







作者 | MECH
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/616880233
大家好,这里是 NewBeeNLP。
Que2Search是Facebook的经典论文,之前我们详细解读了Que2Search的技术方案和一些个人的思考,感兴趣的同学可以移步观看:
Que2Search:FaceBook新一代query搜索召回模型分享[1]
笔者在OPPO搬砖的时候,在我司搜索广告场景上线了改进版的Que2Search模型,取得了不错的效果。
本文主要分享笔者将Que2Search应用在特定场景的改进措施和绿厂搜索广告中query召回路的设计,看看笔者如何用Facebook这篇“老汤”来煮我司的这盘“新菜”。
1. Que2Search落地初体验
1.1 场景介绍
笔者负责的OPPO搜索广告场景是OPPO手机中的浏览器和应用商店的搜索广告业务,其商业模式为,用户输入query,下拉栏联想页、搜索落地页都会有相应的广告位来推荐app。在该场景下,app就是广告,因此我们的核心业务就是输入一个query,召回一批app。其中联想页场景的产品形态示例如下:
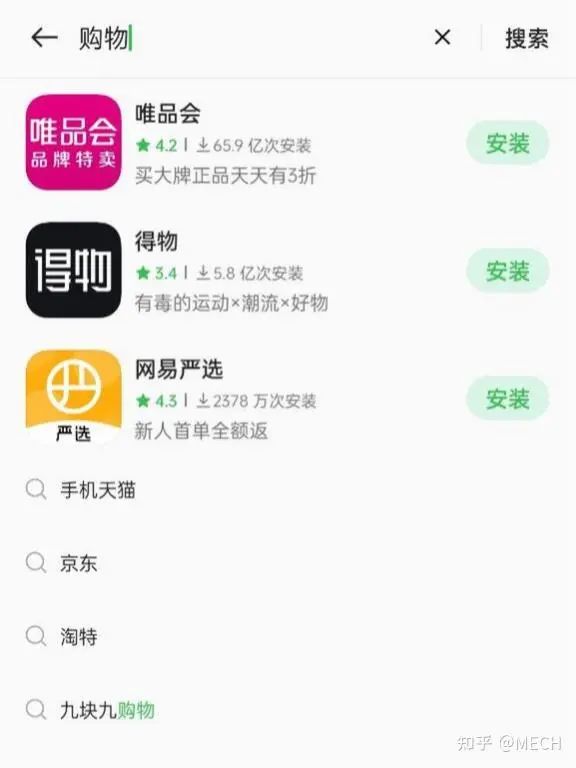
1.2 业务思考
和业界大多数召回架构一样,oppo搜索广告为多路召回的模式,分别由以下几路召回组成:
历史词召回、规则词召回、运营词召回、分类类目召回等策略规则类召回
Query-app模型召回
User-app模型召回
新广告召回
......
多路召回的优点就是多目标分开建模,每一路都有自己的目标和特点,召回也更多需要考虑多目标间的权衡:
历史词召回可以用来记忆住高频模式,规则词可以加入运营和产品的强干预,类目召回可以初步保证query和app之间的类别相关性
query-app模型可以用来进一步提升相关性,优化用户体验
user-app模型可以在用户粒度做到个性化,最大化收益
新广告召回可以扶持新app和冷门app,使其免受缺乏特征和样本之类的冷启动影响
今天要分享的Que2Search模型落地主要是负责在query-app这一路上的优化,目标就是优化query和app间的相关性。
1.3 样本、特征、训练细节
我们先复习下Que2Search特征和样本的设计。忘记的同学请自觉回上篇观看并且三联,靴靴~
1.3.1 Query塔
Query塔侧有query的3-gram list哈希然后sum pooling、query的XLM embedding、还有国家的emedding。
对于笔者来说,该场景仅面向国内,国家的embedding自然不需要了,XLM也自然被替换成了中文Bert。根据经验,英文等字母类语言3-gram特征比较有效,而中文则是2-gram效果比较好。所以Query塔的特征改动为:
去除国家embedding。
XLM换成了中文Bert。
Query 3-gram换成2-gram。
1.3.2 Document塔
原论文使用了商品title的3-gram、商品描述3-gram、商品title XLM embedding、商品描述XLM embedding、商品图片的GrokNet embedding,doc塔还有一个特殊的多标签多分类label。
在笔者的场景下,笔者做出了如下改动:
App的名称和描述都可以用原论文的方式得到相应的特征,只需要将3-gram换成2-gram、XLM换成6层的中文Bert即可。
考虑到app下载场景用户其实是很难从图标或者详情页图片来摄取信息的,因此笔者这里抛弃了多模态的图像特征(绝对不是因为我懒0w0~)
这里也加入了我司固有的一大堆标签类app公共属性特征,如app关键词,app分类体系标签等等,这些都是厂商的优势特征。
Doc塔多标签多分类辅助label选取历史出现过的5w个高频query。
1.3.3 样本的定义和设计
主要目标既然是相关性,那最好的样本设置方式其实就是让人工来标注相关性语料,但这种操作放在哪家公司都是不可能让你这么干的,除非你掏钱(就我那点工资标注人员看了都直摇头T^T,贷款上班的活咱不干)。
因此笔者需要像Que2Search一样设置一种弱监督正样本策略,能让训练集尽可能满足相关性目标。目前笔者使用的方法是在点击数据的基础上卡一个ctr阈值,使大于该阈值的query-app对成为正样本,负样本就用batch内负采样的方式来获取。
1.3.4 其他训练、评估部分细节
Embedding间的融合使用的Attention Fusion。
Bert的学习率是模型整体学习率的1/3。
训练也是先easy后hard的两阶段课程学习模式。
离线指标是recall@K和auc,并且也让人工标注了一批评估集,观察这部分数据的auc(离线相关性)。线上看ctr(注意:线上ctr指标和离线相关性指标存在gap,二者之间在迭代初期正相关,越相关ctr越高。而越到迭代后期二者相关关系慢慢减弱,最后甚至相悖,所以在、离线两个指标都要看)。
1.4 出现的问题
初版的Que2Search离线评估效果recall指标比baseline低5个百分点。笔者在上线Que2Search前曾经上线过一个base版本模型,该base模型正样本策略和本文一样,负样本在app库中随机采样的,但模型使用的是一个非常浅层的sentence-bert,并且特征也只有query和app名称。
Que2Search在引入了如此多特征的情况下居然还比不过base模型,有点让人惊讶,于是乎笔者通过分析数据和模型部分结构的表现,发现了如下几个问题:
Doc侧多标签分类label由于热门效应影响,导致很多app没有辅助label类别,只有缺省类别。
错误query形形色色,笔者曾经在《Query改写模块的设计和上线部署优化[2]》这篇文章中提到,由于手机输入方式的多样性,导致用户的query会出现千奇百怪的错别字,query塔侧严重依赖query信息的前提下,影响很大。
数据热门效应严重,观察模型召回的数据来看,模型很容易将不相关但热门的app排到前面。观察数据也发现其实用户下载app和query好像确实没啥相关性,明明搜的A结果下载的却是B,而且B大概率是热门app,这种情况在数据里很常见。
SSB(Sample Selection Bias)问题比较严重,由于本身的正样本策略是有偏的,很多冷门app都很没有成为正样本的机会,自然也直接失去了成为负样本的机会,模型也从来没见过这些app。
False negative现象严重,越热门的query,出现false negative的可能性就越大,关于false negative的问题介绍请移步这篇文章的开头导语部分:《推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案[3]》。
2. Que2Search在OPPO搜索广告场景下的优化措施
针对上面分析出的问题现象,笔者做出了对应的优化和改进。
2.1 删除doc塔侧分类任务
上面我们提到了,doc侧多分类label由于热门效应导致很多app只有缺省类别。而热门app却有非常多的类别,并且由于label处的数值= 非个数 ,因此虽然label多,但是每个label的值却低,形成了一个非常困难的样本分布不均衡、label太小难预估的尴尬场景。
所以,笔者在这里分析后删除了这个多分类任务,将这些app的历史点击query作为特征加入到app侧,辅助理解app内容,这样就减弱了缺省类别过多带来的直接影响。
2.2 加入query改写
上面的问题中提到了,query输入混乱难以理解,但观察数据就不难发现其实大部分query是完全可以归一在一起的,只不过由于输入方式和输入习惯的不同,导致其衍生除了千奇百怪的query,从而影响模型理解该query。针对这个问题,笔者在query塔侧加入了一个新特征:改写后的rewrite query,和原始query共享一个Bert。
具体的改写方式和算法选型,请移步笔者的这篇文章观看:
Query改写模块的设计和上线部署优化[4]
2.3 降低热门效应 & 缓解SSB问题
Batch内负彩阳热门打压在业界其实很少有人做,因为batch内负采样热门app更有可能成为负样本,因此其具备天然打压热门item的属性,而且通常会造成过度打压。但是本文中广告场景的某些app热门效应非常显著,自带的热门打压效果似乎难以hold住。笔者清楚 这是正样本策略带来的负面影响 ,但是我们又不能用人力去标注,也暂时没有更好的正样本策略改进方式 。因此这里只能考虑从模型侧入手进一步打压热门app。
笔者采取的方案是针对性挑选如下的app,将其当做少量额外负样本加入到训练的正样本中:
热门效应严重到影响模型效果的app
在正样本中没出现的app
额外负样本加入训练集后,loss虽然还是batch softmax, 但训练集并不只是正样本了,有0有1 ,那么计算batch softmax的叉乘矩阵过程如下:
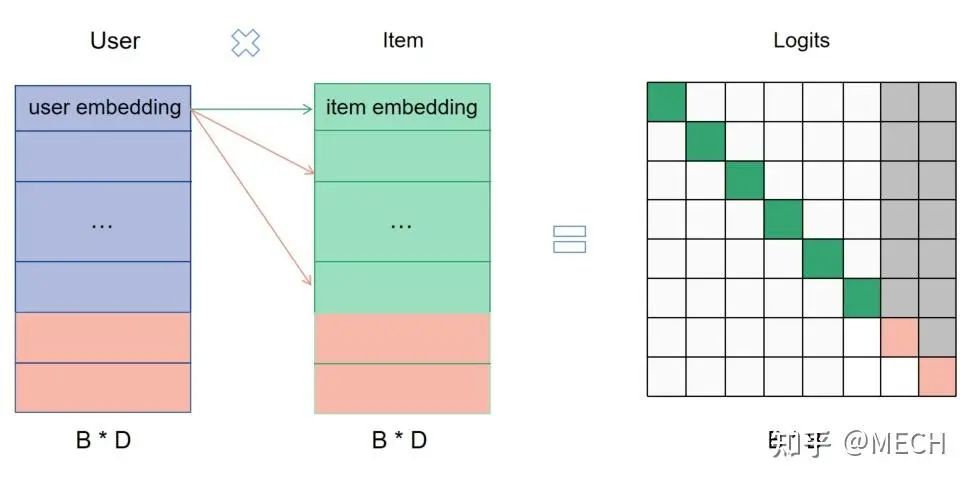
灰色的部分即为额外加入的负样本,这样对于原来每一行样本来说,绿色的正样本多增加了两条灰色的负样本 ,相当于变相的给其他query增加了更多的item作为负样本,这时候热门的额外负样本的加入,相当于在进一步打压热门,而冷门样本的加入,缓解了SSB问题,一箭双雕。
当然有同学会问,这样不就让冷门app更难展现了吗?其实没关系,本文开头就有说过,一般召回系统都有专门的冷门扶持召回。冷门之所以是冷门就是很少有准确的query来搜索并且点击它,因此我们更需要避免模型在面临一个没见过的query时将一个不相关的冷门app排在前面(因为SSB问题,模型没见过该app,embedding表达很差)。
这里要注意的是,上图中额外负样本所在这一行的loss是不能使用的,因为这一行根本没有正样本,也就失去了物理意义,会对模型产生干扰,因此我们需要将粉色样本所在行的loss抹掉。
算法的详细细节原理、以及其代码实现笔者这里就不展开了,之前的文章里都有。感兴趣的同学请移步笔者的这篇文章:
双塔模型Batch内负采样如何解决热度降权和SSB的问题[5]
2.4 False negative的问题缓解
笔者曾在《推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案》一文中详细阐述过针对false negative问题解决方案的探索,里面提到了两种优化的方法,二者的大致思想分别为:
GSHM loss:大名鼎鼎的GHM loss在分类问题中可以做到对简单样本和困难样本loss权重的打压,我们通常认为false negative是错误样本,难以优化,通过数据观察发现这部分数据的梯度密度也非常大,可以利用GHM loss对false negative样本的loss进行打压。笔者对其略作改进,消除其对简单样本的loss打压,保留对困难样本的打压,从而到达只降低false negative影响的目的。
SPC loss:在batch softmax中将每条样本的错误负样本找出来,并将其softmax值加和至正阳本的softmax中。
这里只讲下核心思想,如想详细了解,请移步:
推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案[6]
2.5 单独挖掘hard negative的加入
除了第二阶段的batch内挖掘困难负样本之外,我们又增加了一个第三阶段的辅助loss,一个目的是我们有很多hard negative数据不用很可惜,第二个问题还是觉得batch内挖掘困难负样本的方式受数据分布影响太大。
第三阶段样本为正负样本对的形式,正样本仍然是一样的策略,负样本为专门用pipline挖掘的困难负样本,依旧是用课程学习的方式,用cosent loss来训练,尝试过bce,效果也还行,这里的挖掘困难负样本的策略可以非常灵活:
可以是上个版本召回排序靠后的app
也可以是精排排序靠后的app
也可以是部分曝光未点击样本(尤其是 above曝光未点击 ,即在用户点击页面中,展示在用户点击app之前的未点击app)
到此为止,我们针对query-app这一路的初始目标的优化已经做完了,这其中每一步优化措施都对最终的线上目标指标有一定幅度的提升,完成了这一路应有的使命。
2.6 砌墙后又拆墙:引入多目标来提升ecpm/arpu
我们前面所有的优化措施,都是在让模型推荐的更准。但我们发现当模型推荐准以后,query-app这一路的线上ctr确实是比其他路高很多的,但是随之而来的是ecpm/arpu这种收入指标并没有上涨,反而有所下降。
观察这一路的线上报表数据发现,该路实际扣费单价低。那么这个问题其实很好理解了,搜索广告虽然名为搜索,但始终是广告场景,而非内容搜索那样需要精准推荐,对于收入这个指标来说,ctr * bid 就是实际扣费,然而不同app之间的出价bid有可能差百倍,纯广告收益场景如果始终精准的推荐用户的需求,精准推荐出的app的bid或许就不那么高,那么ecpm大概率就没办法很高了。
基于对这一点的认识,我们开始重新规划这一路的目标,并不能让其只满足于高ctr或者相关性, 而是在原有基础上损失较小相关性的前提下,尽可能推荐出高价值(高bid)的app 。对于这个优化点,其实笔者已经记录在了之前的一篇文章里,本文仅做思考点分享,详细细节大家可以移步下面这篇文章:Query改写模块的设计和上线部署优化[7]
2.7 减轻热门打压程度进一步提升ecpm
熟悉笔者的朋友知道,笔者一直强调看搜广推的论文不要只看模型、trick、策略,更重要是看论文作者需要拿它来解决什么问题(以及你是否存在这个问题),如果同样的trick没用在合适的地方上会适得其反。
前面进行热门打压的目的是为了准确,为了相关性。当这一路目标夹杂进收入指标时,我们不期望对热门的app进行过度的打压,这时候放松热门打压程度能进一步提升线上ecpm,相当于要制造和第二目标相近的bias。可以认为这两个目标在优化到一定程度后有一定的冲突,此消彼长。
对于这个现象,百度凤巢的这篇文章:《Sample Optimization For Display Advertising》中详细论证了各种负样本热门打压策略的实验,我们实验的结论和百度凤巢结论基本一致。因为作者是做的在线实验,写的很详细,很有说服力,所以这里就分享下百度的实验结果。首先介绍其实验的样本采样策略,方便等会和图片中的策略对应:
Base策略,常规思路,负样本大盘随机负采样,一个广告成为负样本的概率正比于其曝光占比,可以理解为均匀分布。
策略(a):对base生产的负样本生成的概率进行了修改,由base的均匀分布变成了unigram分布,使其相对于base来说,高频item成为负样本的概率相对降低。相当虽然仍然存在热门打压,但是对高频的打压幅度降低。
策略(b):对base生产出的负样本进行随机采样删除,广告出现的频次越高,删除的概率越大,相当于减小了热门样本成为负样本的概率,也是将高频的打压幅度降低。
策略(c):PU学习的样本细化,将负样本中的潜在正样本识别出并剔除掉,这条策略和本文的论点无关,感兴趣的同学可以阅读原文。但这些潜在负样本也大概率是热门样本,所以也一定程度上是对将高频的打压幅度降低。
策略(d):模糊正样本增强,为缓解正样本稀疏的问题,这里采用一种模糊逻辑来扩充正样本,该策略和本文的论点无关,可忽略,感兴趣的同学可以阅读原文。
策略(e):带噪声对比估计的采样,对比学习,用NCE模型生成负样本,用这种方法扩大负样本集,同样该策略和本文的论点无关,可忽略,感兴趣的同学可以阅读原文。
百度的实验结论如下,本文这里只关注实验a、b、c的效果,逐步增加a、b、c后发现线上ecpm逐步提升,但离线auc逐步下降:
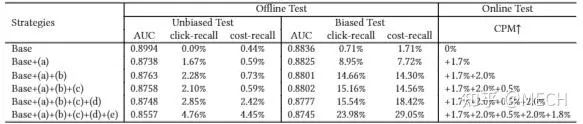
实验结果说明了,放松热门打压可以进一步提升线上收入指标。这也应证了笔者所强调的,看论文的时候需要将论文中作者要解决的问题弄明白,思考清楚那些问题是不是你要解决的?如果设计一个搜广推系统时上来就无脑的进行热门打压,结果说不定和目标背道而驰,落得个南辕北辙的下场,结合目标需求和业务理解对症下药才是上策。
3. 总结
可以看到,这篇文章中分享的优化措施,正好可以串联起笔者之前写的几篇文章:
MECH:Query改写模块的设计和上线部署优化[7]
MECH:双塔模型Batch内负采样如何解决热度降权和SSB的问题[8]
MECH:推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案[9]
MECH:推荐模型如何在不影响排序指标的前提下,让高价值的item排序前移?[10]
这些文章也是笔者在迭代模型时的业务思考和脉络记录,可能未必适合所有业务,仅做抛砖引玉,欢迎各位大佬指正讨论。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
Que2Search:FaceBook新一代query搜索召回模型分享: https://zhuanlan.zhihu.com/p/615284379
[2]Query改写模块的设计和上线部署优化: https://zhuanlan.zhihu.com/p/615244161
[3]推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案: https://zhuanlan.zhihu.com/p/613206891
[4]Query改写模块的设计和上线部署优化: https://zhuanlan.zhihu.com/p/615244161
[5]双塔模型Batch内负采样如何解决热度降权和SSB的问题: https://zhuanlan.zhihu.com/p/574752588
[6]推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案: https://zhuanlan.zhihu.com/p/613206891
[7]MECH:Query改写模块的设计和上线部署优化: https://zhuanlan.zhihu.com/p/615244161
[8]MECH:双塔模型Batch内负采样如何解决热度降权和SSB的问题: https://zhuanlan.zhihu.com/p/574752588
[9]MECH:推荐系统召回模型batch内负采样训练时出现false negative问题的一些解决方案: https://zhuanlan.zhihu.com/p/613206891
[10]MECH:推荐模型如何在不影响排序指标的前提下,让高价值的item排序前移?: https://zhuanlan.zhihu.com/p/600369259


















 1704
1704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









