







目录
2.1 基于知识采纳模型和多层感知机神经网络的评论有用性识别研究(中国管理科学)
2.2 消费者认为怎样的在线评论更有用?— —社会性因素的影响效应(管理世界)
2.3 融合 Word2vec 和WGRA的社会化问答社区答案有用性排序方法研究———以携程问答为例(图书情报工作)
2.4 基于模糊 TOPSIS 分析的在线评论有用性排序过滤模型研究———以亚马逊手机评论为例(图书情报工作)
2.5 表情符号多余吗?———表情符号对在线产品评论感知有用性的影响研究(管理工程学报)
2.6 基于领域情感词典的用户生成内容有用性评价研究———以豆瓣读书为例(情报理论与实践)
2.7 在线评论有用性的深度数据挖掘——基于 TripAdvisor 的酒店评论数据(旅游管理)
2.8 融合信息增益和梯度下降算法的在线评论有用程度预测模型(计算机科学)
1 在线评论的行为影响与价值应用研究综述(中国管理科学)
在线评论通常定义为电子商务或者第三方网站上消费者发表的产品评价。主要表现形式为星级打分(1至5颗星)和开放式评论文本。随着社交网络的发展,消费者倾向通过社交媒体分享购物体验,并且在购买之前浏览在线评论。在线评论作为一种新的口碑形式,摆脱传统口碑的社交关系约束。传播 范围广,对消费者行为产生强烈的影响。企业为适应在线评论环境,对市场营销、产品设计等经营决策行为做出调整。
在线评论可以影响消费者的购物决策,进而影响到企业产品的销量,因此也势必会影响企业的经营决策。

产品在线评论的研究有许多方向,本文将研究分为了行为影响与价值应用两大类的研究。在行为影响层面分三个方面:消费者行为层面上,主要研究消费者对于评论的感知有用性(即消费者认为什么样的在线评论是有价值的);在线评论对于购买意愿的影响,许多研究主要应用计量经济学、统计学的方法来进行定性定量的研究;在线评论对于企业经营决策的影响,企业可以根据在线评论中含有的产品信息来进行产品的调整以及产品价格的调整。
在价值应用层面主要有四个方面的研究:在线评论关键信息的提取,分别是产品属性的提取以及对于消费者情感特征的提取;在线评论的推荐服务,在线平台的评论都是依靠有用性投票或者点赞数来对评论进行推荐,最新发布的评论往往没有足够的投票而无法获得推荐,但是新的评论中可能含有对于消费者而言的有用信息,因此需要根据一定的方法对在线评论进行排序和推荐,降低消费者的信息检索成本和阅读成本;面向市场的竞争分析;面向制造业的产品开发,在线评论可以为制造业提供消费者对于产品的效用感知以及产品中可能存在的质量缺陷等等。
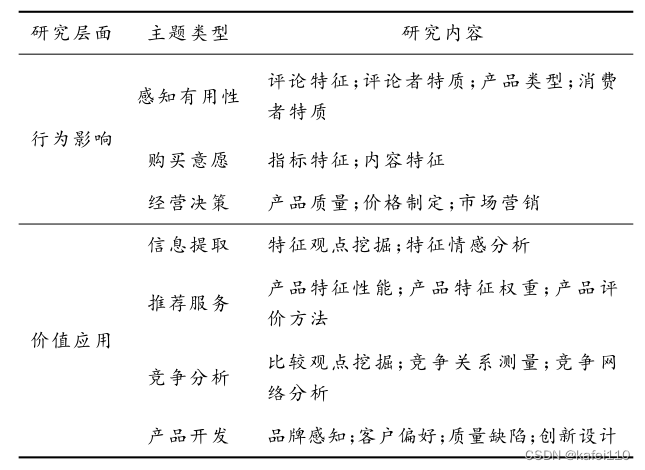
这篇文章较为清晰的展现了在线评论领域的几个研究方向,能够帮助研究者有针对性、有条理性的对在线评论领域进行研究,初次阅读,因此我从评论有用性相关的文献先入手阅读。
2 评论有用性相关的论文
评论有用性识别主要是从评论数据中提取出评论相关的特征,然后构建机器学习模型对参数进行学习;但是机器学习方法需要人工标注数据,比较耗费时间,因此也可以通过排序算法来进行评论的排序,同样可以筛选出有用评论。
2.1 基于知识采纳模型和多层感知机神经网络的评论有用性识别研究(中国管理科学)
这篇文章基于知识采纳模型(KAM)和多层感知机神经网络对评论的有用性进行识别。评论的文本语料主要来源于知乎,总共爬取了9000多条答案文本,题材为中医领域。KAM理论认为感知信息有用性取决于两方面的内容,分别是信息的质量,另一方面是信息来源的可信度。
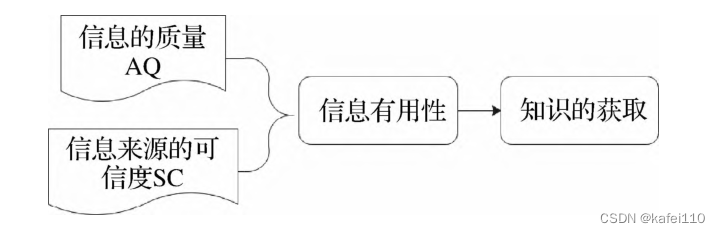
在文本表示上,采用了词袋法进行表示,表示方式较为简单,不能表示词语之间的相近程度。
在构建机器学习自变量特征时,主要从评论数据中抽取以下特征:评论句子数量、停用词占比、领域词占比、评论回复数量、作者粉丝数量、作者获赞数量。在提取出特征之后对所有变量做了归一化的处理,避免变量量纲的影响。
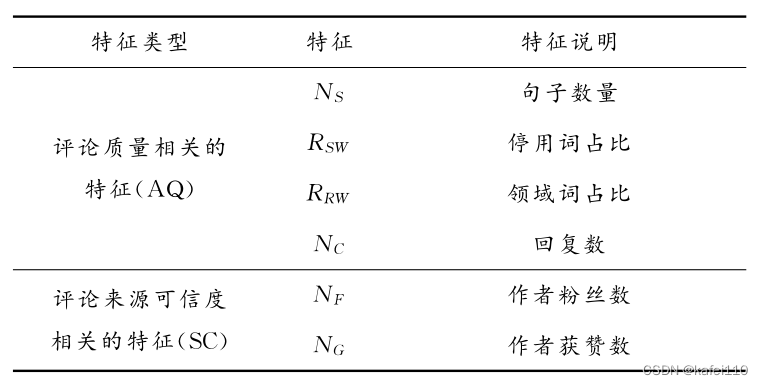
模型的因变量或者标签就是评论是否有用,1表示评论有用,-1表示评论没用,文章根据评论的点赞量自动划分评论是否有用,选择了100条评论并且进行人工验证,提出了最合适的评论划分阈值,然后对所有评论进行划分。但是这种方法的问题就是日期较近的新评论肯定就没办法。 在模型选择上,主要选择了多层神经网络、SVM、NB,并且尝试了不同特征的学习效果,最终得出多层神经网络的数据拟合能力最好。
总体而言,模型的特征选择比较简单,文本表示方法也较为简单,机器学习方面的理论也比较容易懂,但是我感觉有点过于简单了,没有去考虑评论的情感特征,总感觉还有很多方面的内容可以补充。但是这篇文章依然发表在了中国管理科学上。
2.2 消费者认为怎样的在线评论更有用?— —社会性因素的影响效应(管理世界)
这篇文章是在线评论领域高引用的一篇文章,这篇论文实证分析了各种特征对于评论有用性的影响。文章基于启发—系统式模型(Heuristic-Systematic Model,HSM)为分析框架,基于从众效应、社会网络等视角以及一系列社会因素来说明了在线评论如何影响消费者。
HSM模型揭示了消费者在得到信息时,会从两方面考察信息的可靠性,一是直观信息,另一部分是信息来源相关的信息,文章提出在该文章发表之前,关于评论者社会背景的信息研究较少,因此文章中讨论评论有用性时纳入了评论者社会背景信息。
评论有用性的自变量包括评论长度、评论及时性、评论者的网络中心度、评论者的关系多样性、评论者的经验技能、平均星级差异。评论者的网络中心度分为两个维度,分别为内向和外向网络中心度,内向网络中心度可以用评论者的粉丝数来衡量,外向网络中心度可以用评论者关注的人数来衡量,评论者的关系多样性可以用加入的群组数量来衡量,评论者的经验技能用发表的评论数量来衡量。评论有用性的因变量用有用性投票来衡量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









