







学习笔记,迁移学习的模型加载
模型加载方法一 微调convnet
加载预训练的模型并重置最终的完全连接层。
加载模型方法简介
该方法是pytorch官网上找到的,链接: link.
可以直接翻阅官网,此处记录一下自己的一些学习心得。
代码如下
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
首先利用model_ft定义函数,然后直接调用预训练好的函数models.resnet18(pretrained=True),其中resnet就是现成的模型,然后(pretrained=True),就是预训练好的模型,当其=false时,就是只用模型不用训练好的参数(应该是这样的)
然后是num_ftrs = model_ft.fc.in_features获取全连接层数,然后利用nn.Linear(num_ftrs, len)函数将其线性回归到你所需要的种类数,len就是分类的种类数,按照需求填写数量即可(为了方便可以在程序开头定义一个变量,然后改变该变量值即可)。
程序中model_ft.to(device)的用法
model_ft.to(device)是决定利用GPU还是CPU的语句,之前定义device为device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu"),这样就可以利用GPU进行加速。
程序中nn.CrossEntropyLoss的用法
该函数CrossEntropyLoss是交叉熵损失函数,类似于信息论里面的熵,具体计算方法在这两个链接里介绍的比较详细: link.
link.
在这里简单的将其中的一个例子记录一下:
假设N=3,期望输出为p=(1,0,0),实际输出q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1),那么:
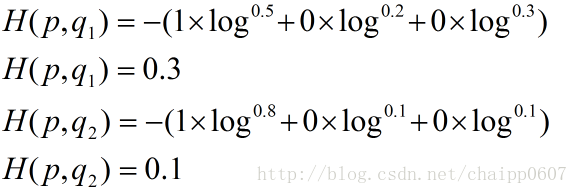
很显然,q2与p更为接近,它的交叉熵也更小。
除此之外,交叉熵还有另一种表达形式,还是使用上面的假设条件:
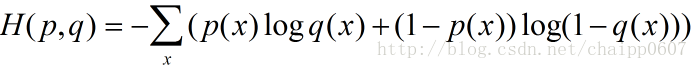
其结果为:
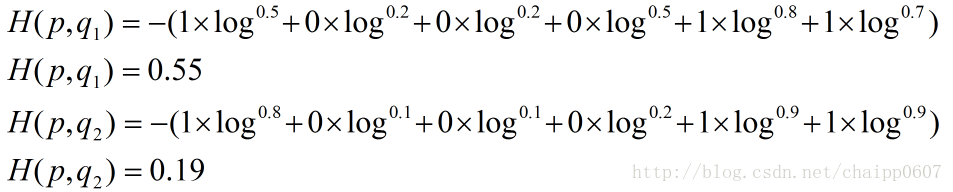
以上的所有说明针对的都是单个样例的情况,而在实际的使用训练过程中,数据往往是组合成为一个batch来使用,所以对用的神经网络的输出应该是一个m*n的二维矩阵,其中m为batch的个数,n为分类数目,而对应的Label也是一个二维矩阵,还是拿上面的数据,组合成一个batch=2的矩阵:
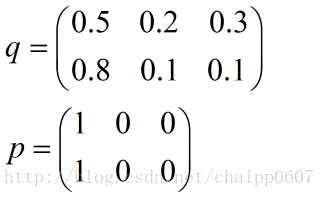
所以交叉熵的结果应该是一个列向量(根据第一种方法):
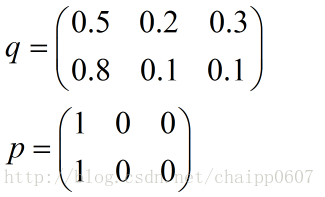
而对于一个batch,最后取平均为0.2。
程序中optim.SGD的用法
SGD即随机梯度下降算法,具体计算过程见链接: link.
在此只记录参数的用法链接: link.
(也可参考pytorch中文手册链接: link.)
class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)
参数:
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (float) – 学习率
- momentum (float, 可选) – 动量因子(默认:0)
- weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认:0)
- dampening (float, 可选) – 动量的抑制因子(默认:0)
- nesterov (bool, 可选) – 使用Nesterov动量(默认:False)
程序中lr_scheduler.StepLR的用法
有的时候需要我们通过一定机制来调整学习率,这个时候可以借助于torch.optim.lr_scheduler类来进行调整
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- step_size(int):每训练step_size个epoch,更新一次参数;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个
epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
模型加载方法二 ConvNet作为固定特征提取器
在这里,我们需要冻结除最后一层之外的所有网络。我们需要设置冻结参数,以免在中计算梯度。requires_grad == Falsebackward()
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
与第一中方法的差别在于其将 param.requires_grad 设置为了False
将其冻结。其余与第一种方法一致。
总结
采用该方法的步骤简单来说就是获取全连接层数,线性回归到需要的类别数,然后定义不同的损失函数和优化算法即可。














 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









