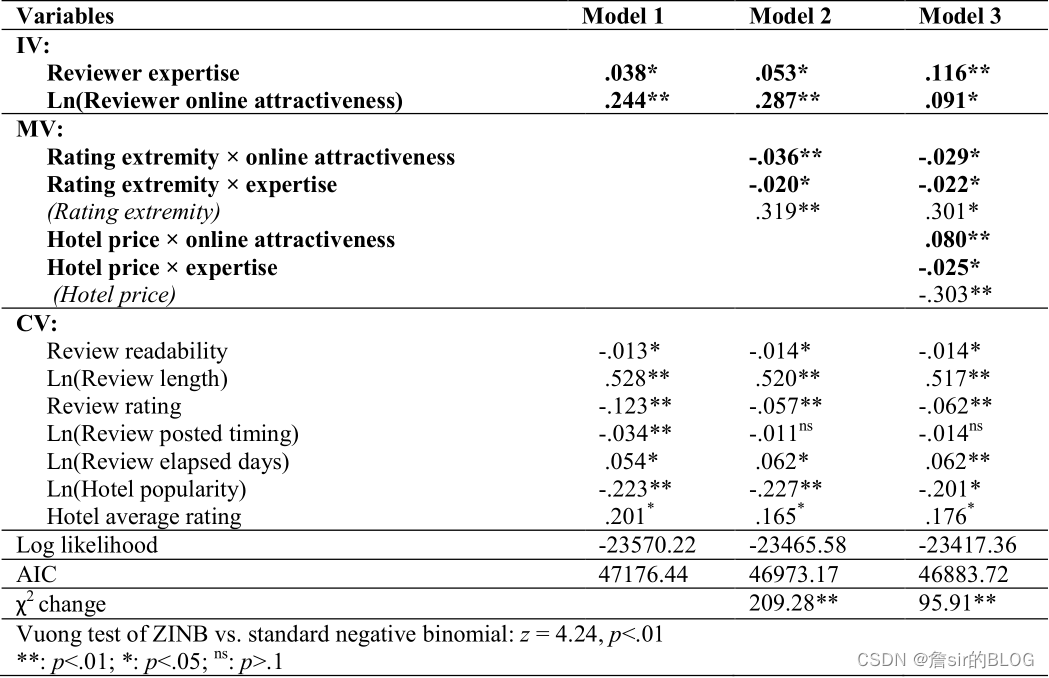
最终得到的回归结论也很漂亮,评论的极端程度会弱化评论者吸引力和专业知识的影响,这个调节效应换到其他文章中就是不一致性会弱化外源性因素的影响,说明从众心理还是有一定影响的。评论者吸引力的提法还是比较有启发性的,可以考虑其他度量的方法。
34.Online review helpfulness and firms’ financial performance: an empirical study in a service industry. (International Journal of Electronic Commerce)
这篇文章不是关于评论有用性的研究,而是用评论有用性去研究与公司业绩之间的表现的关系。这个研究就比较接地气,评论有用性的研究是单纯的将有用性评论筛选出来,不断的提取新特征来提高模型的表现,这篇文章则直接研究了评论有用性与酒店业绩的相关性,实践性会更强一些,因此之前文章的写作框架可能就不大适合这篇论文了。
在样本选择上,文章选择了高端酒店作为分析对象,从BOOKING.COM爬取了40万条评论数据来进行分析。在模型选择上,采用了固定效应面板回归模型。文章论述了可能影响酒店业绩的因素,分别是评论的星级、评论的数量、评论的的有用性以及评论的分散程度,并提出了研究假设:星星越高绩效越好、数量越多绩效越好,评论有用性越高绩效越好。在控制变量上,文章加入了管理者回复数量和季节变量。
在变量的度量上,反映绩效的指标采用了每间房的平均收入、评论效价用平均星级度量、评论有用性用累计有用性投票来度量。这个文章的数据采集工作还是很大的,首先要做爬虫爬取评论数据,评论数据拿到之后还要根据酒店信息去查询酒店的业绩信息。

在传统计量经济学上,都自变量和因变量的分布都有一定的要求,因此有对部分变量做了对数变换,最终得到的结论也很漂亮,支持了前文的假设。评论的星级、评论的数量以及评论星级与评论有用性的交叉效应都正向显著的影响了酒店的经营业绩。

这是第一次看评论有用性与业绩之间的关系的文章,除了拓展了视野之外,也有一定的疑惑,首先是因变量的选择,为什么选择了平均每个房间的收入来反映业绩,第二个是自变量还能不能继续扩充,从在线评论中提取出更多的因子去提高模型的拟合程度,后面有兴趣可以继续阅读这类文章。
35.The order effect on online review helpfulness: A social influence perspective. (Decision Support Systems)
这篇文章是研究评论有用性的文章,提出了一个新变量,即评论次序对评论有用性的影响,文章借助社会影响理论来解释了评论次序对评论有用性的影响机制,整体行文思路很清晰,结论也很漂亮,又是一篇学习论文书写的好范文。
研究评论有用性的框架还是很固定的,自变量、因变量、模型三方面。这篇文章的因变量选择了有用性投票作为因变量。在自变量上,文章选择了评论次序、评论者连接度、评论者专业水平、评论星级、评论长度、发布时长作为自变量。在模型选择上则选择了传统的负二项回归来进行模型训练。评论次序的度量,文章的度量方法是以评论发布的天数来进行度量的,前一天的评论的次序比后面一天的评论的次序低,同一天的评论则享有同样的次序,评论次序度量了不同评论发表时间的先后次序。文章借助社会影响理论,说明了后面的评论会受前面的评论的影响,从而降低了评论的有用性。这种负面影响受评论极端性、评论长度、评论者专业知识以及评论者连接度的调节。
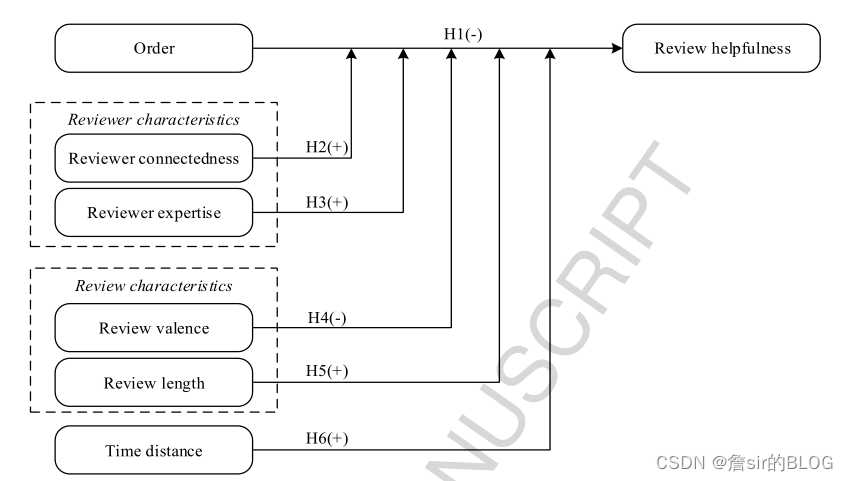
文章从YELP上爬取了7万条饭店评论数据,然后进行负二项回归分析,得到的结果还是很漂亮的,证明了评论次序越高,就是发布时间越晚,对评论有用性的负面影响就越大。不过这里有一个问题,这个变量我感觉仍然是变量时间系的变量,文章想要说明的是,晚发布的评论容易受到以发布的评论的影响,由于社会服从效应的存在,从而降低了评论的有用性。但是这种度量方式和发布时间我感觉是没有太大差别的,这个变量就是从发布时间中衍生出来的变量,并没有体现出来评论之间的相互影响作用。文章的做法只能说明,评论发布的越早,点赞数量就会越多,其实在阅读文章的时候,我就感觉理论解释上有一些牵强。
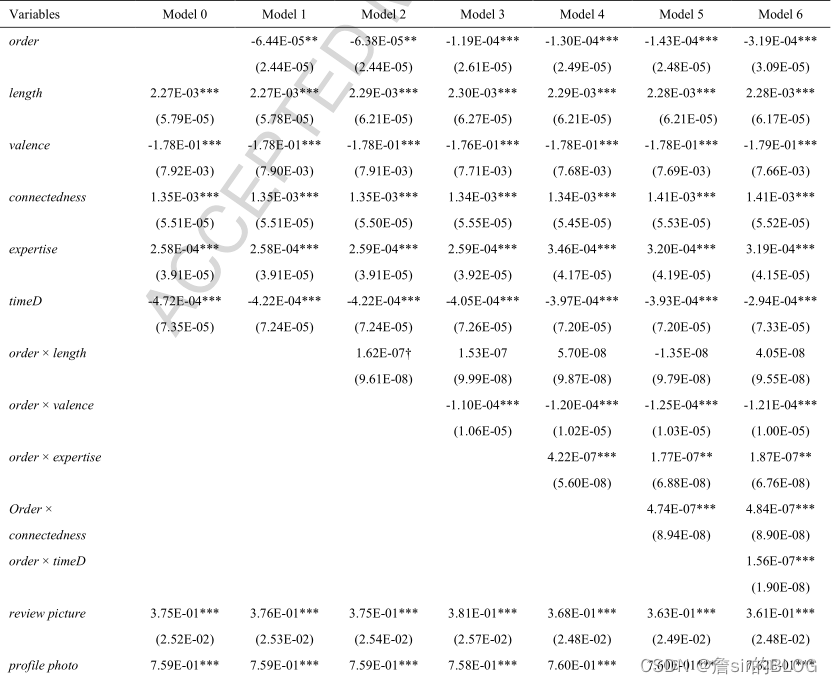
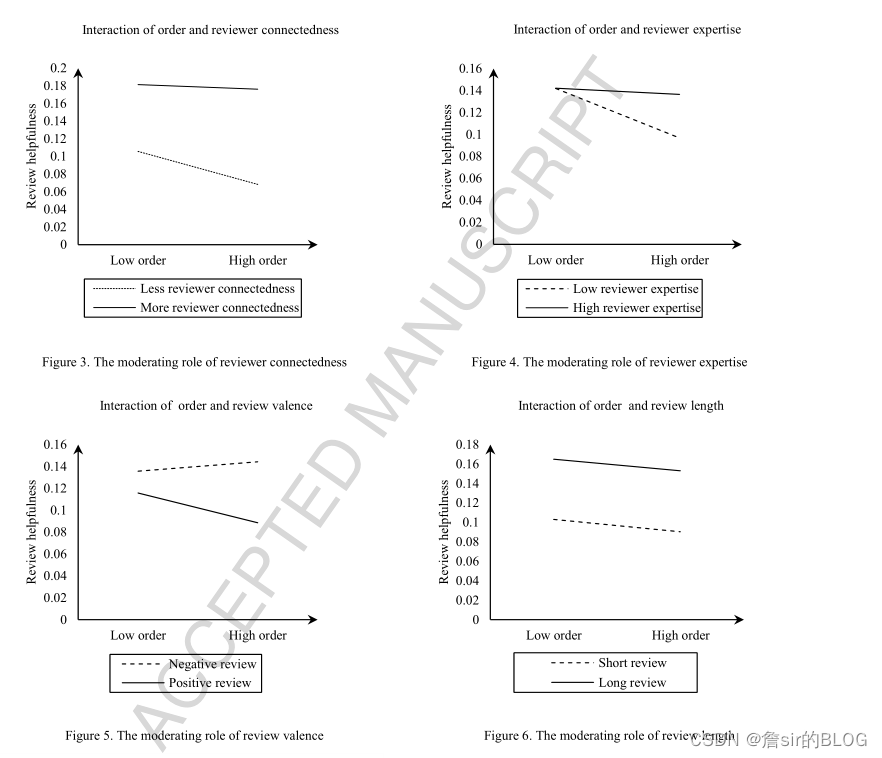
但是这并不影响这篇论文是一篇好文章,文章的整体写作十分清洗,研究方法也很好,值得学习,特别是可视化的方法值得好好琢磨,从评论之间的相关性去研究评论有用性,这篇文章提供了一个相当nice的思路,值得加入到后面的研究中去。
36.A semantic measure of online review helpfulness and the importance of message entropy. (Decision Support Systems)
传统的评论有用性的研究所采取的自变量都是与评论文本相关的特征和评论者相关的特征,因变量都是采取了有用性投票或者有用性投票比例,这种因变量多多少少都是会受到评论发布时间的影响,造成了早鸟效应、锚定效应,使得点赞多的评论倾向于获得更多的评论。这篇文章提出了一种基于LSA的评论有用性度量方法,在自变量方面提出了基于信息增益的新特征,这篇文章的信息增益提取方式和文章的提取方式不一样,因此也算是创新。
这篇文章的自变量有信息增益、情感离散度、可读性、评论总得票数,控制变量上选择了词数、产品词数、排名、星级。信息增益的方式和前面的度量方式有一定的区别,第一条评论(按发布日期)包含16个单词并且被评论的产品的描述包含51个单词,那么该评论的熵值就是ENTROPY(51,16)=-[(51/67)log(51))+((16/67)log(16))]~ 0.5497。第二条评论的熵就是同样的道理,把第一条和产品评论的熵也包含进来。这里的词语应该是新增词语的意思,只有新增词语了才会带来新的信息,这要一条评论用了之前评论没有用过的词语,那么就给消费者提供了新的信息,就有可能提高消费者的产品感知能力。情感离散程度我没看懂文章想说啥,不过既然是度量离散程度,开发个指标应该不是很难。可读性用的是ARI。

在因变量上,文章采用了三种因变量度量方式,一种是基于LSA的有用性度量,第二种是有用性投票总数、第三种是有用性投票比例。然后用三种因变量分别对自变量进行经典的线性回归分析,得到的结论也很不错。LSA这个算法李航的书上有,CSDN也能搜到博客,我之前没学过,后面学一学这个方法,感觉这个很不错。
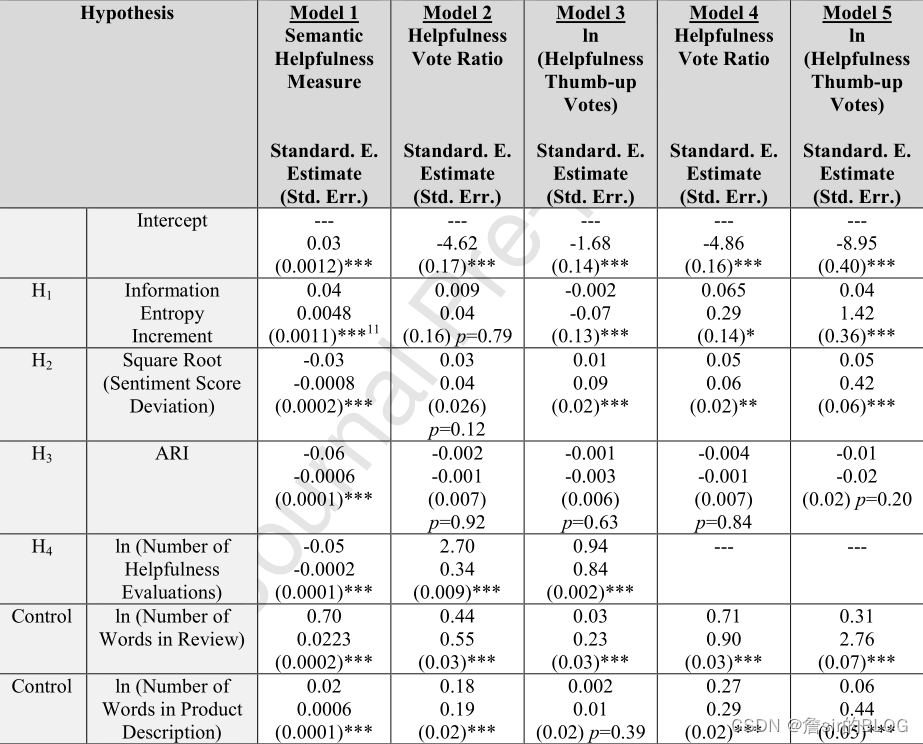
结论是信息增益与有用性呈正相关,情感偏差与有用性呈正相关。总结一下,文章提出的信息增益的计算方法还是很有启发性的,其次是基于LSA的文本有用性度量,十一篇很NICE的文章。
37.Online review helpfulness: the moderating effects of review comprehensiveness. (International Journal of Contemporary Hospitality Management)
这篇文章是研究在线评论有用性的,文章的写作思路和清晰度上我感觉比较灾难,文章前半部分和其他文章一样,提出了新特征,然后用负二项回归进行参数检验,后半部分则是用了问卷调查的方法,然后用方差分析的方法来进行结论检验。
这篇文章的因变量是用评论有用性投票总数来表示,自变量则包含了多个方面,首先是文章说的评论全面性,用产品属性的提及数量来表示;是否包含图片、子评论星级(对商家、对骑手、对商品)、评论设备、评论极性、发布时间、长度、可读性、主观性、评论者头像包含几个人、评论者位置、酒店平均星级、酒店价格。自变量还是比较丰富的。文章自己说全面性这个观点还是比较新的,但是其实其他文章也挺多的提及到这个方面了,然后文章还说全面性对评论极性、长度这些变量的调节效应还没有得到研究,也算是把。

文章一共获得了一万多条酒店评论数据,然后跑了负二项回归,文章的模型多的数不过来,我已经看不懂了,但是总体还是能看看的,首先自己提出的全面性指标,结论有好几个模型不显著,很尴尬,但是有调节效应,只能尴尬的写调节效应了;长度、时间、地理位置、酒店的平均星级和价格都是显著影响评论有用性的。然后为了证明全面性的影响,文章又去做了问卷调查,这个我就不去多做解释了,感兴趣可以自己看看。
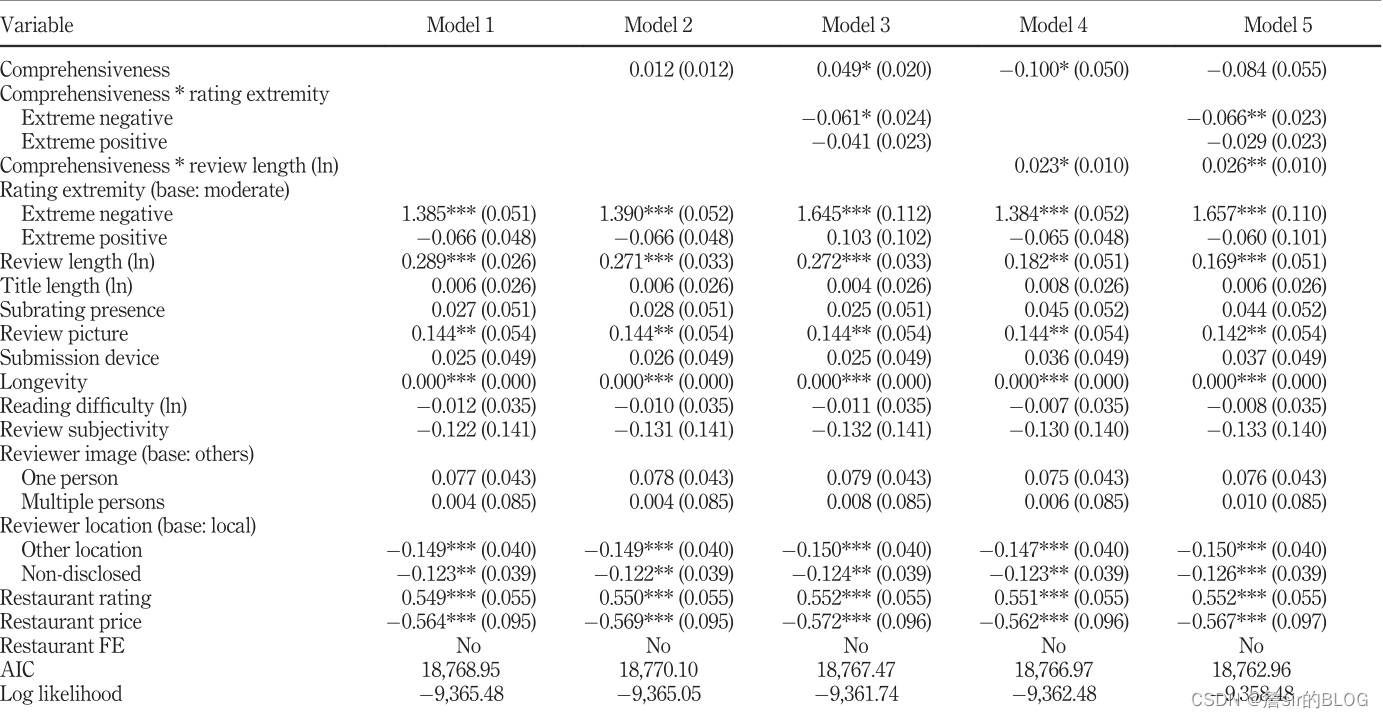
总而言之,这篇文章给我打了个样本,反向学习了一波,文章的表格太乱了,文章也有堆砌的嫌疑,之后我的论文里表格要工整简洁,文字部分要讲好故事,引人入胜。
38.Linguistic features for review helpfulness prediction. (Expert Systems with Applications)
这篇文章写的很精彩,看标题就知道是探讨文本语言特征对评论有用性的影响的。前面的文章也有很多从语言特征上去探讨的,比如文本的情感特征、文本的主观性特征、文本的可读性特征、文本的词性特征(去统计各种词性的词语的数量),这篇文章讲解的就是词性特征对在线评论有用性的影响,之前的文章也提取过各种词性的特征加入到训练特征中,但是都没有具体描述这些特征是如何影响评论有用性的。这篇文章发表的时间比较早,是一篇高引用文章,行文思路清晰值得学习一下。
研究评论有用性,首先是确定因变量,这篇文章和之前的文章不一样,将评论有用性视为一个二分类问题,有用评论的筛查标准是有用性投票比例超过一个确定的阈值,则判定该评论为有用的评论,否则是无用评论。同时文章还去除掉了一些投票总数比较低的评论,因为文章认为投票数比较低的话有用性投票比例可能天生就比较高,评论的真实有用性可能并不是那么高。这是一种自动确定评论是否有用的方法,但是自动标准准确性肯定是会受到一定的影响的,手动标注也是可以考虑的办法。
确定了二分类问题之后,接着就是确定自变量,文章将自变量分为了语言特征、可读性特征、主观性特征、评论极性等特征。其他几个特征都很常规,主要是语言特征是文章的重头戏。文章的文本是基于英文网络的,文章就词性分为了形容词、描述性动词、状态动作动词、解释动作动词、描述动作动词。下面是一个实例,描述性动词就是love/like这种动词,文章有总结了一个表格。然后再往下就是三类动词,三类动词的情感程度是不同的,根据这种程度可以去区分三类动词,文章的主要工作就是在区分这三个动词上面的。
实例: I regularly take(DAV) pics with this camera. The quality of the pics has really amazed (SAV) me. Battery life is fabulous (ADJ). My only issue is that it makes (DAV) a lot of noise in auto-focus mode. I strongly recommend (IAV) this camera.

文章的词性提取还是相当关键的,在模型上,文章选择了RF/SVM/NB三个常见模型的机器学习模型,然后分批加入变量,证明了语言特征对评论有用性的影响是十分显著的。同时还行了细化研究,比如分批加入特征后查看这些特征对积极和消极评论的识别能力、对不同产品类型的识别能力,文章也给出了一个结论,语言特征对体验型商品的效果更加显著,同时也进行了敏感性分析,分别采取不同的阈值来查看实验的效果。
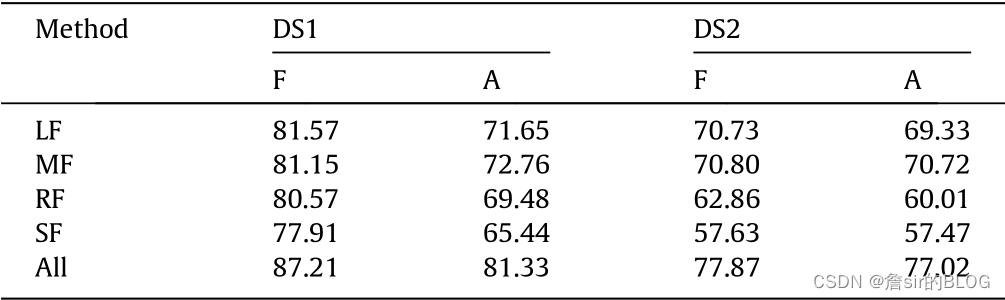
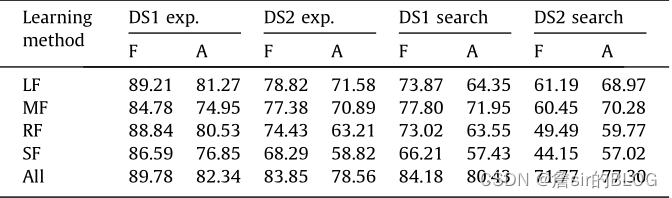
总体来讲,文章行文思路清晰,工作量也很饱满,是一篇相当nice的好文章!
39.The role of cultural values in consumers' evaluation of online review helpfulness: a big data approach. (International Marketing Review)
这篇文章看标题可以知道这篇文章提出了一个新变量,就是文化价值的概念,文章借助了霍夫斯泰德文化维度的概念来研究了评论有用性。 过去的研究确实很少提及到文化维度对有用性的影响,这个研究算是全球性评论的研究了,因为我看过的文章都是用来自一个国家的数据集来进行在线评论有用性的研究,所以文化维度这个概念也很难被引入到文章中。也算是引入了一个新的研究视角,从跨地域的视角去研究在线评论有用性,不过这也要求在线评论平台能够将数据展示出来,如果不展示用户的国籍属性就无法进行研究,同时这个平台也要是跨地域全球性的平台,能够吸引不同国家的消费者来这里留下评论信息。
霍夫斯泰德文化维度有:权力距离、不确定性规避、个人主义、英雄主义、长期价值取向、享乐主义。根据文章的结果,除了长期价值取向不显著外,这些维度的程度越高,那么评论的有用性就会越高。文章的自变量除了文化维度,还有就是控制变量,例如长度,星级,极端性等常见的变量。
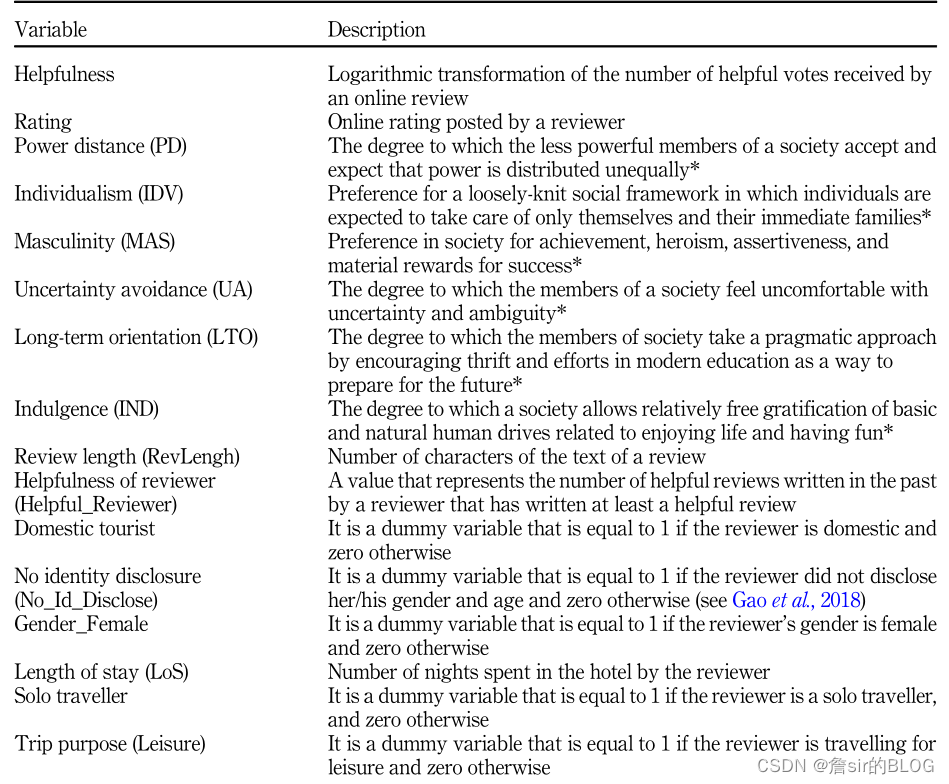
文章也总结了常见的评论有用性的因素框架:

因变量这篇文章用了对数处理后的有用性投票,模型上选择了常见的TOBIT回归模型,最后跑出来的系数都挺漂亮的,支持了文章的假设。
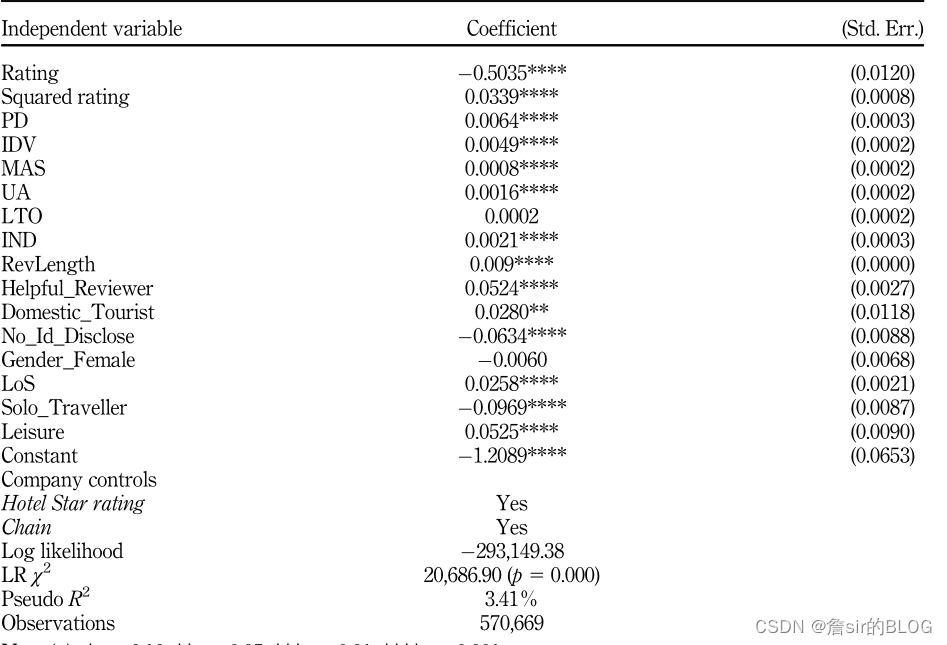
总的来讲,文章的行文思路很清晰,思路也很好,拓宽了研究面,结论也很nice。
40.The influence of emoji meaning multipleness on perceived online review helpfulness: the mediating role of processing fluency(Journal of Business Research)
这篇文章和之前那篇写表情符号的文章撞到一起了,都是研究表情符号对在线评论有用性的影响的,但是这篇文章不是从机器学习或者大数据的视角去研究的,而是采取了传统的问卷调查的方式去做了统计研究,文章相对来说不是很难懂,但是行文思路比较好,结论也很nice。
表情符号传达了是一种非语言的情感传达方式,文章将表情分为了黄脸表情、红脸表情和非人类表情。一个单纯的表情符号可以传达多种含义,在文本中添加表情符号可以帮助读者理解文本,表情符号的多样性对评论有用性带来的效应目前还是未知的。文章提出假设,在中性文本中加入表情符号可以提高阅读者的文本有用性评价,同时基于加工流畅性效应和朴素理论,文章认为评论文本中使用单义表情符号比使用多义表情符号更能提高评论文本的感知有用性,表情符号的多义性会被阅读者的专业知识所调节。
文章首先招募了100多个大学生对表情符号的含义进行投票,例如笑脸符号的主要含义就是funny,这是文章的第一个实验。第二个实验是从问卷星招募了100多个人对评论有用性进行打分,文章选取了18条中性文本让消费者打分,然后选出来四种中性的评价。第三个实验就是在中性文本中加入单义表情符号和多以表情符号,然后让参与者去给文本打分,得出了结论是表情符号很好的提高了评论的有用性,并且提高程度不同。


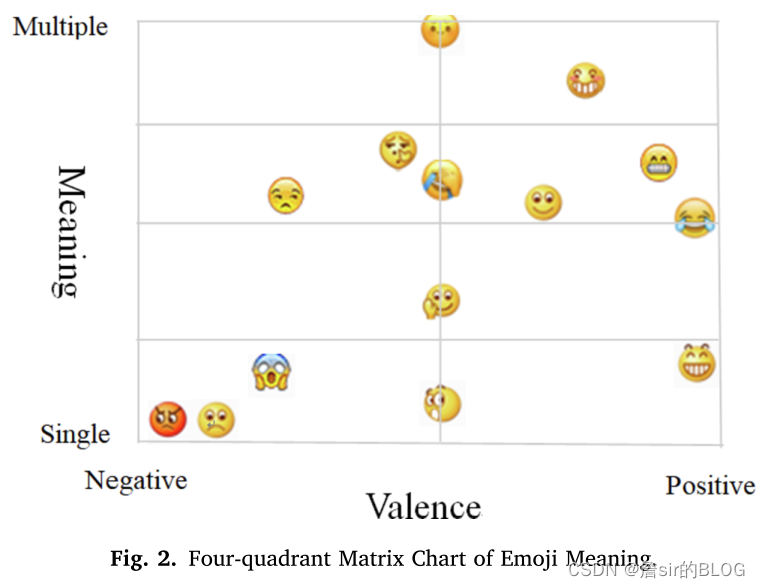
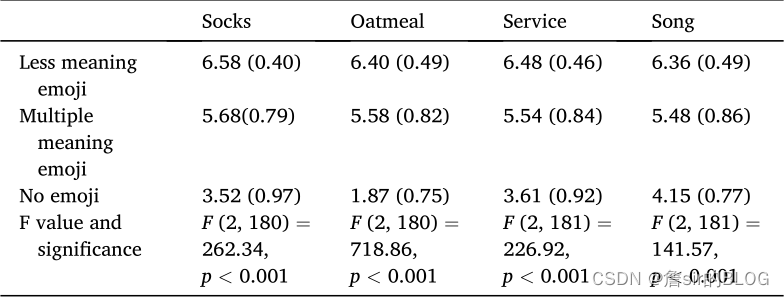
文章的最后一个实验是研究阅读者专业水平的调节效应的,这一部分连个表都没有,看不懂,瑕疵可改进。凑合看图把。

文章总体很简单的,结论也很nice,很适合在综述中引用。















 1571
1571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









