机器学习分类学习器性能测试
1. 数据部分
- 从文件中读取数据
- 特征为马的某些医院检测的指标
- 标签为是否属于疝气病症
- 在本次测试中只选取了部分特征
- list格式数据
2. 学习器部分
- K-近邻居算法
- 决策树
- 朴素贝叶斯
- Logistic回归
- 支持向量机
- 集成学习
choiceModel = 'ALL'
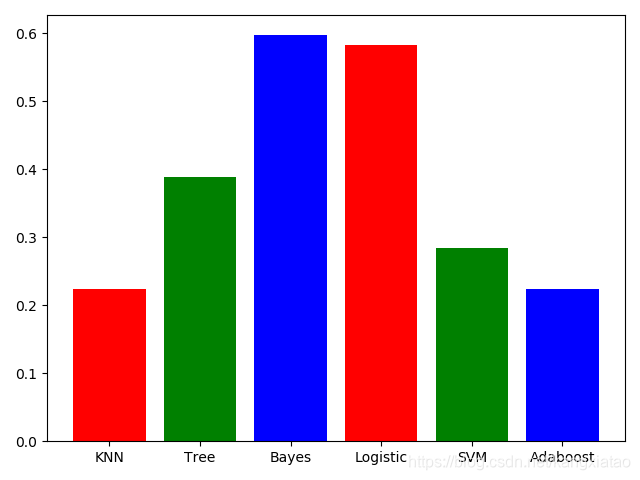
3. 结果
- 学习器对于分类的错误率
4. 全部代码
- 所有分类器算法都是机器学习实战中文版这本书上的代码
- 训练集和数据集是
horseColicTraining2.txt和horseColicTest2.txt
import kNN
import trees, treePlotter
import bayes
import logRegres
import svmMLiA
import adaboost
from numpy import *
import copy
import matplotlib.pyplot as plt
import random
'''
从文件中读取数据
特征为马的某些医院检测的指标
标签为是否属于疝气病症
在本次测试中只选取了部分特征
list格式
'''
frTrain = open('horseColicTraining2.txt')
frTest = open('horseColicTest2.txt')
trainingSet = []
trainingLabels = []
testingSet = []
testingLabels = []
featureLabels = []
featureNum = 20
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(featureNum):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
for line in frTest.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(featureNum):
lineArr.append(float(currLine[i]))
testingSet.append(lineArr)
testingLabels.append(float(currLine[21]))
for i in range(featureNum):
featureLabels.append('%d' % i)
trainLen = len(trainingLabels)
testLen = len(testingLabels)
print('trainLen:', trainLen)
print('testLen:', testLen)
choiceModel = 'ALL'
errorRateKNN = 0.0
errorRateTree = 0.0
errorRateBayes = 0.0
errorRateLogistic = 0.0
errorRateSVM = 0.0
errorRateAdaboost = 0.0
if choiceModel == 'KNN' or choiceModel == 'ALL':
print("----- kNN -----")
normTrain, ranges0, minVals0 = kNN.autoNorm(array(trainingSet))
normTest, ranges1, minVals1 = kNN.autoNorm(array(testingSet))
errorCount = 0.0
numTestVecs = testLen
for i in range(numTestVecs):
classifierResult = kNN.classify0(normTest[i], normTrain, trainingLabels, 10)
if (classifierResult != testingLabels[i]): errorCount += 1.0
errorRateKNN = errorCount / float(numTestVecs)
print("\nkNN error rate is: %f" % errorRateKNN, "\nerrorCount: ", errorCount)
if choiceModel == 'Tree' or choiceModel == 'ALL':
print("----- Tree -----")
dataSet = copy.deepcopy(trainingSet)
for i in range(trainLen):
dataSet[i].append(trainingLabels[i])
shan = trees.calcShannonEnt(dataSet)
print("香农熵:", shan)
mytree = trees.createTree(dataSet, featureLabels)
numTestVecs = testLen
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = trees.classify(mytree, featureLabels, testingSet[i])
if (classifierResult != testingLabels[i]): errorCount += 1.0
errorRateTree = errorCount / float(numTestVecs)
print("\nTree error rate is: %f" % errorRateTree, "\nerrorCount: ", errorCount)
if choiceModel == 'Bayes' or choiceModel == 'ALL':
print("----- Bayes -----")
myList = bayes.createVocabList(trainingSet)
trainMat = []
for pl in trainingSet:
trainMat.append(bayes.setOfWords2Vec(myList, pl))
p0V, p1V, pAb = bayes.trainNB0(trainMat, trainingLabels)
numTestVecs = testLen
errorCount = 0.0
for i in range(numTestVecs):
thisTesting = array(bayes.setOfWords2Vec(myList, testingSet[i]))
classifierResult = bayes.classifyNB(thisTesting, p0V, p1V, pAb)
if classifierResult == 0:
classifierResult = -1
if (classifierResult != testingLabels[i]): errorCount += 1.0
errorRateBayes = errorCount / float(numTestVecs)
print("\nBayes error rate is: %f" % errorRateBayes, "\nerrorCount: ", errorCount)
if choiceModel == 'Logistic' or choiceModel == 'ALL':
print("----- Logistic -----")
trainWeights = logRegres.stocGradAscent1(array(trainingSet), trainingLabels, 500)
numTestVecs = testLen
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = logRegres.classifyVector(array(testingSet[i]), trainWeights)
if classifierResult == 0.0:
classifierResult = -1.0
if (classifierResult != testingLabels[i]): errorCount += 1.0
errorRateLogistic = errorCount / float(numTestVecs)
print("\nLogistic error rate is: %f" % errorRateLogistic, "\nerrorCount: ", errorCount)
if choiceModel == 'SVM' or choiceModel == 'ALL':
print("----- SVM -----")
k1 = 1.3
b, alphas = svmMLiA.smoP(trainingSet, trainingLabels, 200, 0.0001, 5000, ('rbf', k1))
datMat = mat(trainingSet)
labelMat = mat(trainingLabels).transpose()
svInd = nonzero(alphas.A > 0)[0]
sVs = datMat[svInd]
labelSV = labelMat[svInd]
m, n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = svmMLiA.kernelTrans(sVs, datMat[i, :], ('rbf', k1))
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
if sign(predict) != sign(trainingLabels[i]): errorCount += 1
print("SVM: the training error rate is: %f" % (float(errorCount) / m))
errorCount = 0
datMat = mat(testingSet)
labelMat = mat(testingLabels).transpose()
m, n = shape(datMat)
for i in range(m):
kernelEval = svmMLiA.kernelTrans(sVs, datMat[i, :], ('rbf', k1))
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
if sign(predict) != sign(testingLabels[i]): errorCount += 1
errorRateSVM = (float(errorCount) / m)
print("\nSVM error rate is: %f" % errorRateSVM, "\nerrorCount: ", errorCount)
if choiceModel == 'Adaboost' or choiceModel == 'ALL':
print("----- Adaboost -----")
classiA, aggClass = adaboost.adaBoostTrainDS(trainingSet, trainingLabels, 20)
prediction = adaboost.adaClassify(testingSet, classiA)
err = mat(ones((testLen, 1)))
errorCount = (err[prediction != mat(testingLabels).T].sum())
errorRateAdaboost = (float(errorCount) / testLen)
print("\nAdaboost error rate is: %f" % errorRateAdaboost, "\nerrorCount: ", errorCount)
def randomcolor():
colorArr = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']
color = ""
for i in range(6):
color += colorArr[random.randint(0,14)]
return "#"+color
if choiceModel == 'ALL':
name_list = ['KNN', 'Tree', 'Bayes', 'Logistic', 'SVM', 'Adaboost']
num_list = [errorRateKNN, errorRateTree, errorRateBayes, errorRateLogistic, errorRateSVM, errorRateAdaboost]
plt.bar(range(len(num_list)), num_list, color='rgb', tick_label=name_list)
plt.show()























 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









