






目录
介绍
在机器翻译中,输入的序列与输出的序列经常是长度不相等的序列,此时,像自然语言处理这种直接使用循环神经网络或是门控循环单元的方法就行不通了。因此,我们引入一个新的结构,称之为“编码器-解码器”(Encoder-Decoder),通过这种结构,来实现输入输出长度不均等的问题。
在这一节内容,只介绍这一结构的总体架构,不进行具体实践。
组成结构
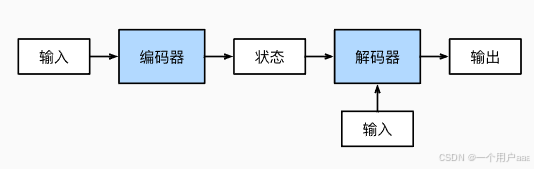
如图所示,本结构主要由一个编码器和一个解码器组成,首先输入源字符串序列,通过编码器进行编码,输出一个状态。随后,解码器对状态进行解码,根据状态进行输出,输出结果即为翻译所得目标语言字符串。解码的这个过程还需要其他输入,比如源字符串序列的有效长度(valid_length)。
代码实现
编码器和解码器的代码都由抽象类进行实现。
编码器
编码器类的前向计算为抽象方法,返回NotImplementedError。具体使用时需要重写该方法。
from mxnet.gluon import nn
class Encoder(nn.Block):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError解码器
解码器有前向计算和状态两个抽象函数。init_state()用于将编码器的输出(enc_outputs)转换为编码后的状态。*args表明其可能需要额外的输入,这有可能是输入序列的有效长度(valid_length)。
class Decoder(nn.Block):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError合并编码器-解码器
显然,还是一个抽象类,只不过将前两个代码给合并了。
总而言之,“编码器-解码器”架构包含了一个编码器和一个解码器, 并且还拥有可选的额外的参数。 在前向传播中,编码器的输出用于生成编码状态, 这个状态又被解码器作为其输入的一部分。
#@save
class EncoderDecoder(nn.Block):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)思考
-
假设我们使用神经网络来实现“编码器-解码器”架构,那么编码器和解码器必须是同一类型的神经网络吗?
-
除了机器翻译,还有其它可以适用于”编码器-解码器“架构的应用吗?















 9491
9491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









