









atomic引入背景
对于 SMP 系统中,在开启 preempt 情况下,对于公共资源,如果存在两个 task 来进行更改,这就面临临界区资源竞争问题,此时会产生意想不到的结果,这是不符合预期的,因此需要来进行解决。
典型问题描述
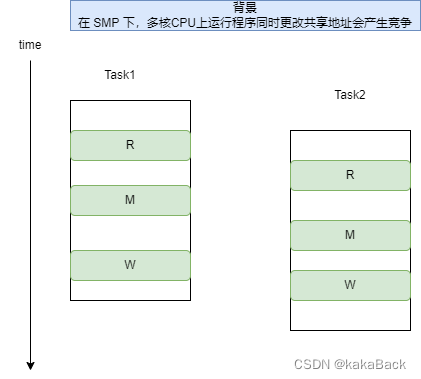
对于变量的操作: a =0; a++; 汇编是如下实现:
ldr r3, [r3, #0]
adds r2, r3, #1
str r2, [r3, #0] 也就是说,一个 a++ 实际上需要三条指令来完成,分别对应上图的 R,M,W。
这样如果 task1 在W之后,紧接着task2 也来W, 此时会产生不符合 task1 预想的结果,会产生问题。因此 arm 提出 atomic 来解决这种问题。
atomic 实现
arm32 实现
/* arch/arm/include/asm/atomic.h */
#undef ATOMIC_OPS
#define ATOMIC_OPS(op, c_op, asm_op) \
ATOMIC_OP(op, c_op, asm_op) \
ATOMIC_FETCH_OP(op, c_op, asm_op)
#define ATOMIC_OP(op, c_op, asm_op) \
static inline void atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
prefetchw(&v->counter); \
__asm__ __volatile__("@ atomic_" #op "\n" \
"1: ldrex %0, [%3]\n" \ ①
" " #asm_op " %0, %0, %4\n" \ ②
" strex %1, %0, [%3]\n" \ ③
" teq %1, #0\n" \ ④
" bne 1b" \ ⑤
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
} \
ATOMIC_OPS(add, +=, add) 这里选取了 atomic_add 来分析,上面的 #asm_op 就是 add 了,此时代码可以解析为:
- Prefetch data
- ①将v->counter所在地址的数据加载到 result
- ② result += i, 结果存放在 result 中
- ③将result 保存到 v->counter 所在地址,同时结果保存在 tmp
- ④检查 tmp 和 0 比较,如果不等于0需要重新处理一遍⑤
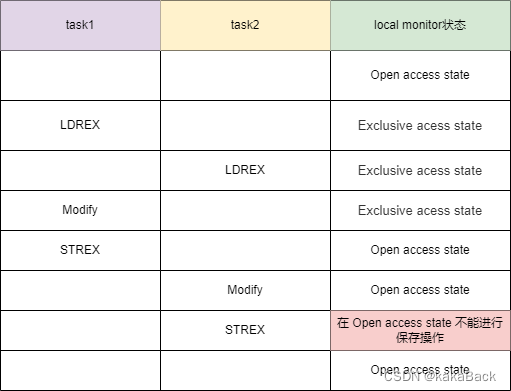
那么为什么仅仅使用了 ldrex 和 strex 就实现了 atomic 功能呢?
实际上 ldrex 和 strex 在使用过程中使用了 monitor 的功能,这里选取蜗窝科技的介绍方式介绍:
arm64实现
/* arch/arm64/include/asm/atomic_lse.h */
#define ATOMIC64_OP(op, asm_op) \
static inline void __lse_atomic64_##op(s64 i, atomic64_t *v) \
{ \
asm volatile( \
__LSE_PREAMBLE \
" " #asm_op " %[i], %[v]\n" \
: [i] "+r" (i), [v] "+Q" (v->counter) \
: "r" (v)); \
}
ATOMIC64_OP(andnot, stclr)
ATOMIC64_OP(or, stset)
ATOMIC64_OP(xor, steor)
ATOMIC64_OP(add, stadd) // 定义了 __lse_atomic64_add 函数, asm_op 是 stadd
/* arch/arm64/include/asm/lse.h */
#define __lse_ll_sc_body(op, ...) \
({ \
system_uses_lse_atomics() ? \
__lse_##op(__VA_ARGS__) : \
__ll_sc_##op(__VA_ARGS__); \
})
/* arch/arm64/include/asm/atomic.h */
#define ATOMIC64_OP(op) \
static __always_inline void arch_##op(long i, atomic64_t *v) \
{ \
__lse_ll_sc_body(op, i, v); \
}
ATOMIC64_OP(atomic64_andnot)
ATOMIC64_OP(atomic64_or)
ATOMIC64_OP(atomic64_xor)
ATOMIC64_OP(atomic64_add) //这里传入的 op 是 atomic64_add, 定义了 arch_atomic64_add
ATOMIC64_OP(atomic64_and)
ATOMIC64_OP(atomic64_sub)对于 arch_atomic64_add ,其又调用了 __lse_ll_sc_body(atomic64_add, i, v);
这样 atomic64_add 就有了定义:
/* lib/atomic64.c */
#define ATOMIC64_OPS(op, c_op) \
ATOMIC64_OP(op, c_op) \
ATOMIC64_OP_RETURN(op, c_op) \
ATOMIC64_FETCH_OP(op, c_op)
ATOMIC64_OPS(add, +=)
ATOMIC64_OPS(sub, -=)这里才真正使用 宏来声明了 atomic64_add 函数,它通过 stladd 将 i 加到 atomic64_add 的变量中的 counter 上面去。stladd 是 armv8.1 提供了原子操作变量,相对于 ldrex, strex 在性能又进一步提升。
atomic典型使用
atomic_t val;
atomic_set(&val, 10);
int read_val = atomic_read(&val);per_cpu 引入背景

对于 outer-shareable 的内存而言,由于cache MESI 机制(假设是outer shareable 的),会发生如下变化:
- 假设原始的 CPU cache情况如下:
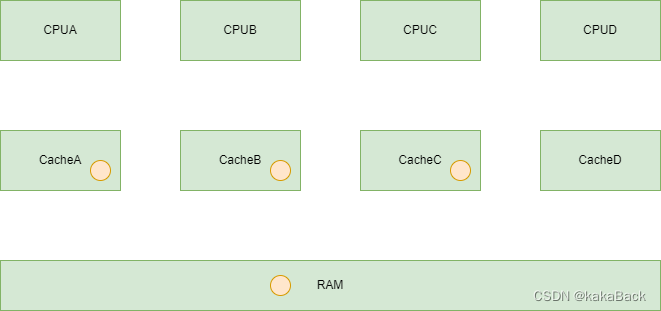
图中黄色的小球是 Cache 是否命中,且和 RAM 中内容一致
2.更改 CacheB 中内容

此时CacheB 内容被修改,内容发生变化。
3.Invalidate 其它cpu cache
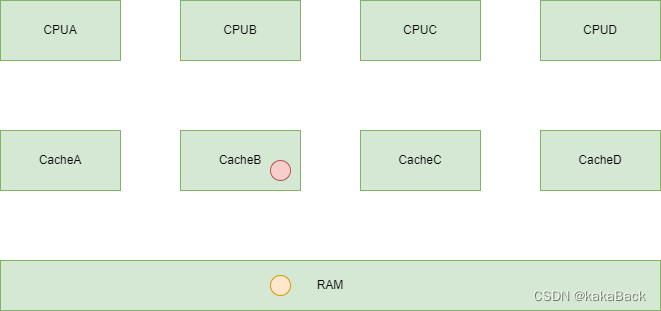
因为MESI 机制,因为B更改了,此时会自动 invalidate outer shareable 的 cache 内容。
这样会带来性能上的损耗,因为被invalidate 的内容,之后如果用到,还要重新加载。
假入内容有这样的一块内存,属于CPU自己独有,它的加载以及Cache 操作不会影响到别的CPU,这样就解决了上述面临的问题。因此linux中提出 per_cpu 变量来操作。
per_cpu 变量定义
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
PER_CPU_ATTRIBUTES
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) __typeof__(type) name
#endif
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")定义一个位于 PER_CPU_BASE_SECTION 的一个变量,这是一个静态声明,指定了其位于的地址空间。其section 定义如下:
#ifndef PER_CPU_BASE_SECTION
#ifdef CONFIG_SMP
#define PER_CPU_BASE_SECTION ".data..percpu"
#else
#define PER_CPU_BASE_SECTION ".data"
#endif#ifdef MODULE
#define PER_CPU_SHARED_ALIGNED_SECTION ""
#define PER_CPU_ALIGNED_SECTION ""
#else
#define PER_CPU_SHARED_ALIGNED_SECTION "..shared_aligned"
#define PER_CPU_ALIGNED_SECTION "..shared_aligned"
#endif
#define DEFINE_PER_CPU_SHARED_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, PER_CPU_SHARED_ALIGNED_SECTION) \
____cacheline_aligned_in_smp
#define DEFINE_PER_CPU_PAGE_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "..page_aligned") \
__aligned(PAGE_SIZE)分别也是定义了位于 section name 为 "..page_aligned" 和 "..shared_aligned" 的变量。
那么为什么需要特殊的 Section呢?
对于kernel中的普通变量,经过了编译和链接后,会被放置到.data或者.bss段,系统在初始化的时候会准备好一切(例如clear bss),由于per cpu变量的特殊性,内核将这些变量放置到了其他的section,位于kernel address space中__per_cpu_start和__per_cpu_end之间,我们称之Per-CPU变量的原始变量。(参考蜗窝科技).
典型应用
DEFINE_PER_CPU(int, state);
int cpu = 0;
per_cpu(state, cpu) = 1;
int got_state = per_cpu(state, cpu);














 6488
6488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









