







文章目录
NIO核心一:缓冲区(Buffer)
概述
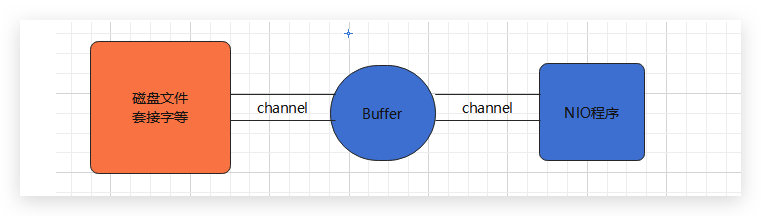
一个用于特定基本数据类型的容器。由 java.nio 包定义的,所有缓冲区 都是 Buffer 抽象类的子类.。Java NIO 中的 Buffer 主要用于与 NIO 通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的。
Buffer 类及其子类
Buffer就像一个数组,可以保存多个相同类型的数据。根据数据类型不同 ,有以下 Buffer 常用子类:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
上述 Buffer类,它们都采用相似的方法进行管理数据,只是各自管理的数据类型不同而已。都是通过如下方法获取一个 Buffer 对象:
static XxxBuffer allocate(int capacity) : 创建一个容量为capacity 的 XxxBuffer 对象
缓冲区的基本属性
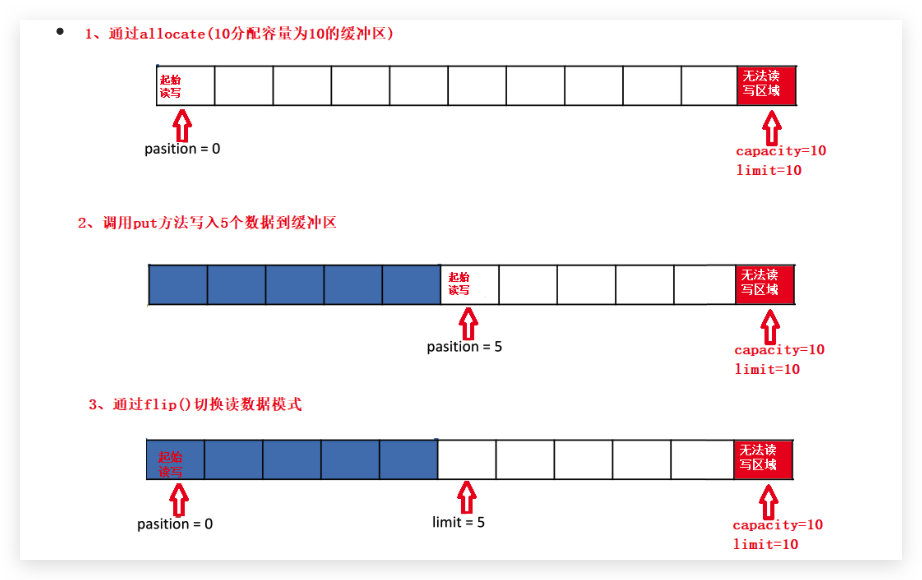
Buffer 中的重要概念:
- 容量 (capacity) :作为一个内存块,Buffer具有一定的固定大小,也称为"容量",缓冲区容量不能为负,并且创建后不能更改。
- 限制 (limit):表示缓冲区中可以操作数据的大小(limit 后数据不能进行读写)。缓冲区的限制不能为负,并且不能大于其容量。 写入模式,限制等于buffer的容量。读取模式下,limit等于写入的数据量。
- 位置 (position):下一个要读取或写入的数据的索引。缓冲区的位置不能为负,并且不能大于其限制。
- 标记 (mark)与重置 (reset):标记是一个索引,通过 Buffer 中的 mark() 方法 指定 Buffer 中一个特定的position,之后可以通过调用 reset() 方法恢复到这 个 position.
标记、位置、限制、容量遵守以下不变式: 0 <= mark <= position <= limit <= capacity
图示:
Buffer常见方法
Buffer clear() 清空缓冲区并返回对缓冲区的引用
Buffer flip() 为 将缓冲区的界限设置为当前位置,并将当前位置充值为 0
int capacity() 返回 Buffer 的 capacity 大小
boolean hasRemaining() 判断缓冲区中是否还有元素
int limit() 返回 Buffer 的界限(limit) 的位置
Buffer limit(int n) 将设置缓冲区界限为 n, 并返回一个具有新 limit 的缓冲区对象
Buffer mark() 对缓冲区设置标记
int position() 返回缓冲区的当前位置 position
Buffer position(int n) 将设置缓冲区的当前位置为 n , 并返回修改后的 Buffer 对象
int remaining() 返回 position 和 limit 之间的元素个数
Buffer reset() 将位置 position 转到以前设置的 mark 所在的位置
Buffer rewind() 将位置设为为 0, 取消设置的 mark
缓冲区的数据操作
Buffer 所有子类提供了两个用于数据操作的方法:get()put() 方法
取获取 Buffer中的数据
get() :读取单个字节
get(byte[] dst):批量读取多个字节到 dst 中
get(int index):读取指定索引位置的字节(不会移动 position)
放到 入数据到 Buffer 中 中
put(byte b):将给定单个字节写入缓冲区的当前位置
put(byte[] src):将 src 中的字节写入缓冲区的当前位置
put(int index, byte b):将指定字节写入缓冲区的索引位置(不会移动 position)
使用Buffer读写数据一般遵循以下四个步骤:
- 1.写入数据到Buffer
- 2.调用flip()方法,转换为读取模式
- 3.从Buffer中读取数据
- 4.调用buffer.clear()方法或者buffer.compact()方法清除缓冲区
直接与非直接缓冲区
根据官方文档的描述:
byte byffer可以是两种类型,一种是基于直接内存(也就是非堆内存);另一种是非直接内存(也就是堆内存)。对于直接内存来说,JVM将会在IO操作上具有更高的性能,因为它直接作用于本地系统的IO操作。而非直接内存,也就是堆内存中的数据,如果要作IO操作,会先从本进程内存复制到直接内存,再利用本地IO处理。
从数据流的角度,非直接内存是下面这样的作用:
本地IO-->直接内存-->非直接内存-->直接内存-->本地IO
而直接内存是:
本地IO-->直接内存-->本地IO
很明显,在做IO处理时,比如网络发送大量数据时,直接内存会具有更高的效率。直接内存使用allocateDirect创建,但是它比申请普通的堆内存需要耗费更高的性能。不过,这部分的数据是在JVM之外的,因此它不会占用应用的内存。所以呢,当你有很大的数据要缓存,并且它的生命周期又很长,那么就比较适合使用直接内存。只是一般来说,如果不是能带来很明显的性能提升,还是推荐直接使用堆内存。字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其 isDirect() 方法来确定。
直接内存使用场景
- 1 有很大的数据需要存储,它的生命周期又很长
- 2 适合频繁的IO操作,比如网络并发场景
NIO核心二:通道(Channel)
概述
通道(Channel):表示 IO 源与目标打开的连接。 Channel 类似于传统的“流”。只不过 Channel 本身不能直接访问数据,Channel 只能与 Buffer 进行交互。
1、 NIO 的通道类似于流,但有些区别如下:
-
通道可以同时进行读写,而流只能读或者只能写
-
通道可以实现异步读写数据
-
通道可以从缓冲读数据,也可以写数据到缓冲:
2、BIO 中的 stream 是单向的,例如 FileInputStream 对象只能进行读取数据的操作,而 NIO 中的通道(Channel)
是双向的,可以读操作,也可以写操作。
常用的Channel实现类
- FileChannel:用于读取、写入、映射和操作文件的通道。
- DatagramChannel:通过 UDP 读写网络中的数据通道。
- SocketChannel:通过 TCP 读写网络中的数据。
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。 【ServerSocketChanne 类似 ServerSocket , SocketChannel 类似 Socket】
FileChannel 类
获取通道的一种方式是对支持通道的对象调用getChannel() 方法。支持通道的类如下:
- FileInputStream
- FileOutputStream
- RandomAccessFile
- DatagramSocket
- Socket
- ServerSocket
获取通道的其他方式是使用 Files 类的静态方法 newByteChannel() 获取字节通道。或者通过通道的静态方法 open() 打开并返回指定通道。
FileChannel的常用方法
int read(ByteBuffer dst) 从 从 Channel 到 中读取数据到 ByteBuffer
long read(ByteBuffer[] dsts) 将 将 Channel 到 中的数据“分散”到 ByteBuffer[]
int write(ByteBuffer src) 将 将 ByteBuffer 到 中的数据写入到 Channel
long write(ByteBuffer[] srcs) 将 将 ByteBuffer[] 到 中的数据“聚集”到 Channel
long position() 返回此通道的文件位置
FileChannel position(long p) 设置此通道的文件位置
long size() 返回此通道的文件的当前大小
FileChannel truncate(long s) 将此通道的文件截取为给定大小
void force(boolean metaData) 强制将所有对此通道的文件更新写入到存储设备中
NIO核心三:选择器(Selector)
概述
Selector 是非阻塞 IO 的核心
Selector用于检测在多个注册的Channel上是否有I/O事件发生,并对检测到的I/O事件进行相应的响应和处理。因此通过一个Selector线程就可以实现对多个Channel的管理。
原理:
一个线程 Thread 使用一个选择器Selector监听多个通道 Channel 上的IO事件,从而让一个线程就可以处理多个IO事件。通过配置监听的通道Channel为非阻塞,那么当Channel上的IO事件还未到达时,线程会在select方法被挂起,让出CPU资源。直到监听到Channel有IO事件发生时,才会进行相应的响应和处理。
Selector能够检测多个注册的通道上是否有IO事件发生(注意:多个 Channel 以事件的方式可以注册到同一个Selector),如果有事件发生,便获取事件然后针对每个事件进行相应的处理。这样就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求。
Selector只有在通道上有真正的IO事件发生时,才会进行相应的处理,这就不必为每个连接都创建一个线程,避免线程资源的浪费和多线程之间的上下文切换导致的开销。
选择器(Selector)的应用
- 创建 Selector :通过调用 Selector.open() 方法创建一个 Selector。
Selector selector = Selector.open();
- 向选择器注册通道:SelectableChannel.register(Selector sel, int ops)
//1. 获取通道
ServerSocketChannel ssChannel = ServerSocketChannel.open();
//2. 切换非阻塞模式
ssChannel.configureBlocking(false);
//3. 绑定连接
ssChannel.bind(new InetSocketAddress(9898));
//4. 获取选择器
Selector selector = Selector.open();
//5. 将通道注册到选择器上, 并且指定“监听接收事件”
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件。
当调用 register(Selector sel, int ops) 将通道注册选择器时,选择器对通道的监听事件,需要通过第二个参数 ops 指定。可以监听的事件类型(用 可使用 SelectionKey 的四个常量 表示):
- 读 : SelectionKey.OP_READ (1)
- 写 : SelectionKey.OP_WRITE (4)
- 连接 : SelectionKey.OP_CONNECT (8)
- 接收 : SelectionKey.OP_ACCEPT (16)
- 若注册时不止监听一个事件,则可以使用“位或”操作符连接。
int interestSet = SelectionKey.OP_READ|SelectionKey.OP_WRITE
- 监听事件
int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
- 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
- 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









