







前言
人脸最基础的操作之一,是要将人脸识别出来后,把真个人脸给抠出来,这样就可以对人脸进行各种操作,比如:美白、去痘等等,本篇是基于人脸识别库,结合阈值分割图片的mask操作以及一些两个图片的叠加操作,实现了给人脸叠加上京剧脸谱的效果:
原图如下(由AI生成不涉及肖像权):

经过处理如下:

原理
本篇处理的流程思路如下:
Step1、首先利用face_recognition库对人脸进行识别,并识别出人物的下部脸轮廓,并利用opencv的多边形绘制工具polylines,绘制出人物脸部的下半部轮廓,由于识别库没有提供上半部轮廓的识别功能,暂时用opencv的矩形绘制工具rectangle,把人脸的上半部以矩形表示,总体形成一个mask:

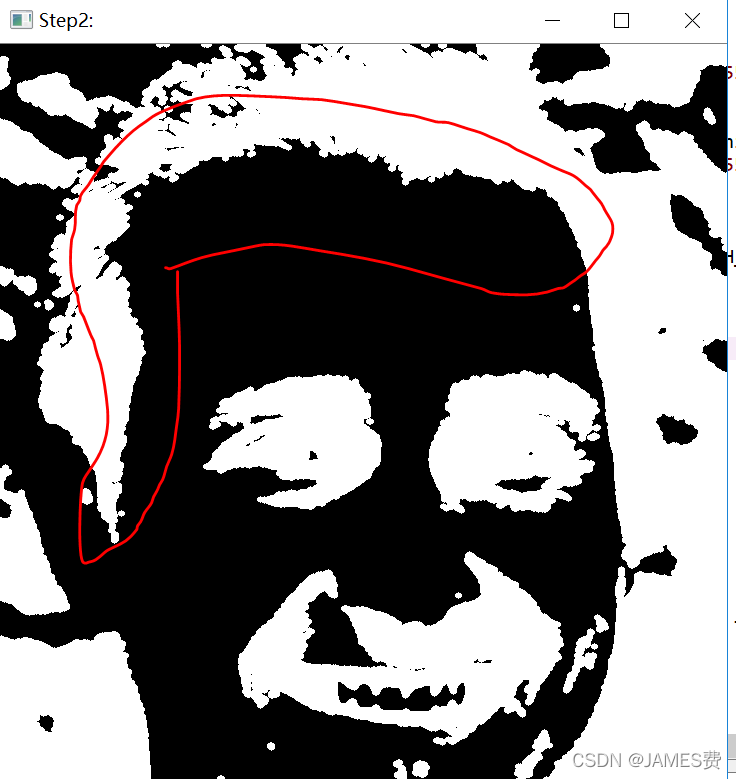
Step2、那么接下来,就是要将人脸的上半部分轮廓给找出来,这样就可以找到整个脸的轮廓,这里用的方法是通过简单的阈值分割,对人脸原图进行阈值分割,并进行形态学的膨胀操作,这样可以把发际线给简单找出来(如下图标红部分):
Step3:接下来,利用以上两步找到的mask信息,对准备好的京剧脸谱图像进行运算,结果是把原图中的人脸多余部分给去除掉,剩下匹配人脸的部分:

Step4:接下来,就是跟上几节原理一样,把具有alpha通道的png脸谱图(可以通过ps做出来),通过眼睛和嘴巴的定位,较为准确地放到人脸上面,我这里眼睛比较对位了,但是鼻子还需要优化一下。通过一个规则逻辑进行绘制(线性叠加):
合成地像素点值=人脸原图像素*(1-alpha值)+alpha值*((1-人脸mask值)脸谱像素+人脸mask值人脸原图像素)
对应源代码中的:
for c in range(0,3):
backimg[y1:y2, x1:x2, c] = (alpha_huzijbackimg[y1:y2,x1:x2,c]) + (alpha_huzip((maskalbackimg[y1:y2,x1:x2,c]) + mask3[y1:y2,x1:x2]((1-ddratio)backimg[y1:y2,x1:x2,c]+ddratio(mask[:usy,:usx,c]))))
结束
PS:后续需要优化,现在看起来不是很自然,可以通过边缘的模糊,纹理的叠加,以及一些变形的操作,把脸谱与人脸做到更加精细的叠加。
Python源代码
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 23 17:13:28 2022
@author: JAMES FEI
Copyright (C) 2022 FEI PANFENG, All rights reserved.
THIS SOFTEWARE, INCLUDING DOCUMENTATION,IS PROTECTED BY COPYRIGHT CONTROLLED
BY FEI PANFENG ALL RIGHTS ARE RESERVED.
"""
import face_recognition
import cv2
import numpy as np
import time
video_capture = cv2.VideoCapture(0)
def threshold(inputimg,midthreshold=127,maxthreshold=255,binarymod=cv2.THRESH_BINARY):
img=inputimg
if len(img.shape)==3:
# 将图片转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
retval, output = cv2.threshold(img,midthreshold, maxthreshold, binarymod)
#print(output.shape)
return output
process_this_frame = True
#载入胡子,带透明通道
maskk = cv2.imread('mask.png', cv2.IMREAD_UNCHANGED)
def putonmask(mask,backimg,mask3,dilated,eyeline,noseline,me=140,ne=126,lefteye=(162,258),leftcenter=(50,50)):
height=mask.shape[0]
width=mask.shape[1]
ratiow=eyeline/140
ratioh=noseline/126
print("mask shape",mask.shape,ratiow,ratioh)
mask = cv2.resize(mask,(int(width*ratiow),int(height*ratioh)),interpolation=cv2.INTER_LINEAR)
lefteye_mask=(int(lefteye[0]*(eyeline/140)),int(lefteye[1]*(noseline/126)))
(x1,y1)=(leftcenter[0]-lefteye_mask[0],leftcenter[1]-lefteye_mask[1])
x2 = x1 + mask.shape[1]
y2 = y1 + mask.shape[0]
usy=mask.shape[0]
usx=mask.shape[1]
if x2>backimg.shape[1]:
x2=backimg.shape[1]
usx=backimg.shape[1]-x1
if y2>backimg.shape[0]:
y2=backimg.shape[0]
usy=backimg.shape[0]-y1
if backimg.shape[2] == 3:
b, g, r = cv2.split(backimg)
alpha = np.ones(b.shape, dtype=b.dtype) * 255 # 创建Alpha通道
backimg = cv2.merge((b, g, r, alpha))
alpha_huzip = mask[:usy,:usx,3] / 255.0
#print("shapmask,mask3",alpha_huzip.shape,mask3[y1:y2, x1:x2].shape)
#alpha_huzip=alpha_huzip
mask[:usy,:usx,:3] = cv2.bitwise_and(mask[:usy,:usx,:3], mask[:usy,:usx,:3], mask = mask3[y1:y2, x1:x2])
#(1-mask3[y1:y2, x1:x2])*backimg[y1:y2,x1:x2,c]
for cc in range(3):
mask[:usy,:usx,cc]=mask[:usy,:usx,cc]*(1-dilated[y1:y2, x1:x2])+backimg[y1:y2,x1:x2,cc]*dilated[y1:y2, x1:x2]
cv2.imshow("step3:",mask[:usy,:usx,:3])
alpha_huzij = 1 - alpha_huzip
some=0
for i in range(y2-y1):
for j in range(x2-x1):
if mask3[i,j]!=0 or mask3[i,j]!=1:
if mask3[i,j]>0.5:
mask3[i,j]=1
else:
mask3[i,j]=0
print("0,1:",some)
maskal=1-mask3[y1:y2,x1:x2]
ddratio=0.5
for c in range(0,3):
backimg[y1:y2, x1:x2, c] = (alpha_huzij*backimg[y1:y2,x1:x2,c]) + (alpha_huzip*((maskal*backimg[y1:y2,x1:x2,c]) + mask3[y1:y2,x1:x2]*((1-ddratio)*backimg[y1:y2,x1:x2,c]+ddratio*(mask[:usy,:usx,c]))))
#backimg[y1:y2, x1:x2, c] = ((maskal*backimg[y1:y2,x1:x2,c]) + mask3[y1:y2,x1:x2]*((1-ddratio)*backimg[y1:y2,x1:x2,c]+ddratio*(mask[:usy,:usx,c])))
#cv2.imshow('moni33tor', backimg[:,:,:3])
return backimg[:,:,:3]
iscap=False
orang=cv2.imread('avatar1.png')
while True:
# 读取摄像头画面
if iscap:
ret, frame = video_capture.read()
else:
frame=orang.copy()
# 改变摄像头图像的大小,图像小,所做的计算就少
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# opencv的图像是BGR格式的,而我们需要是的RGB格式的,因此需要进行一个转换。
rgb_small_frame = small_frame[:, :, ::-1]
# Only process every other frame of video to save time
if process_this_frame:
# 根据encoding来判断是不是同一个人,是就输出true,不是为flase
face_landmarks_list = face_recognition.face_landmarks(rgb_small_frame)
for face_landmarks in face_landmarks_list:
#打印此图像中每个面部特征的位置
facial_features = [
'chin',
'left_eyebrow',
'right_eyebrow',
'nose_bridge',
'nose_tip',
'left_eye',
'right_eye',
'top_lip',
'bottom_lip'
]
#创建脸部遮罩
mask1=np.zeros(frame.shape,np.uint8)
#下脸部
epoints=[]
highestchin_y=10000
leftchin_x=0
rightchin_x=10000
for point in face_landmarks["chin"]:
epoints.append([point[0]*4,point[1]*4])
if highestchin_y>point[1]*4:
highestchin_y=point[1]*4
if leftchin_x<point[0]*4:
leftchin_x=point[0]*4
if rightchin_x>point[0]*4:
rightchin_x=point[0]*4
cv2.polylines(mask1, [np.array(epoints)], isClosed=True, color=[255, 255, 255], thickness=1)
cv2.fillPoly(mask1, [np.array(epoints)], color=[255, 255, 255])
uppoints=[[leftchin_x,highestchin_y],[rightchin_x,highestchin_y-10],[rightchin_x,0],[leftchin_x,0]]
cv2.rectangle(mask1, (leftchin_x,0),(rightchin_x,highestchin_y+10), (255, 255, 255), -1)
cv2.imshow("Step1:mask1",mask1)
maskup=threshold(frame,midthreshold=88,maxthreshold=255,binarymod=cv2.THRESH_BINARY_INV)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7,7))
dilated = cv2.dilate(maskup.copy(), kernel, 10)
cv2.imshow("Step2:",dilated)
lef_center_x=0
lef_center_y=0
epoints=[]
for point in face_landmarks["left_eye"]:
epoints.append([point[0]*4,point[1]*4])
cv2.polylines(mask1, [np.array(epoints)], isClosed=True, color=[0, 0, 255], thickness=5)
cv2.fillPoly(mask1, [np.array(epoints)], color=[0, 0, 0])
rig_center_x=0
rig_center_y=0
epoints=[]
for point in face_landmarks["right_eye"]:
epoints.append([point[0]*4,point[1]*4])
cv2.polylines(mask1, [np.array(epoints)], isClosed=True, color=[0, 0, 255], thickness=5)
cv2.fillPoly(mask1, [np.array(epoints)], color=[0, 0, 0])
top_lip_x=0
top_lip_y=0
epoints=[]
for point in face_landmarks["top_lip"]:
top_lip_x+=point[0]*4
top_lip_y+=point[1]*4
epoints.append([point[0]*4,point[1]*4])
top_lip_x= int(top_lip_x/len(face_landmarks["top_lip"]))
top_lip_y= int(top_lip_y/len(face_landmarks["top_lip"]))
cv2.polylines(mask1, [np.array(epoints)], isClosed=True, color=[0, 0, 0], thickness=1)
cv2.fillPoly(mask1, [np.array(epoints)], color=[0, 0, 0])
epoints=[]
for point in face_landmarks["bottom_lip"]:
epoints.append([point[0]*4,point[1]*4])
cv2.polylines(mask1, [np.array(epoints)], isClosed=True, color=[0, 0, 0], thickness=1)
cv2.fillPoly(mask1, [np.array(epoints)], color=[0, 0, 0])
maskgray = cv2.cvtColor(mask1,cv2.COLOR_BGR2GRAY)
ret,mask = cv2.threshold(maskgray,175,255,cv2.THRESH_BINARY)
lef_center_x=0
lef_center_y=0
for point in face_landmarks["left_eye"]:
lef_center_x+=point[0]*4
lef_center_y+=point[1]*4
lef_center_x=int(lef_center_x/len(face_landmarks["left_eye"]))
lef_center_y=int(lef_center_y/len(face_landmarks["left_eye"]))
rig_center_x=0
rig_center_y=0
for point in face_landmarks["right_eye"]:
rig_center_x+=point[0]*4
rig_center_y+=point[1]*4
rig_center_x=int(rig_center_x/len(face_landmarks["left_eye"]))
rig_center_y=int(rig_center_y/len(face_landmarks["left_eye"]))
dilated[highestchin_y:,:]=0
cv2.circle(dilated, (lef_center_x,lef_center_y), 105, 0, -1)
cv2.circle(dilated, (rig_center_x,rig_center_y), 105, 0, -1)
for i in range(dilated.shape[0]):
for j in range(dilated.shape[1]):
if dilated[i,j]>0.5:
dilated[i,j]=1
else:
dilated[i,j]=0
cv2.imshow("d",dilated)
#去掉眼睛和嘴唇
nosey=0
for point in face_landmarks["nose_tip"]:
if nosey<point[1]*4:
nosey=point[1]*4
print("nosey",nosey,nosey-lef_center_y)
output1=putonmask(maskk,frame,mask,dilated,(rig_center_x-lef_center_x),(nosey-lef_center_y),leftcenter=(lef_center_x,lef_center_y))
cv2.imshow('monitor', output1)
time.sleep(0.1)
# 按Q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
代码用到的原图如下:




















 2593
2593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











